题目
甲乙两个同时使用 t - t 检验法检验同一待验假设 H _ 0 : mu = W 甲的检验结果是拒绝 H _ 0 Z 的检验结果是接受 H _ 0 则以 下叙述错误的是 A 上面结果可能出现 这可能是由于各自选取的显著性水平 < 不同导致拒绝域不同造成的 B ) 上面结果可能出现 这可能是由于抽样不同而造成统计量观测值不同 C ) 在检验中甲有可能犯了弃真的错义 D : 在检验中乙有可能犯了弃真的错误
甲乙两个同时使用 t - t 检验法检验同一待验假设 H _ 0 : \mu = W 甲的检验结果是拒绝 H _ 0 Z 的检验结果是接受 H _ 0 则以 下叙述错误的是 A 上面结果可能出现 这可能是由于各自选取的显著性水平 < 不同导致拒绝域不同造成的 B ) 上面结果可能出现 这可能是由于抽样不同而造成统计量观测值不同 C ) 在检验中甲有可能犯了弃真的错义 D : 在检验中乙有可能犯了弃真的错误
题目解答
答案
解:用同一检验法检验同一待验假设的检验结果不相同,这有可能是由于各自选取的显著性水平 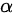 不同导致拒绝域不同造成的,也可能是由于抽样不同而造成统计量观测值不同。
不同导致拒绝域不同造成的,也可能是由于抽样不同而造成统计量观测值不同。
A,B正确
假设检验有两类错误,第一类错误和第二类错误
第一类错误:原假设H0符合实际情况,检验结果将它否定了,称为弃真错误。
第二类错误:原假设H0不符合实际情况,检验结果无法否定它,称为取伪错误。
显然本题中甲犯了弃真的错误。C正确
因此D错误,本题选D
解析
步骤 1:理解 t - t 检验法
t - t 检验法是一种用于检验样本均值与假设总体均值之间差异显著性的统计方法。它通过计算 t 统计量来判断样本均值与假设总体均值之间的差异是否显著。
步骤 2:分析检验结果
甲的检验结果是拒绝 H _ 0 ,这意味着甲认为样本均值与假设总体均值之间的差异是显著的。乙的检验结果是接受 H _ 0 ,这意味着乙认为样本均值与假设总体均值之间的差异不显著。
步骤 3:分析可能的原因
A) 上面结果可能出现,这可能是由于各自选取的显著性水平 < 不同导致拒绝域不同造成的。显著性水平 < 是检验中用来判断差异是否显著的标准,不同的显著性水平会导致不同的拒绝域。
B) 上面结果可能出现,这可能是由于抽样不同而造成统计量观测值不同。不同的样本可能会导致不同的统计量观测值,从而影响检验结果。
C) 在检验中甲有可能犯了弃真的错误。弃真错误是指原假设 H _ 0 符合实际情况,检验结果将它否定了。甲拒绝 H _ 0 ,有可能犯了弃真错误。
D) 在检验中乙有可能犯了弃真的错误。乙接受 H _ 0 ,不可能犯弃真错误,因为乙没有否定 H _ 0 。
t - t 检验法是一种用于检验样本均值与假设总体均值之间差异显著性的统计方法。它通过计算 t 统计量来判断样本均值与假设总体均值之间的差异是否显著。
步骤 2:分析检验结果
甲的检验结果是拒绝 H _ 0 ,这意味着甲认为样本均值与假设总体均值之间的差异是显著的。乙的检验结果是接受 H _ 0 ,这意味着乙认为样本均值与假设总体均值之间的差异不显著。
步骤 3:分析可能的原因
A) 上面结果可能出现,这可能是由于各自选取的显著性水平 < 不同导致拒绝域不同造成的。显著性水平 < 是检验中用来判断差异是否显著的标准,不同的显著性水平会导致不同的拒绝域。
B) 上面结果可能出现,这可能是由于抽样不同而造成统计量观测值不同。不同的样本可能会导致不同的统计量观测值,从而影响检验结果。
C) 在检验中甲有可能犯了弃真的错误。弃真错误是指原假设 H _ 0 符合实际情况,检验结果将它否定了。甲拒绝 H _ 0 ,有可能犯了弃真错误。
D) 在检验中乙有可能犯了弃真的错误。乙接受 H _ 0 ,不可能犯弃真错误,因为乙没有否定 H _ 0 。