假设0.50,1.25,0.80,2.00是来自总体X的简单随机样本。已知Y=lnX服从正态分布N(μ,1)(1)求X的数学期望E (X)(记E(X)为b);求X的数学期望E (X)(记E(X)为b);求X的数学期望E (X)(记E(X)为b);
假设0.50,1.25,0.80,2.00是来自总体X的简单随机样本。已知Y=lnX服从正态分布N(μ,1)
(1)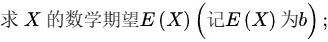
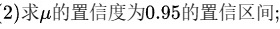

题目解答
答案
(1)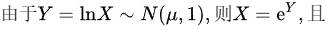
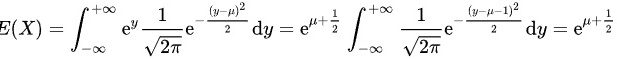
(2)当置信度1-α=0.95时,α=0.05,标准正态分布的显著水平为α=0.05的分位数为1.96,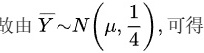
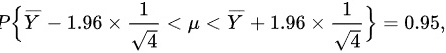
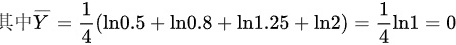
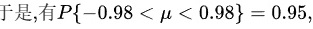

(3)由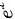 的严格递增性,可见
的严格递增性,可见

解析
考查要点:
本题主要考查对数正态分布的期望计算以及参数的置信区间估计。
- 第一问的关键在于利用正态变量的指数变换性质,计算对数正态分布的期望。
- 第二问需要根据样本均值构造正态总体均值的置信区间,注意样本量和方差的关系。
- 第三问需通过参数变换,将μ的置信区间转换为b的置信区间,利用指数函数的单调性。
解题核心思路:
- 正态分布与对数正态分布的关系:若Y ~ N(μ, σ²),则X = e^Y服从对数正态分布,其期望为E(X) = e^{μ + σ²/2}。
- 置信区间构造:利用样本均值的正态性,结合标准正态分布的分位数,建立不等式求解区间。
- 参数变换:通过指数函数的单调性,将μ的置信区间转换为b的置信区间。
第(1)题:求E(X)
步骤1:确定Y的分布
已知Y = lnX ~ N(μ, 1),即Y服从均值为μ、方差为1的正态分布。
步骤2:计算E(X)
X = e^Y,根据正态变量的指数期望公式:
$E(X) = E(e^Y) = e^{\mu + \frac{\sigma^2}{2}} = e^{\mu + \frac{1}{2}}$
因此,E(X) = e^{μ + 1/2},记为b = e^{μ + 1/2}。
第(3)题:求b的置信区间
步骤1:构造μ的置信区间
由样本均值̄Y ~ N(μ, 1/4)(方差为1/4,因样本量n=4),取置信度1-α=0.95,对应标准正态分位数z_{α/2}=1.96。
置信区间为:
$\overline{Y} \pm z_{\alpha/2} \cdot \frac{1}{\sqrt{4}} \quad \Rightarrow \quad \mu \in \left( \overline{Y} - 0.98, \overline{Y} + 0.98 \right)$
计算样本均值:
$\overline{Y} = \frac{1}{4} \sum_{i=1}^4 \ln X_i = \frac{1}{4} (\ln 0.50 + \ln 1.25 + \ln 0.80 + \ln 2.00) = 0$
因此,μ的置信区间为(-0.98, 0.98)。
步骤2:转换为b的置信区间
b = e^{μ + 1/2},将μ的区间代入:
$\mu + \frac{1}{2} \in \left( -0.98 + 0.5, 0.98 + 0.5 \right) = (-0.48, 1.48)$
取指数得:
$b \in \left( e^{-0.48}, e^{1.48} \right)$