一个估计某行业ECO薪水的回归模型如下其中,salary 为年薪sales为公司的销售收入,mktval为公司的市值,profmarg为利润占销售额的百分比,ceoten为其就任当前公司CEO的年数,comten为其在该公司的年数。一个有177个样本数据集的估计得到R2=0.353。若添加ceoten2和comten2后,R2=0.375。问:此模型中是否有函数设定的偏误?解答:若添加ceoten2和comten2后,估计的模型为如果6、7是统计上显著不为零的,则有理由认为模型设定[1]是有偏误的。而这一点可以通过第三章介绍的受约束F检验来完成:在10%的显著性水平[2]下,自由度[3]为(2,)的F分布的临界值为2.30;在5%的显著性水平下,临界值为3.0。由此可知在10%的显著性水平下拒绝6=7=0的假设,表明原模型有设定偏误问题;而在5%的显著性水平下则不拒绝6=7=0的假设,表明原模型没有设定偏误问题。5-2.在建立计量经济模型时,什么时候、为什么要引入虚拟变量?答:在现实经济生活中,除了诸如:利润、成本、收入、价格等具有数量特征、影响某个经济问题的变量外,还有一类变量,如:季节、民族、自然灾害、战争、政府制定的某项经济政策等也会影响某些经济问题且可能是重要的影响因素,如:讨论改革前后的经济发展的对比,讨论像空调、冷饮等季节性产品的销售,讨论女性化妆品的销售等问题时,不可避免的要考虑后一类变量。这后一类变量所反映的并不是数量而是某种性质或属性,我们前面所讨论的回归模型是一种定量模型,所以在引入这类反映性质或属性的变量时需要先将其定量化。在计量经济学中,我们把这些反映性质或属性的变量叫“虚拟变量”。规定具备某种属性时把虚拟变量赋值为“1”,反之为“0”。5-3.举例说明虚拟变量在模型中的作用。答:以调查某地区居民性别与收入之间的关系为例(设解释变量[4]中只含有虚拟变量),我们可以用模型表示:其中代表收入,为虚拟变量,可以看出, 代表女性的收入,代表男性与女性收入之间的差额,从式很容易得出:检验假设,就是检验男女的平均收入之间是否有差额。若:成立,说明收入与性别没有明显关系。若不成立,说明收入与性别有明关系。5-4.什么是“虚拟变量陷阱”?答:以季节性产品冷饮的销量为例说明。假设销售函数模型为:其中表示销量,表示决定销量的解释变量;已知除定量解释变量的影响外,还受春、夏、秋、冬四季的影响,为把季节变化对销量的影响反映到模型中,如果我们引入4个虚拟变量:这样销售函数的季节回归模型为:4个虚拟变量之间具有关系:,出现完全多重共线性问题,使OLS法不能使用,这就称为“虚拟变量陷阱”。为克服这一问题,一般在引入虚拟变量时要求如果有m个定性变量,只在模型中引入m-1个虚拟变量。5-5.对包含常数项的季节变量模型运用最小二乘法时,如果模型中引入4个季节虚拟变量,其估计结果会出现什么问题?答:对包含常数项的季节变量模型运用OLS法时,如果模型中引入4个季节虚拟变量,会造成完全多重共线性,则参数估计量不存在;其次,即便是一般共线性,使用OLS法参数估计量非有效;参数估计量经济含义不合理;变量的显著性检验失去意义;模型的预测功能失效。5-9.试在消费函数中(以加法形式)引入虚拟变量,用以反映季节因素(淡、旺季)和收入层次差异(高、中、低)对消费需求的影响,并写出各类消费函数的具体形式。答:在消费函数中以加法形式引入虚拟变量,用以反映季节因素(淡、旺)和收入层次差异(高、中、低)对消费需求的影响,形如下式: 其中:,5-19.如果一个定性变量含有个类别,为什么不能设个虚拟变量?⏺答:如果一个定性变量含有个类别,一般只能设个虚拟变量,以避免多重共线。⏺⏺(1)为接受过N年教育的员工的总体平均起始薪金。当N为零时,平均薪金为,因此表示没有接受过教育员工的平均起始薪金。是每单位N变化所引起的E的变化,即表示每多接受一年学校教育所对应的薪金增加值。(2)OLS估计量和仍满足线性性、无偏性及有效性,因为这些性质的的成立无需随机扰动项的正态分布假设。(3)如果的分布未知,则所有的假设检验都是无效的。因为t检验与F检验是建立在的正态分布假设之上的。例6.对于人均存款与人均收入之间的关系式使用美国36年的年度数据得如下估计模型,括号内为标准差: =0.538 (1)的经济解释是什么?(2)和的符号是什么?为什么?实际的符号与你的直觉一致吗?如果有冲突的话,你可以给出可能的原因吗?(3)对于拟合优度你有什么看法吗?(4)检验是否每一个回归系数都与零显著不同(在1%水平下)。同时对零假设和备择假设、检验统计值、其分布和自由度以及拒绝零假设的标准进行陈述。你的结论是什么?解答:(1)为收入的边际储蓄倾向,表示人均收入每增加1美元时人均储蓄的预期平均变化量。(2)由于收入为零时,家庭仍会有支出,可预期零收入时的平均储蓄为负,因此符号应为负。储蓄是收入的一部分,且会随着收入的增加而增加,因此预期的符号为正。实际的回归式中,的符号为正,与预期的一致。但截距项为负,与预期不符。这可能与由于模型的错误设定形造成的。如家庭的人口数可能影响家庭的储蓄形为,省略该变量将对截距项的估计产生影响;另一种可能就是线性设定可能不正确。(3)拟合优度刻画解释变量对被解释变量变化的解释能力。模型中53.8%的拟合优度,表明收入的变化可以解释储蓄中53.8 %的变动。(4)检验单个参数采用t检验,零假设为参数为零,备择假设为参数不为零。双变量情形下在零假设下t 分布的自由度为n-2=36-2=34。由t分布表知,双侧1%下的临界值位于2.750与2.704之间。斜率项计算的t值为0.067/0.011=6.09,截距项计算的t值为384.105/151.105=2.54。可见斜率项计算的t 值大于临界值,截距项小于临界值,因此拒绝斜率项为零的假设,但不拒绝截距项为零的假设。2-22.假设王先生估计消费函数(用模型表示),并获得下列结果:,n=19(3.1) (18.7) R2=0.98 这里括号里的数字表示相应参数的T比率值。要求:(1)利用T比率值检验假设:b=0(取显著水平为5%);(2)确定参数估计量的标准方差;(3)构造b的95%的置信区间,这个区间包括0吗?
一个估计某行业ECO薪水的回归模型如下
其中,salary 为年薪sales为公司的销售收入,mktval为公司的市值,profmarg为利润占销售额的百分比,ceoten为其就任当前公司CEO的年数,comten为其在该公司的年数。一个有177个样本数据集的估计得到R2=0.353。若添加ceoten2和comten2后,R2=0.375。问:此模型中是否有函数设定的偏误?
解答:
若添加ceoten2和comten2后,估计的模型为
如果6、7是统计上显著不为零的,则有理由认为模型设定[1]是有偏误的。而这一点可以通过第三章介绍的受约束F检验来完成:
在10%的显著性水平[2]下,自由度[3]为(2,)的F分布的临界值为2.30;在5%的显著性水平下,临界值为3.0。由此可知在10%的显著性水平下拒绝6=7=0的假设,表明原模型有设定偏误问题;而在5%的显著性水平下则不拒绝6=7=0的假设,表明原模型没有设定偏误问题。
5-2.在建立计量经济模型时,什么时候、为什么要引入虚拟变量?
答:在现实经济生活中,除了诸如:利润、成本、收入、价格等具有数量特征、影响某个经济问题的变量外,还有一类变量,如:季节、民族、自然灾害、战争、政府制定的某项经济政策等也会影响某些经济问题且可能是重要的影响因素,如:讨论改革前后的经济发展的对比,讨论像空调、冷饮等季节性产品的销售,讨论女性化妆品的销售等问题时,不可避免的要考虑后一类变量。这后一类变量所反映的并不是数量而是某种性质或属性,我们前面所讨论的回归模型是一种定量模型,所以在引入这类反映性质或属性的变量时需要先将其定量化。在计量经济学中,我们把这些反映性质或属性的变量叫“虚拟变量”。规定具备某种属性时把虚拟变量赋值为“1”,反之为“0”。
5-3.举例说明虚拟变量在模型中的作用。
答:以调查某地区居民性别与收入之间的关系为例(设解释变量[4]中只含有虚拟变量),我们可以用模型表示:
其中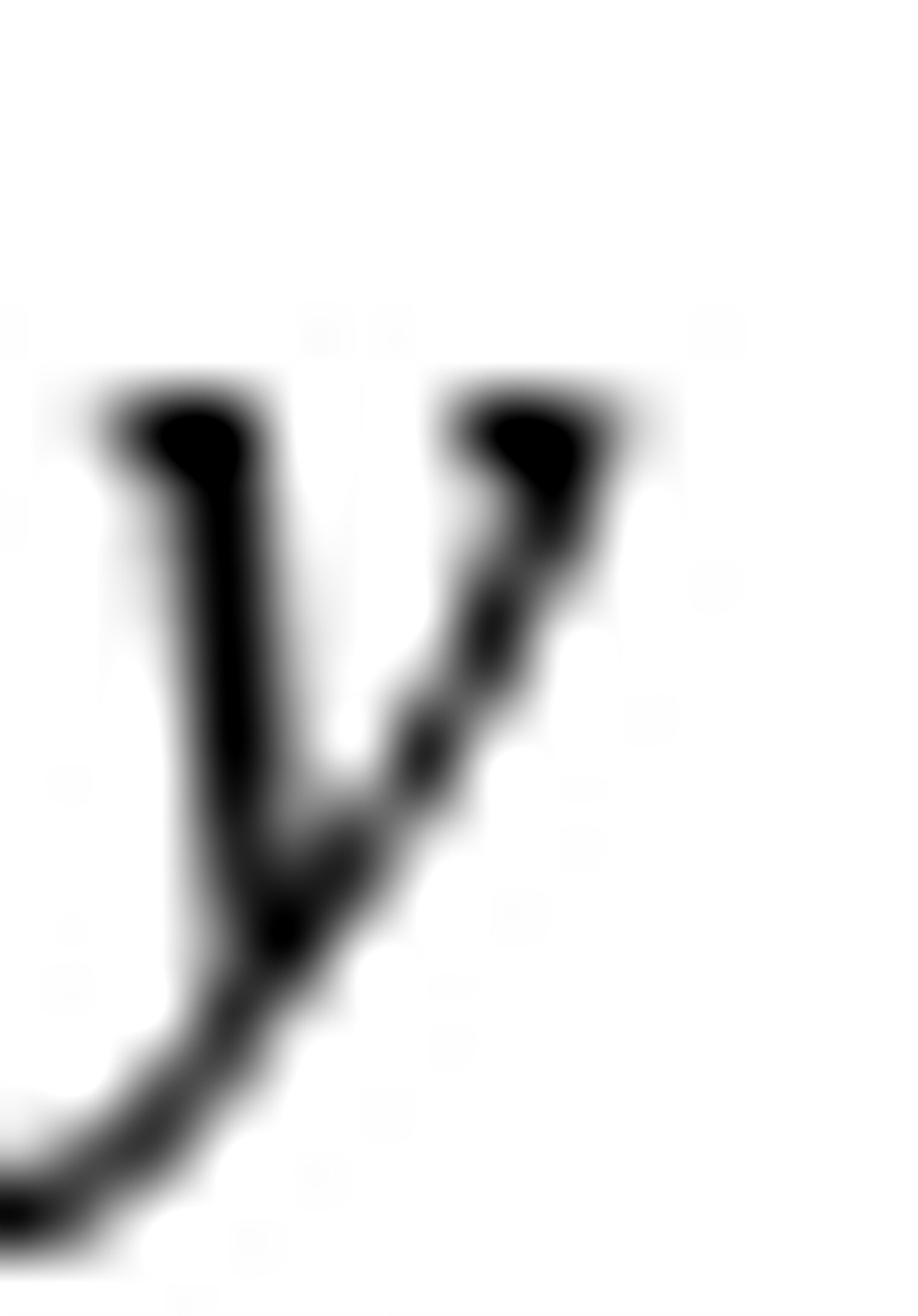 代表收入,
代表收入,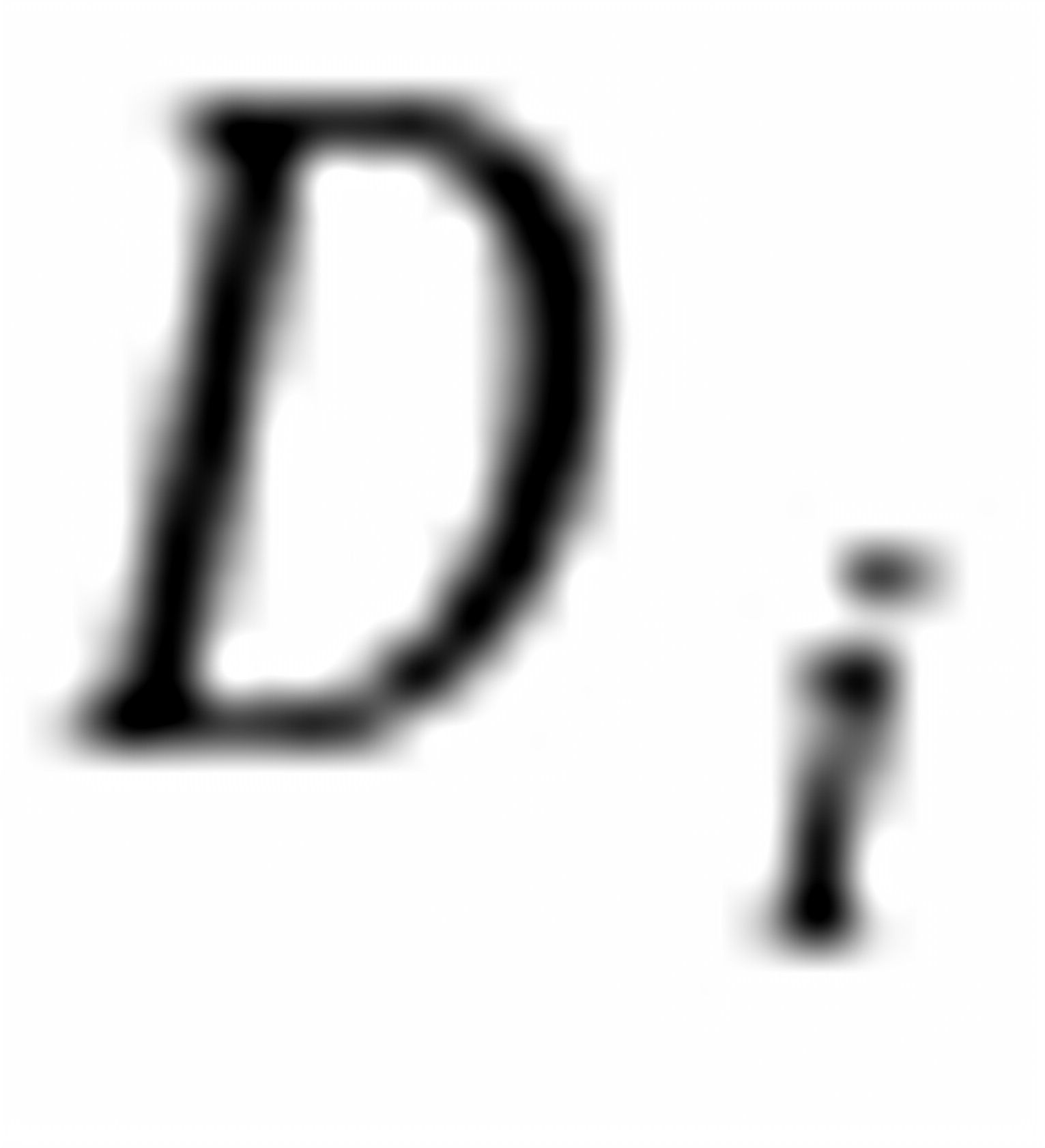 为虚拟变量,
为虚拟变量,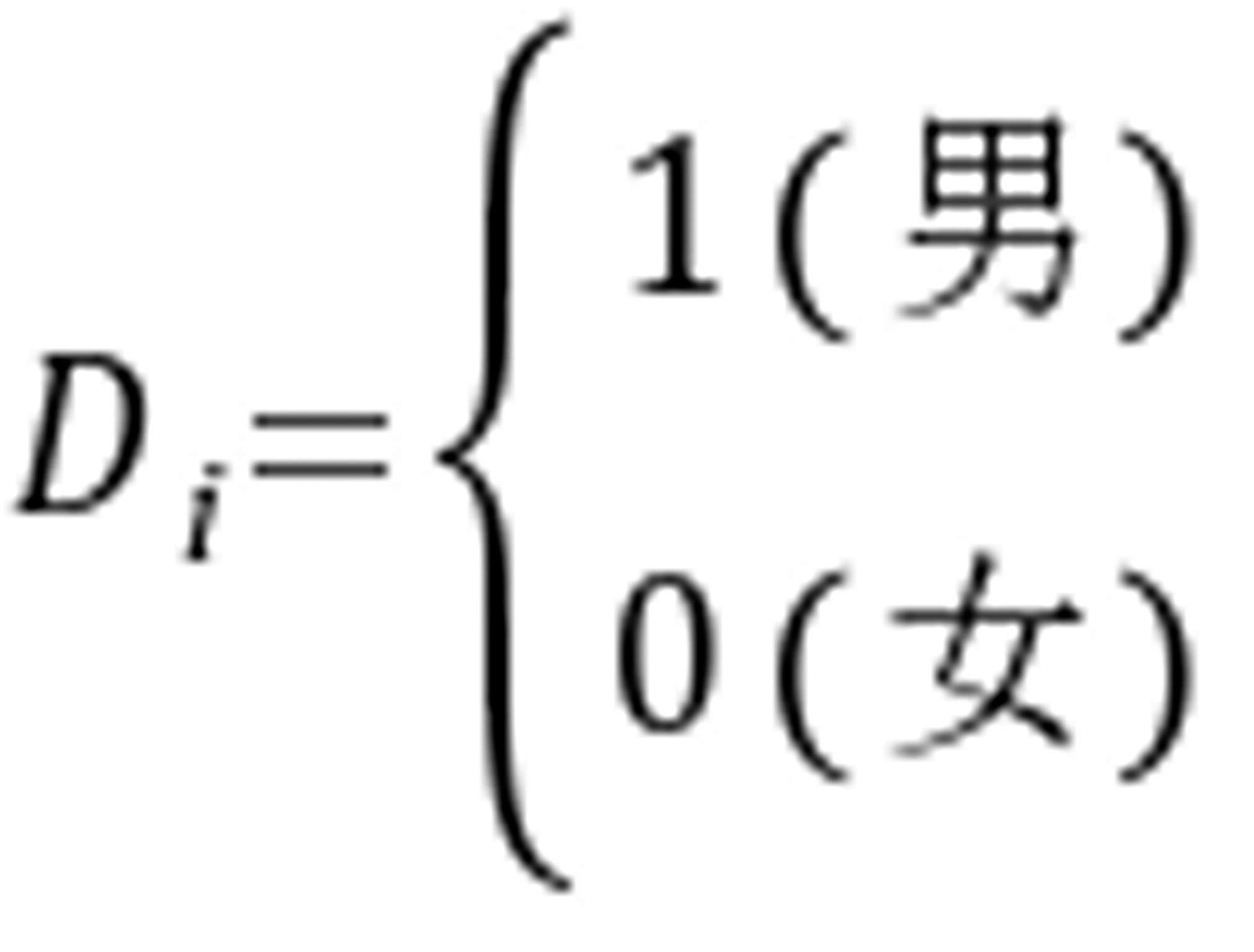
可以看出,  代表女性的收入,
代表女性的收入, 代表男性与女性收入之间的差额,从
代表男性与女性收入之间的差额,从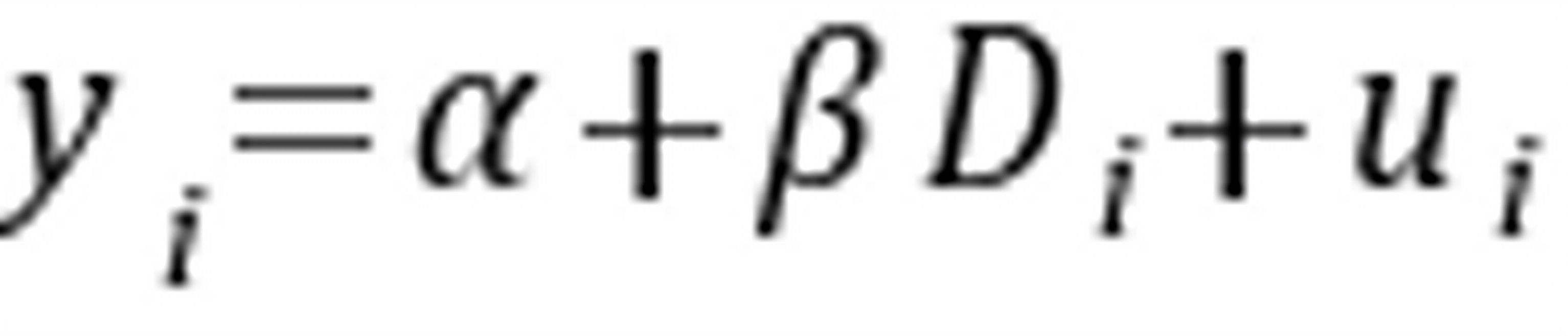 式很容易得出:
式很容易得出:
检验假设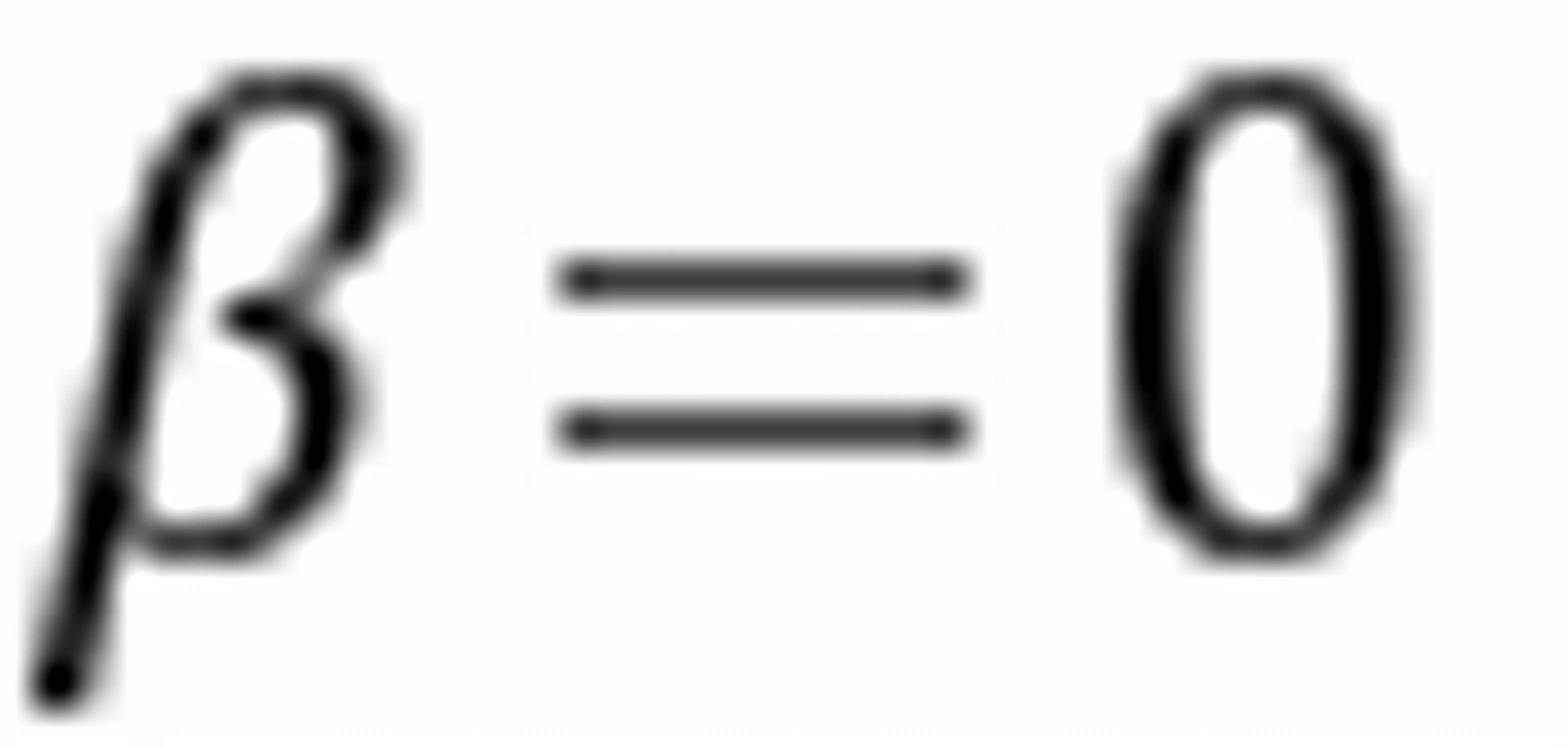 ,就是检验男女的平均收入之间是否有差额。若:
,就是检验男女的平均收入之间是否有差额。若: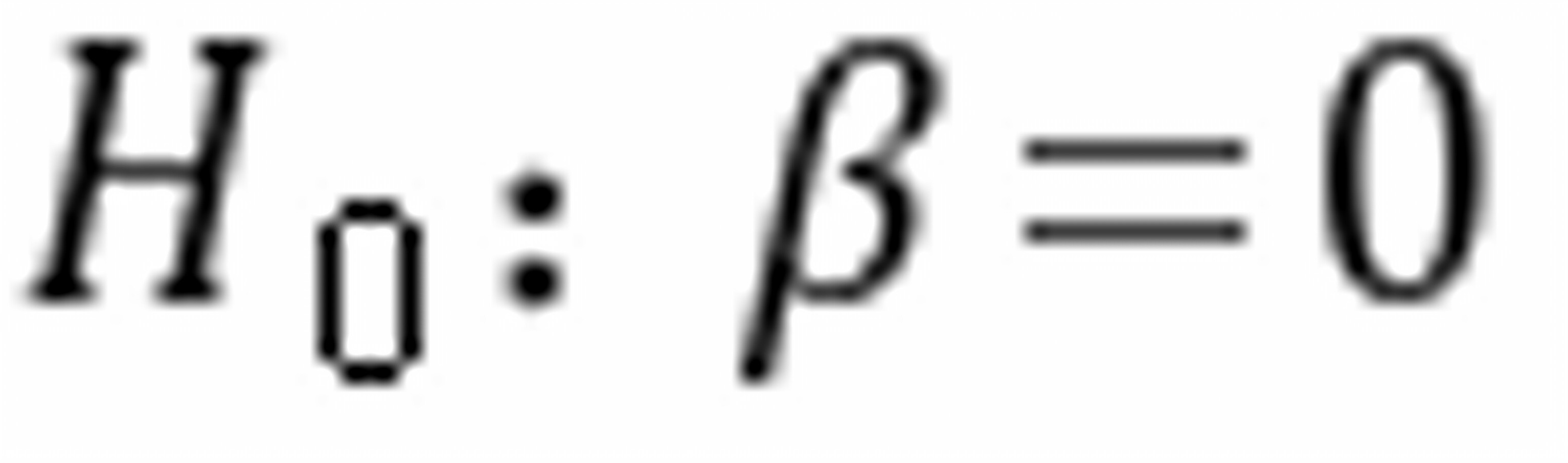 成立,说明收入与性别没有明显关系。若不成立,说明收入与性别有明关系。
成立,说明收入与性别没有明显关系。若不成立,说明收入与性别有明关系。
5-4.什么是“虚拟变量陷阱”?
答:以季节性产品冷饮的销量为例说明。假设销售函数模型为:
其中 表示销量,
表示销量,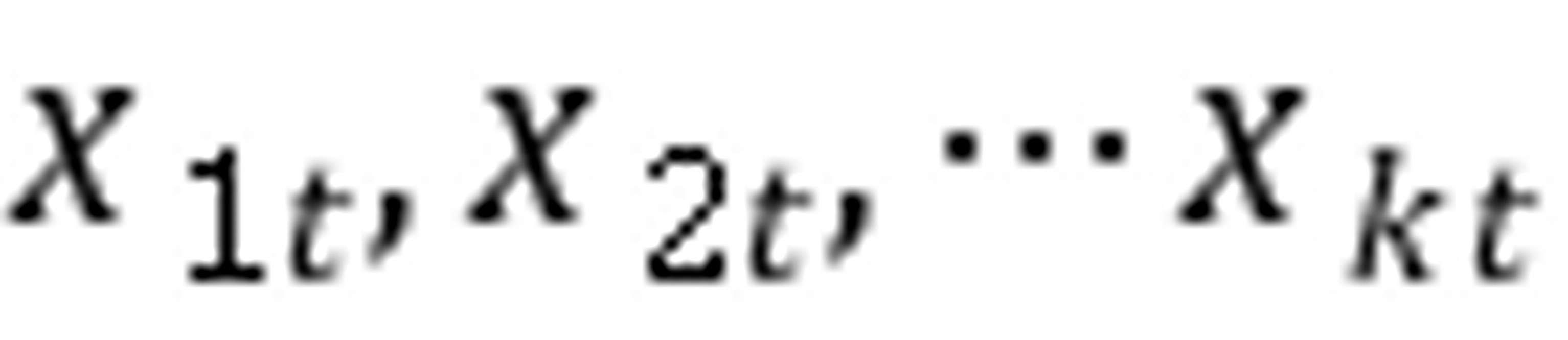 表示决定销量的解释变量;已知除定量解释变量的影响外,还受春、夏、秋、冬四季的影响,为把季节变化对销量的影响反映到模型中,如果我们引入4个虚拟变量:
表示决定销量的解释变量;已知除定量解释变量的影响外,还受春、夏、秋、冬四季的影响,为把季节变化对销量的影响反映到模型中,如果我们引入4个虚拟变量:
这样销售函数的季节回归模型为:
4个虚拟变量之间具有关系: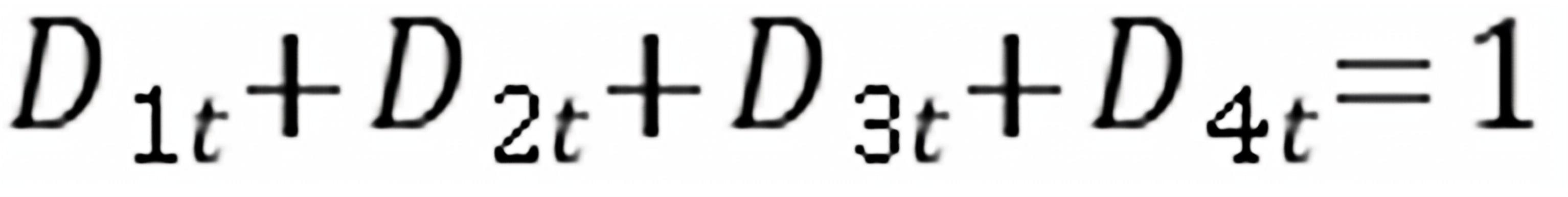 ,出现完全多重共线性问题,使OLS法不能使用,这就称为“虚拟变量陷阱”。为克服这一问题,一般在引入虚拟变量时要求如果有m个定性变量,只在模型中引入m-1个虚拟变量。
,出现完全多重共线性问题,使OLS法不能使用,这就称为“虚拟变量陷阱”。为克服这一问题,一般在引入虚拟变量时要求如果有m个定性变量,只在模型中引入m-1个虚拟变量。
5-5.对包含常数项的季节变量模型运用最小二乘法时,如果模型中引入4个季节虚拟变量,其估计结果会出现什么问题?
答:对包含常数项的季节变量模型运用OLS法时,如果模型中引入4个季节虚拟变量,会造成完全多重共线性,则参数估计量不存在;其次,即便是一般共线性,使用OLS法参数估计量非有效;参数估计量经济含义不合理;变量的显著性检验失去意义;模型的预测功能失效。
5-9.试在消费函数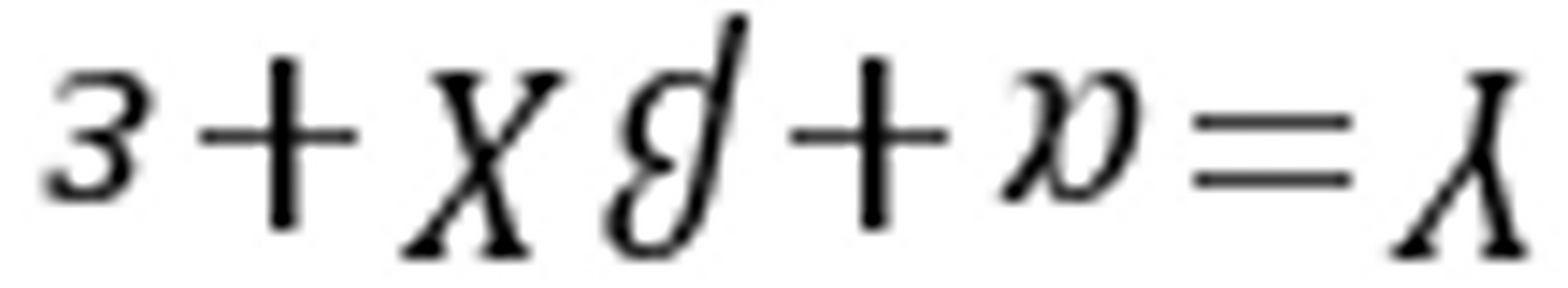 中(以加法形式)引入虚拟变量,用以反映季节因素(淡、旺季)和收入层次差异(高、中、低)对消费需求的影响,并写出各类消费函数的具体形式。
中(以加法形式)引入虚拟变量,用以反映季节因素(淡、旺季)和收入层次差异(高、中、低)对消费需求的影响,并写出各类消费函数的具体形式。
答:在消费函数中以加法形式引入虚拟变量,用以反映季节因素(淡、旺)和收入层次差异(高、中、低)对消费需求的影响,形如下式:
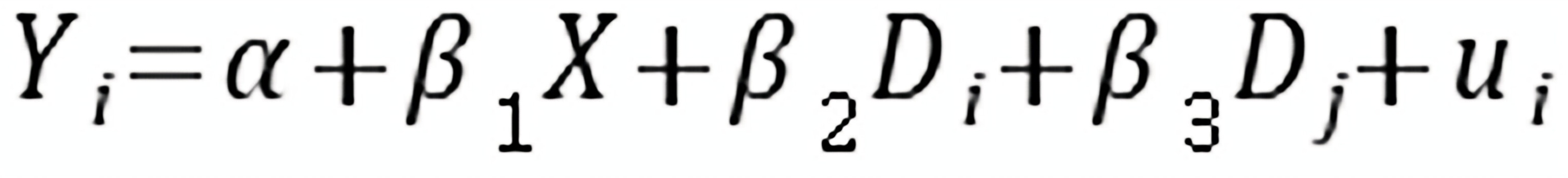 其中:
其中: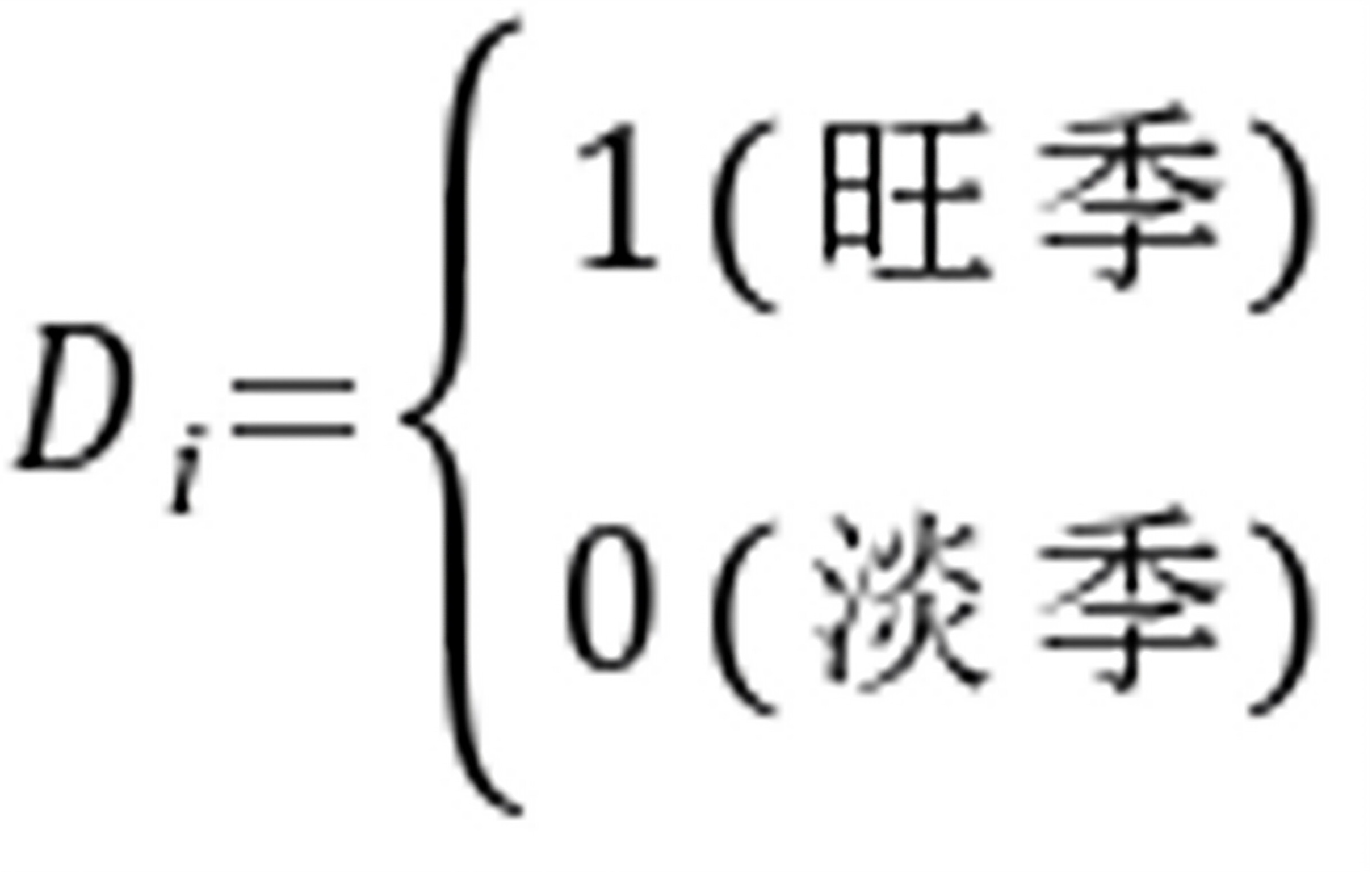 ,
,
5-19.如果一个定性变量含有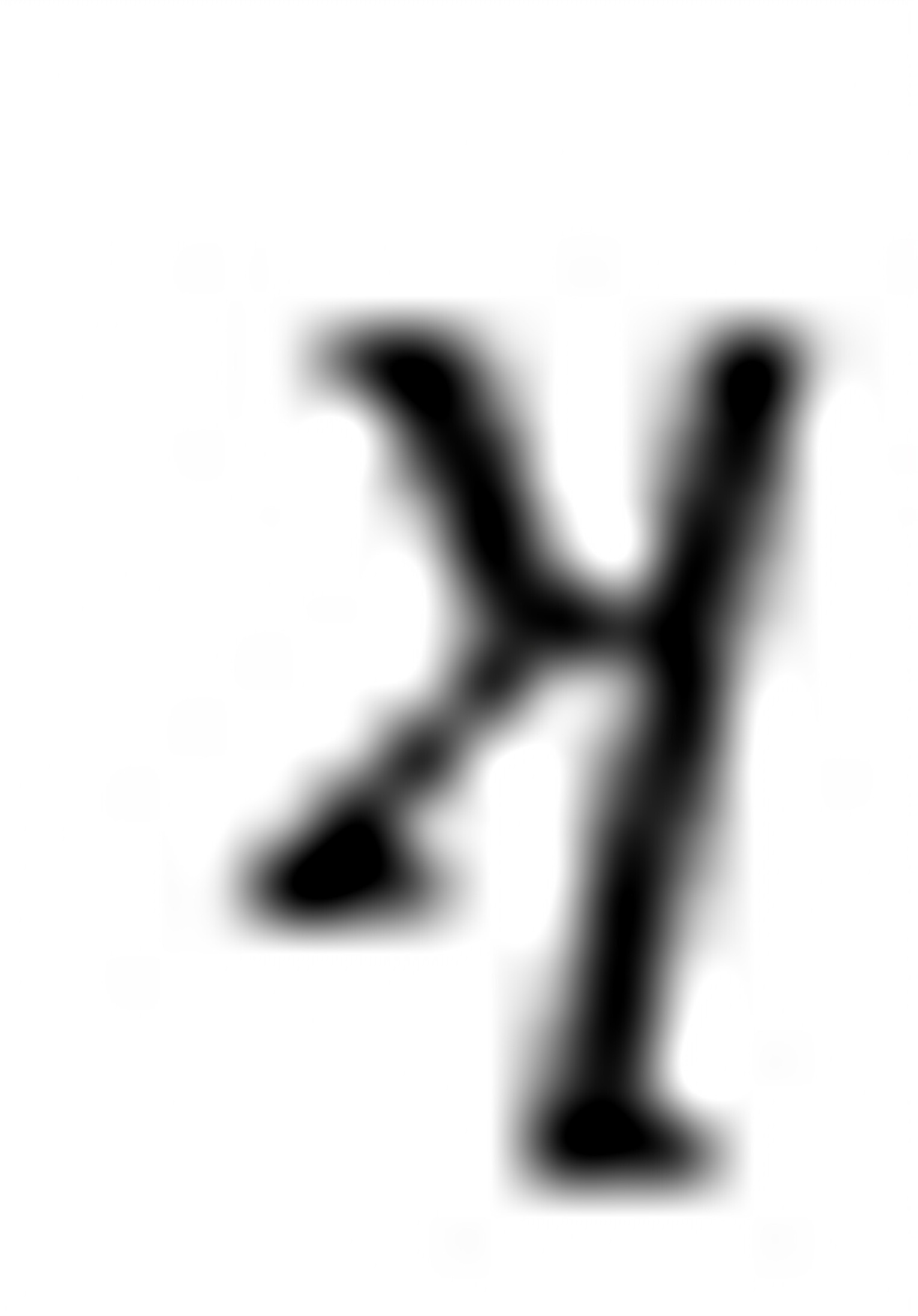 个类别,为什么不能设个虚拟变量?
个类别,为什么不能设个虚拟变量?
⏺
答:如果一个定性变量含有个类别,一般只能设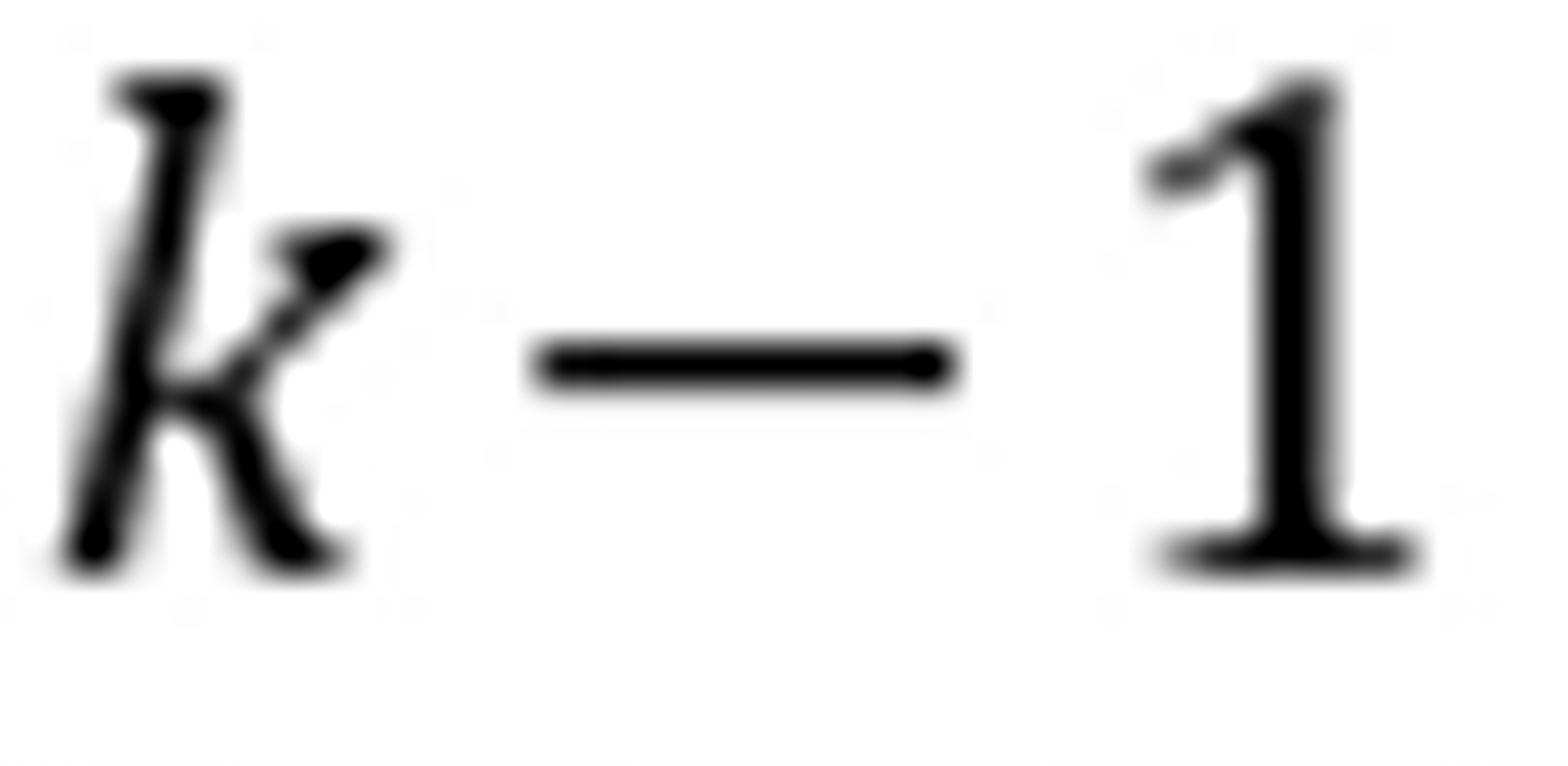 个虚拟变量,以避免多重共线。
个虚拟变量,以避免多重共线。
⏺
⏺
(1)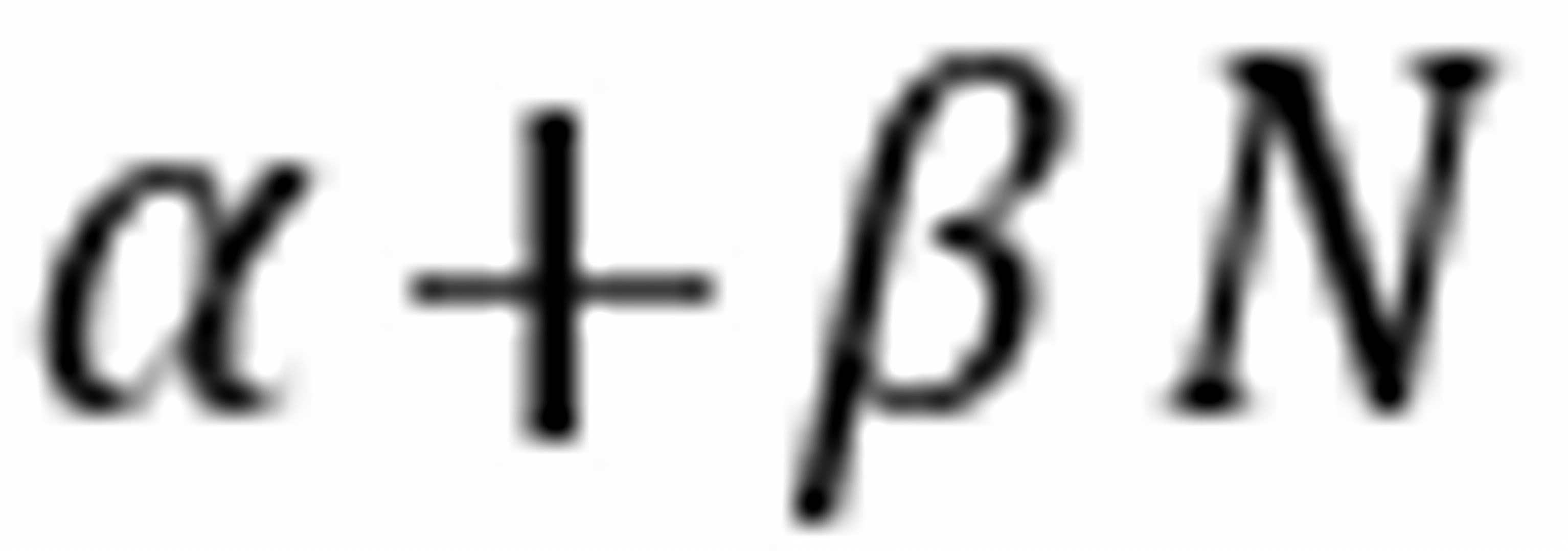 为接受过N年教育的员工的总体平均起始薪金。当N为零时,平均薪金为,因此表示没有接受过教育员工的平均起始薪金。是每单位N变化所引起的E的变化,即表示每多接受一年学校教育所对应的薪金增加值。
为接受过N年教育的员工的总体平均起始薪金。当N为零时,平均薪金为,因此表示没有接受过教育员工的平均起始薪金。是每单位N变化所引起的E的变化,即表示每多接受一年学校教育所对应的薪金增加值。
(2)OLS估计量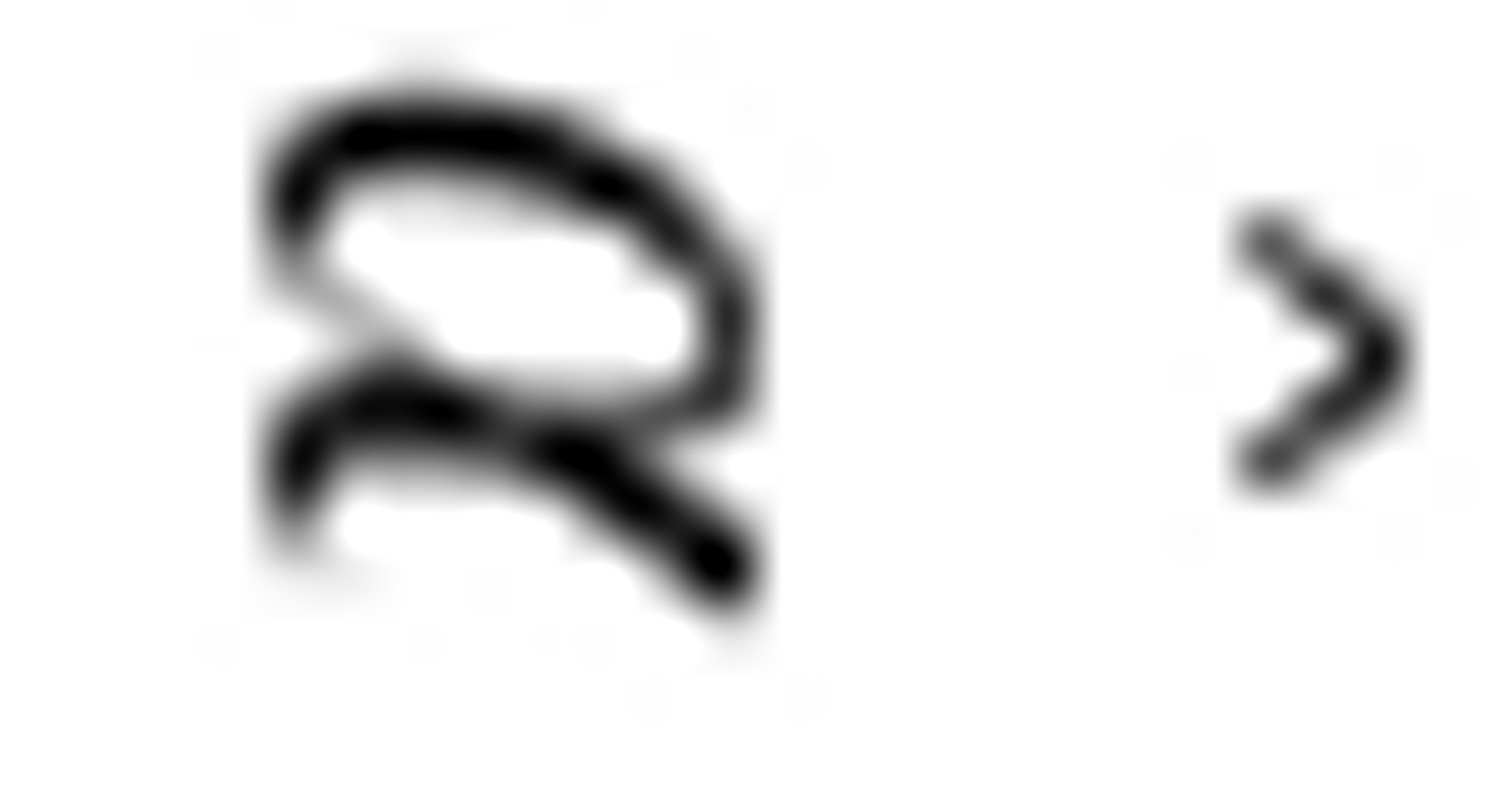 和仍
和仍 满足线性性、无偏性及有效性,因为这些性质的的成立无需随机扰动项
满足线性性、无偏性及有效性,因为这些性质的的成立无需随机扰动项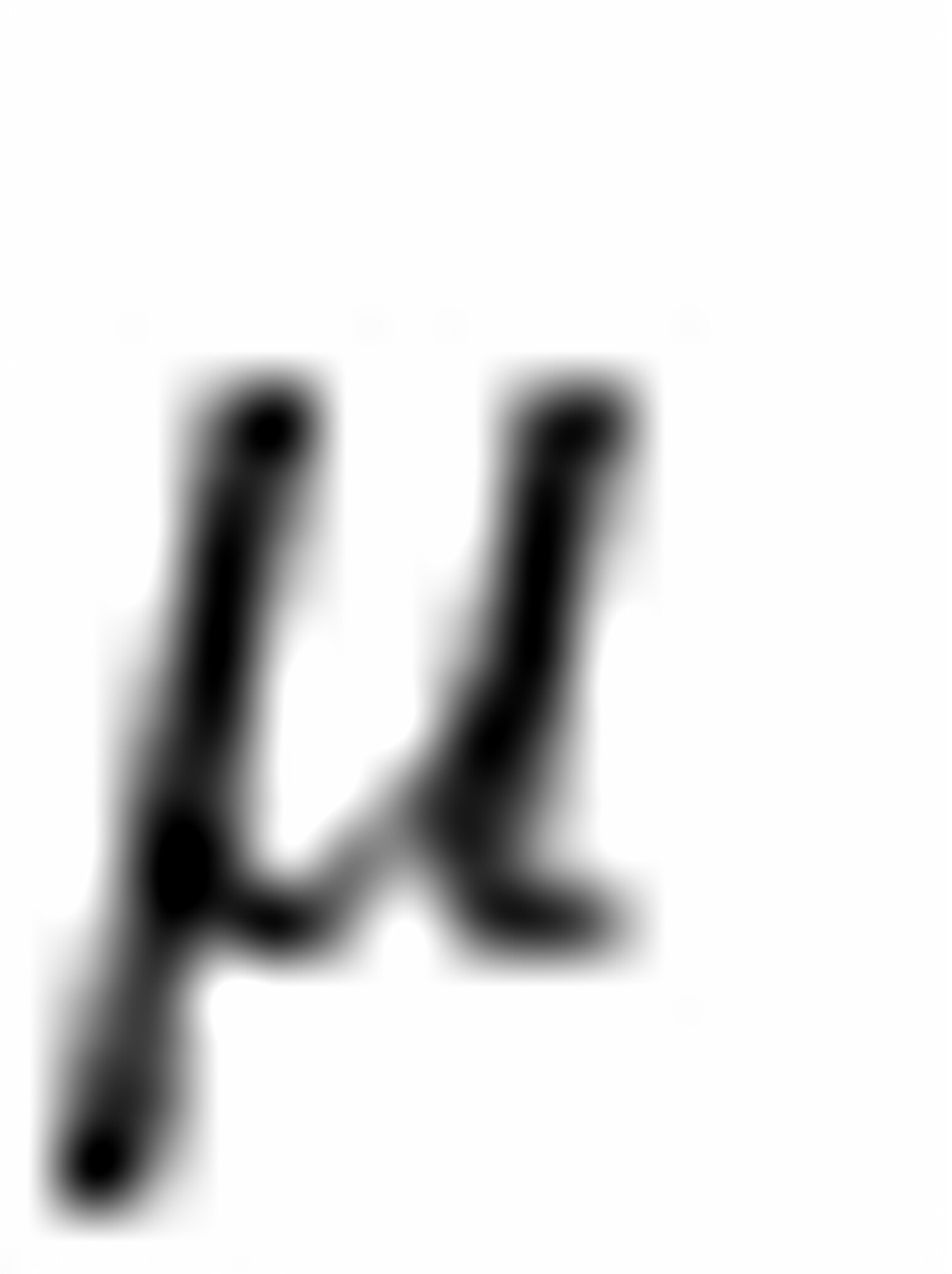 的正态分布假设。
的正态分布假设。
(3)如果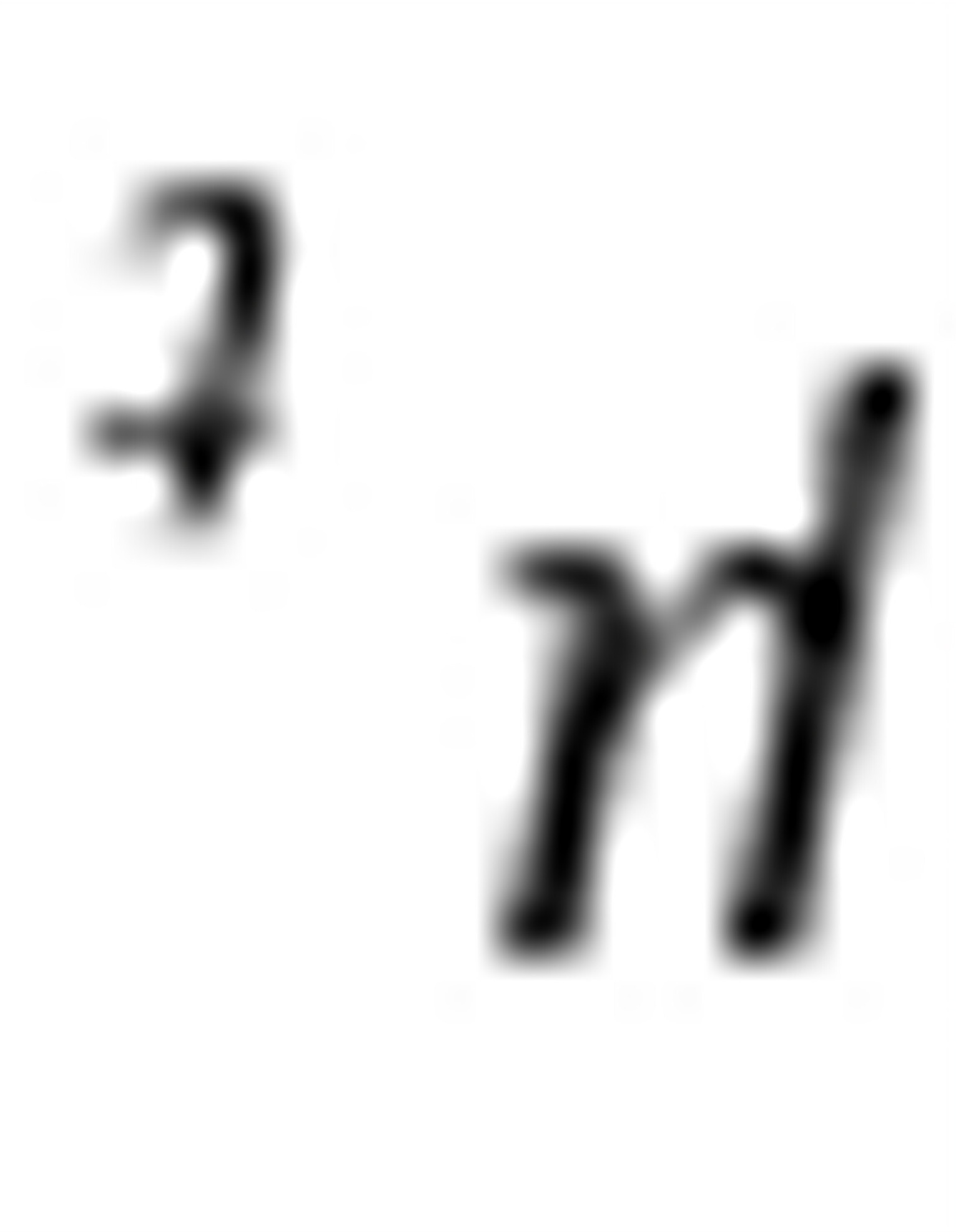 的分布未知,则所有的假设检验都是无效的。因为t检验与F检验是建立在的正态分布假设之上的。
的分布未知,则所有的假设检验都是无效的。因为t检验与F检验是建立在的正态分布假设之上的。
例6.对于人均存款与人均收入之间的关系式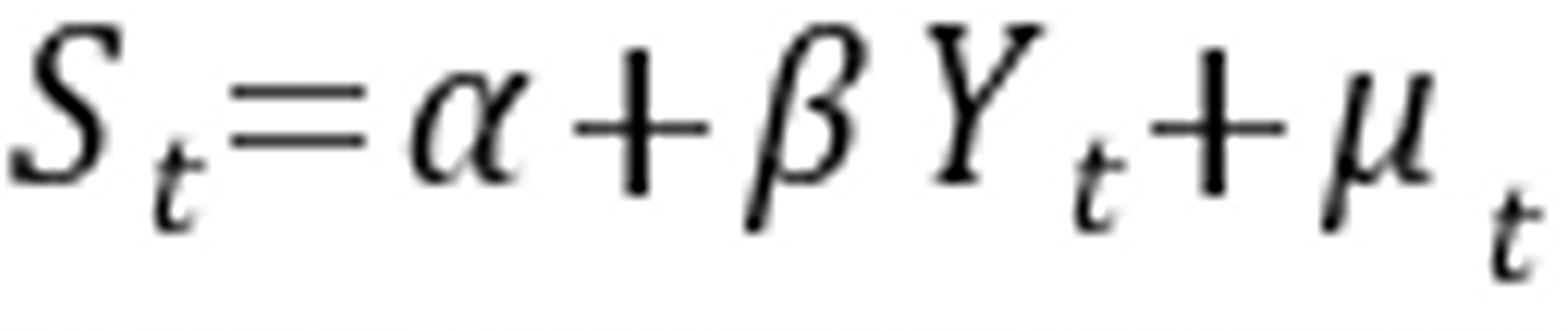 使用美国36年的年度数据得如下估计模型,括号内为标准差:
使用美国36年的年度数据得如下估计模型,括号内为标准差:
 =0.538
=0.538 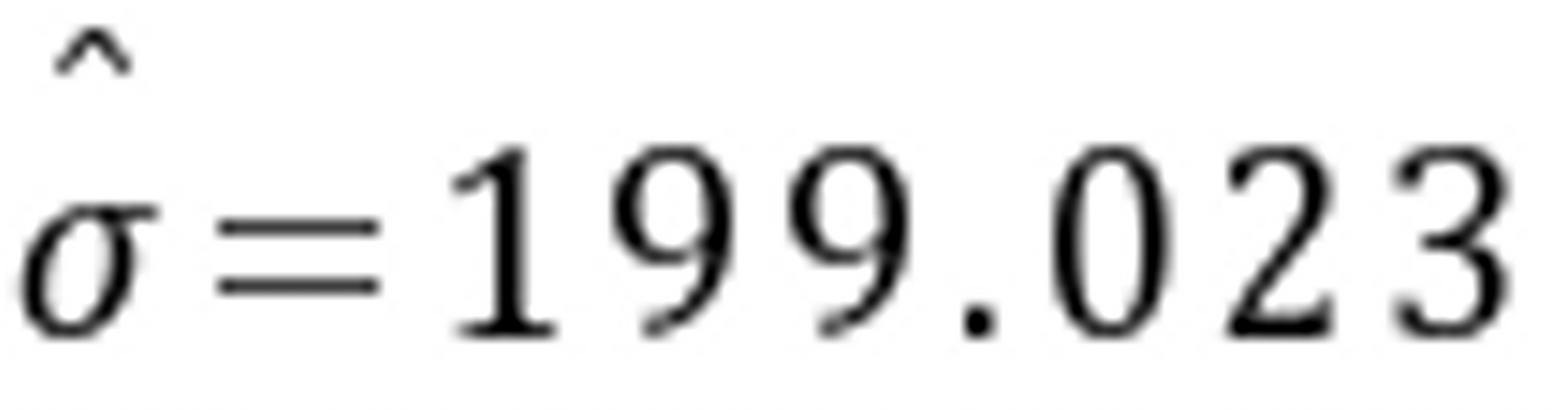
(1)的经济解释是什么?
(2)和的符号是什么?为什么?实际的符号与你的直觉一致吗?如果有冲突的话,你可以给出可能的原因吗?
(3)对于拟合优度你有什么看法吗?
(4)检验是否每一个回归系数都与零显著不同(在1%水平下)。同时对零假设和备择假设、检验统计值、其分布和自由度以及拒绝零假设的标准进行陈述。你的结论是什么?
解答:(1)为收入的边际储蓄倾向,表示人均收入每增加1美元时人均储蓄的预期平均变化量。
(2)由于收入为零时,家庭仍会有支出,可预期零收入时的平均储蓄为负,因此符号应为负。储蓄是收入的一部分,且会随着收入的增加而增加,因此预期的符号为正。实际的回归式中,的符号为正,与预期的一致。但截距项为负,与预期不符。这可能与由于模型的错误设定形造成的。如家庭的人口数可能影响家庭的储蓄形为,省略该变量将对截距项的估计产生影响;另一种可能就是线性设定可能不正确。
(3)拟合优度刻画解释变量对被解释变量变化的解释能力。模型中53.8%的拟合优度,表明收入的变化可以解释储蓄中53.8 %的变动。
(4)检验单个参数采用t检验,零假设为参数为零,备择假设为参数不为零。双变量情形下在零假设下t 分布的自由度为n-2=36-2=34。由t分布表知,双侧1%下的临界值位于2.750与2.704之间。斜率项计算的t值为0.067/0.011=6.09,截距项计算的t值为384.105/151.105=2.54。可见斜率项计算的t 值大于临界值,截距项小于临界值,因此拒绝斜率项为零的假设,但不拒绝截距项为零的假设。
2-22.假设王先生估计消费函数(用模型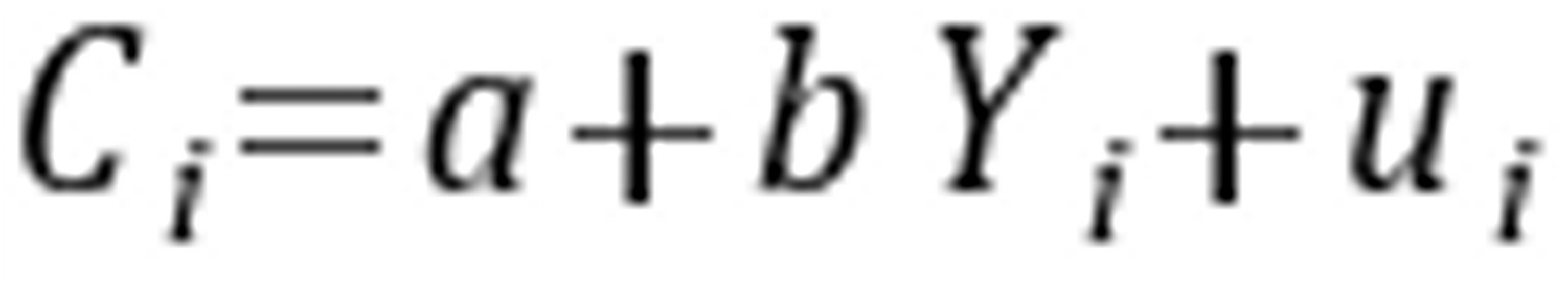 表示),并获得下列结果:
表示),并获得下列结果:
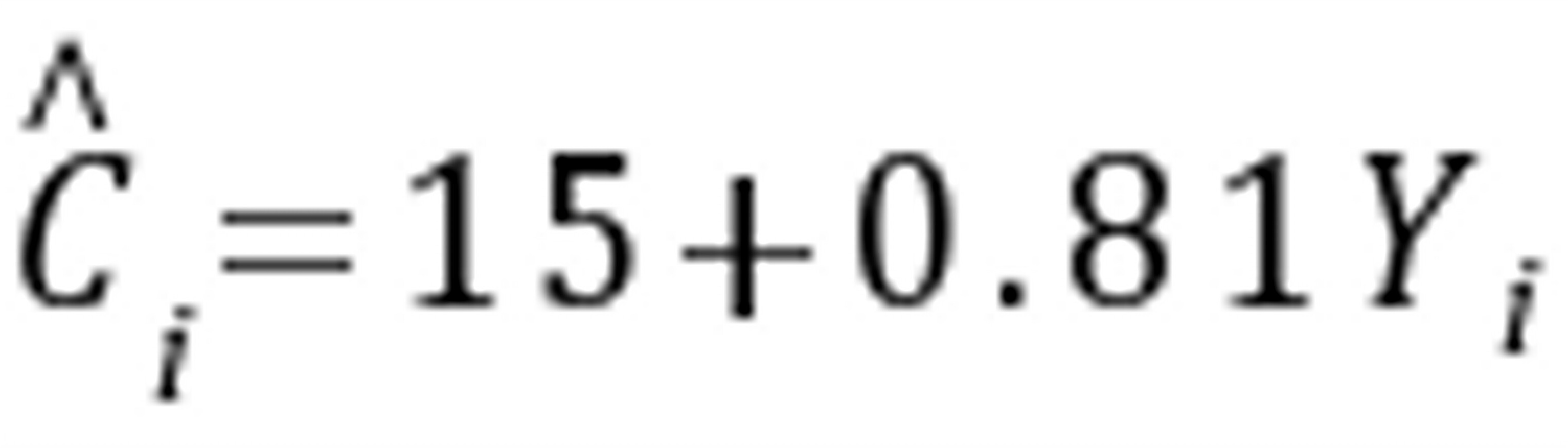 ,n=19
,n=19
(3.1) (18.7) R2=0.98 这里括号里的数字表示相应参数的T比率值。
要求:(1)利用T比率值检验假设:b=0(取显著水平为5%);(2)确定参数估计量的标准方差;(3)构造b的95%的置信区间,这个区间包括0吗?
题目解答
答案
解: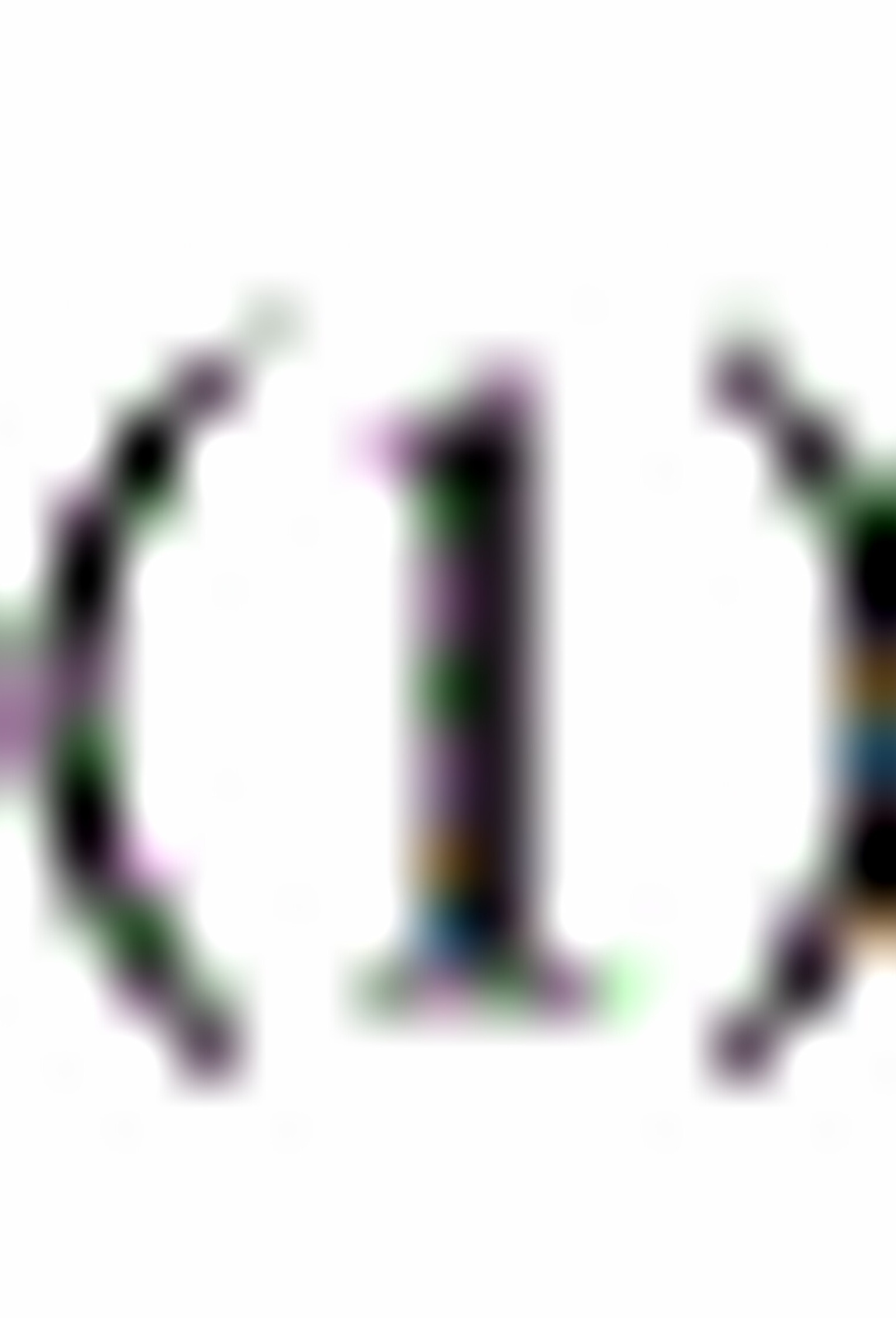 这是一个横截面序列回归。(图略)
这是一个横截面序列回归。(图略)
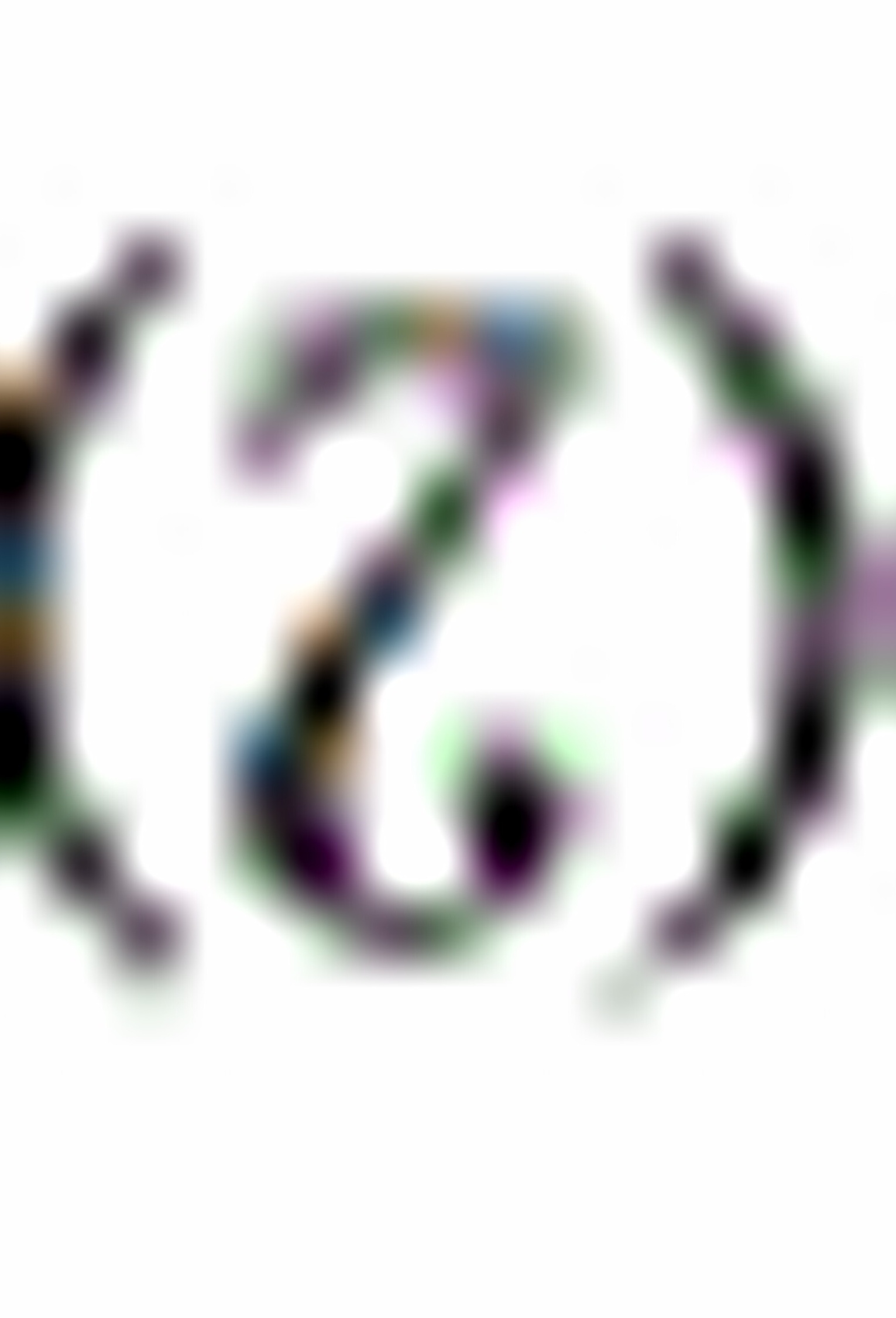 截距2.6911表示咖啡零售价在
截距2.6911表示咖啡零售价在 时刻为每磅0美元时,美国平均消费量为每天每人2.6911杯,这个数字没有经济意义;斜率-0.4795表示咖啡零售价与消费量负相关,在时刻,价格上升1美元/磅,则平均每天每人消费量减少0.4795杯;
时刻为每磅0美元时,美国平均消费量为每天每人2.6911杯,这个数字没有经济意义;斜率-0.4795表示咖啡零售价与消费量负相关,在时刻,价格上升1美元/磅,则平均每天每人消费量减少0.4795杯;
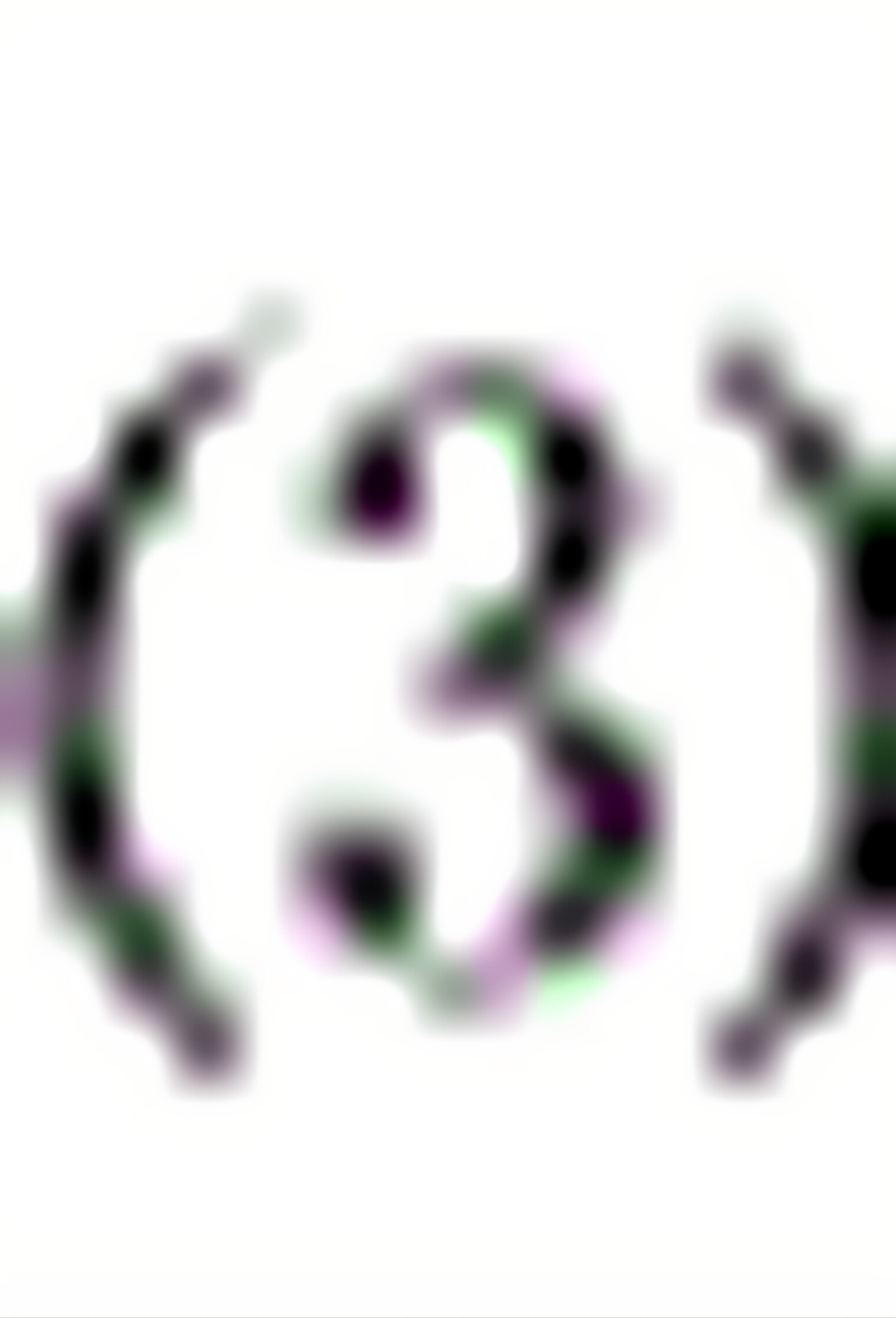 不能;
不能;
 不能;在同一条需求曲线上不同点的价格弹性不同,若要求出,须给出具体的
不能;在同一条需求曲线上不同点的价格弹性不同,若要求出,须给出具体的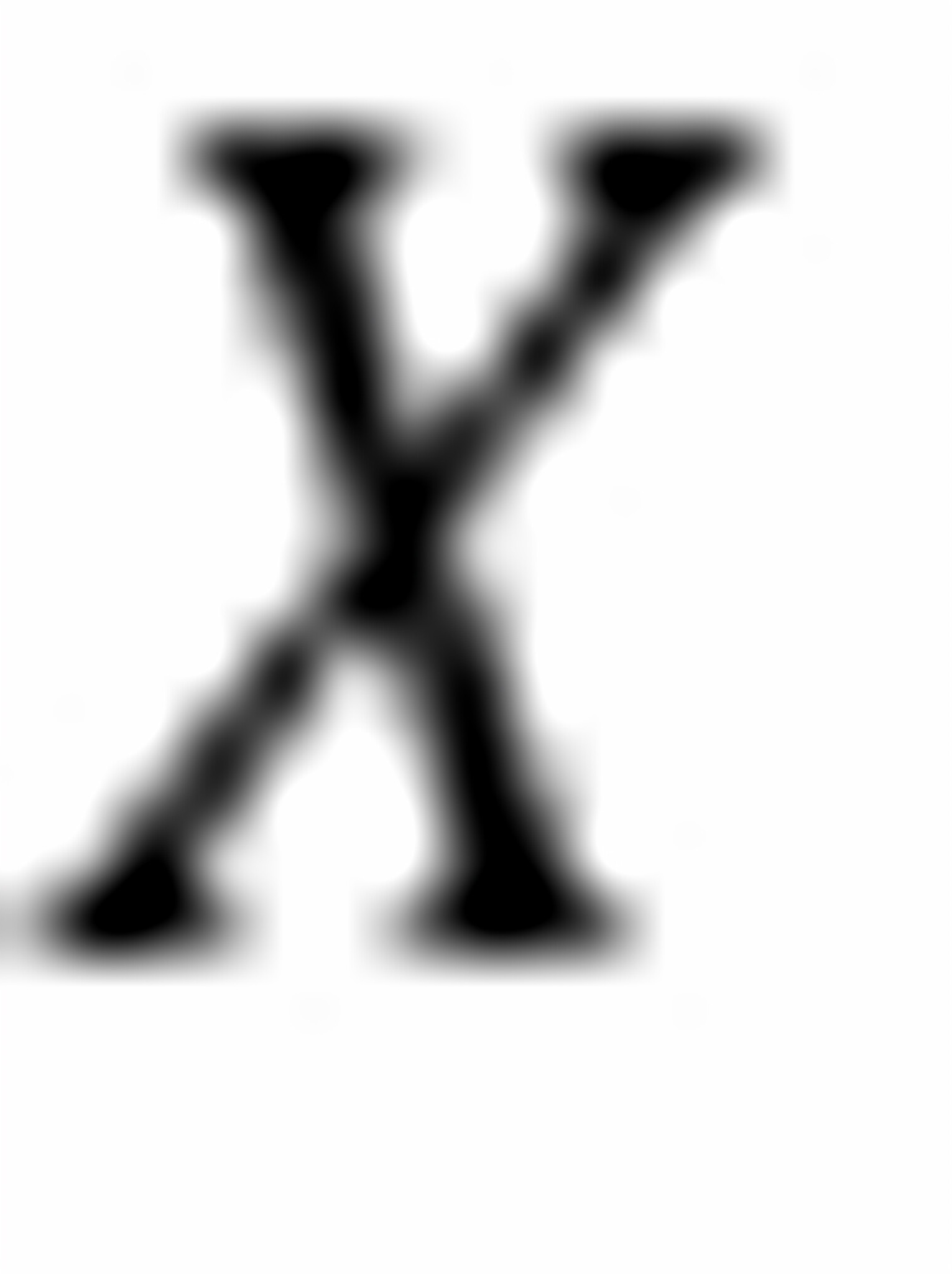 值及与之对应的
值及与之对应的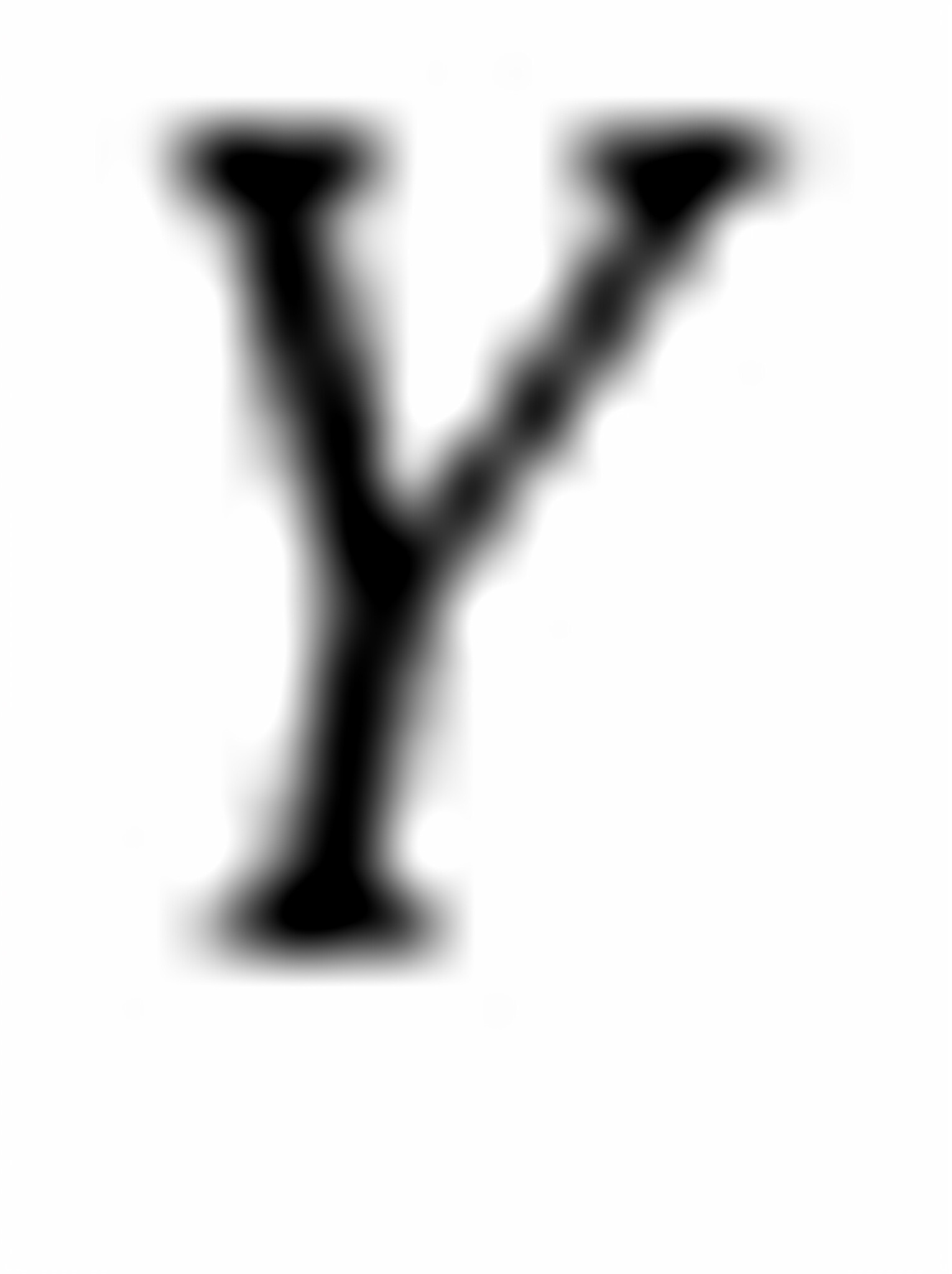 值。
值。