题目
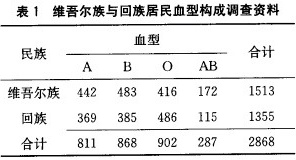
单项选择题维吾尔族与回族居民血型构成资料见表1,问两民族血型分布是否相同,可选用的最适当检验方法是表1 维吾尔族与回族居民血型构成调查资料-|||-血型-|||-民族 合计-|||-A B AB-|||-维吾尔族 442 483 416 172 1513-|||-回族 369 385 486 115 1355-|||-合计 811 868 902 287 2868A、χ表1 维吾尔族与回族居民血型构成调查资料-|||-血型-|||-民族 合计-|||-A B AB-|||-维吾尔族 442 483 416 172 1513-|||-回族 369 385 486 115 1355-|||-合计 811 868 902 287 2868检验B、u检验C、校正χ表1 维吾尔族与回族居民血型构成调查资料-|||-血型-|||-民族 合计-|||-A B AB-|||-维吾尔族 442 483 416 172 1513-|||-回族 369 385 486 115 1355-|||-合计 811 868 902 287 2868检验D、直接计算概率法E、秩和检验
- 单项选择题维吾尔族与回族居民血型构成资料见表1,问两民族血型分布是否相同,可选用的最适当检验方法是
A、χ
 检验
检验B、u检验
C、校正χ
检验D、直接计算概率法
E、秩和检验
题目解答
答案
解析
步骤 1:确定问题类型
问题要求比较两个民族(维吾尔族与回族)的血型分布是否相同。这是一个关于两个独立样本的分类数据的比较问题,适合使用卡方(χ²)检验来解决。
步骤 2:选择合适的检验方法
卡方检验(χ²检验)用于检验两个或多个分类变量之间是否存在显著性差异。在本题中,我们有两个民族的血型分布数据,需要检验这两个民族的血型分布是否相同。因此,χ²检验是合适的选择。
步骤 3:排除其他检验方法
- u检验通常用于比较两个独立样本的均值,不适用于分类数据。
- 校正χ²检验通常用于小样本情况,本题样本量较大,不需要校正。
- 直接计算概率法通常用于小样本或特定情况,本题样本量较大,不适用。
- 秩和检验用于非参数检验,不适用于分类数据的比较。
问题要求比较两个民族(维吾尔族与回族)的血型分布是否相同。这是一个关于两个独立样本的分类数据的比较问题,适合使用卡方(χ²)检验来解决。
步骤 2:选择合适的检验方法
卡方检验(χ²检验)用于检验两个或多个分类变量之间是否存在显著性差异。在本题中,我们有两个民族的血型分布数据,需要检验这两个民族的血型分布是否相同。因此,χ²检验是合适的选择。
步骤 3:排除其他检验方法
- u检验通常用于比较两个独立样本的均值,不适用于分类数据。
- 校正χ²检验通常用于小样本情况,本题样本量较大,不需要校正。
- 直接计算概率法通常用于小样本或特定情况,本题样本量较大,不适用。
- 秩和检验用于非参数检验,不适用于分类数据的比较。