国庆70周年阅兵式上的女兵们是一道靓丽的风景线,每一名女兵都是经过层层筛选才最终入选受阅方队,筛选标准非常严格,例如要求女兵身高(单位:cm)在区间[165,175]内。现从全体受阅女兵中随机抽取200人,对她们的身高进行统计,将所得数据分为[165,167),[167,169),[169,171),[171,173),[173,175]五组,得到如图所示的频率分布直方图,其中第三组的频数为75,最后三组的频率之和为0.7.频率-|||-组距-|||-0.125-|||-0.050-|||-0 165 167 169 171 173 175 身高(单位:cm)(1)请根据频率分布直方图估计样本的平均数x和方差s2(同一组中的数据用该组区间的中点值代表);(2)根据样本数据,可认为受阅女兵的身高X(cm)近似服从正态分布N(μ,σ2),其中μ近似为样本平均数x,σ2近似为样本方差s2.(i)求P(167.86<X<174.28);(ii)若从全体受阅女兵中随机抽取10人,求这10人中至少有1人的身高在174.28cm以上的概率。参考数据:若X∼N(μ,σ2),则P(μ−σ<X<μ+σ)=0.6826,P(μ−2σ<X<μ+2σ)=0.9544,115−−−√≈10.7,0.954410≈0.63,0.97729≈0.81,0.977210≈0.79.
国庆
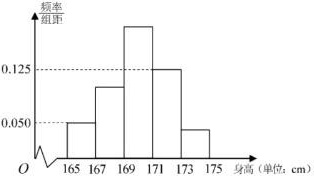
(1)请根据频率分布直方图估计样本的平均数
(2)根据样本数据
参考数据:若
题目解答
答案
(1)由题知五组频率依次为
故
(2)由题知
解析
由题意知,第三组的频数为75,总样本数为200,因此第三组的频率为75/200=0.375。最后三组的频率之和为0.7,因此第四组和第五组的频率之和为0.7-0.375=0.325。由于频率分布直方图中各组的频率之和为1,因此第一组和第二组的频率之和为1-0.7=0.3。根据频率分布直方图,第一组和第二组的频率分别为0.1和0.2,因此第三组、第四组和第五组的频率分别为0.375、0.25和0.075。
步骤 2:计算样本的平均数x
样本的平均数x可以通过各组的中点值乘以相应的频率,然后求和得到。具体计算如下:
x = 0.1×166 + 0.2×168 + 0.375×170 + 0.25×172 + 0.075×174 = 170。
步骤 3:计算样本的方差s2
样本的方差s2可以通过各组的中点值与平均数的差的平方乘以相应的频率,然后求和得到。具体计算如下:
s2 = (170−166)2×0.1 + (170−168)2×0.2 + (170−172)2×0.25 + (170−174)2×0.075 = 4.6。
步骤 4:计算P(167.86
步骤 5:计算10人中至少有1人的身高在174.28cm以上的概率
根据正态分布的性质,P(X>174.28)=1−0.9544/2=0.0228。因此,10人中至少有1人的身高在174.28cm以上的概率P=1−(1−0.0228)10=1−0.977210≈1−0.79=0.21。