题目
设X1,X2,···,Xn是取自总体X的一个样本,其中X服从参数为X1,X2,···,Xn的泊松分布,其中X1,X2,···,Xn未知,X1,X2,···,Xn,求X1,X2,···,Xn的矩估计与最大似然估计,如得到一组样本观测值X01234频数17201021求X1,X2,···,Xn的矩估计值与最大似然估计值。
设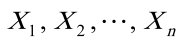 是取自总体X的一个样本,其中X服从参数为
是取自总体X的一个样本,其中X服从参数为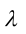 的泊松分布,其中未知,
的泊松分布,其中未知,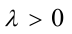 ,求的矩估计与最大似然估计,如得到一组样本观测值
,求的矩估计与最大似然估计,如得到一组样本观测值
是取自总体X的一个样本,其中X服从参数为的泊松分布,其中未知,,求的矩估计与最大似然估计,如得到一组样本观测值X | 0 | 1 | 2 | 3 | 4 |
频数 | 17 | 20 | 10 | 2 | 1 |
求的矩估计值与最大似然估计值。
的矩估计值与最大似然估计值。题目解答
答案
解 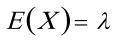 ,故的矩估计量
,故的矩估计量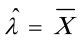 。
。
,故的矩估计量。由样本观测值可算得
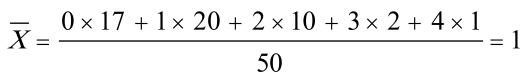
另,X的分布律为
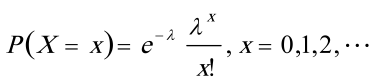
故似然函数为
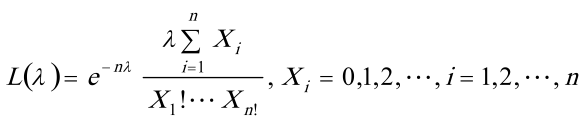
对数似然函数为
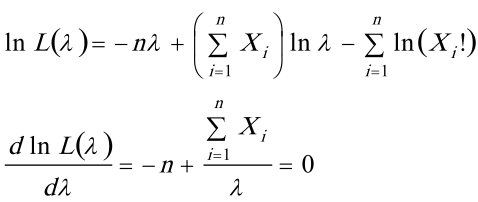
解得的最大似然估计量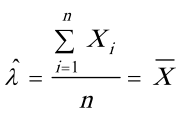 ,
,
的最大似然估计量,故的最大似然估计值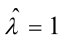 。
。
的最大似然估计值。解析
本题主要考查参数估计中的矩估计和最大似然估计方法,具体思路如下:
1. 求$\lambda$的矩估计
- 首先明确矩估计的原理,对于总体$X$,用样本矩来估计总体矩。对于泊松分布$X\sim P(\lambda)$,其期望$E(X)=\lambda$。
- 样本一阶原点矩为$\overline{X}=\frac{1}{n}\sum_{i = 1}^{n}X_{i}$,令$E(X)=\overline{X}$,即$\lambda=\overline{X}$,所以$\lambda$的矩估计量为$\hat{\lambda}=\overline{X}$。
- 已知样本观测值,计算样本均值$\overline{X}$:
- 样本总数$n = 17 + 20 + 10 + 2 + 1 = 50$。
- 根据样本均值公式$\overline{X}=\frac{1}{n}\sum_{i = 1}^{n}x_{i}f_{i}$(其中$x_{i}$是取值,$f_{i}$是对应频数),可得$\overline{X}=\frac{0\times17 + 1\times20 + 2\times10 + 3\times2 + 4\times1}{50}$
- 先计算分子:$0\times17 + 1\times20 + 2\times10 + 3\times2 + 4\times1=0 + 20 + 20 + 6 + 4 = 50$。
- 则$\overline{X}=\frac{50}{50}=1$,所以$\lambda$的矩估计值为$\hat{\lambda}=1$。
2. 求$\lambda$的最大似然估计
- 已知$X$服从参数为$\lambda$的泊松分布,其分布律为$P(X = x)=e^{-\lambda}\frac{\lambda^{x}}{x!},x = 0,1,2,\cdots$。
- 似然函数$L(\lambda)=\prod_{i = 1}^{n}P(X_{i}=x_{i})=\prod_{i = 1}^{n}e^{-\lambda}\frac{\lambda^{x_{i}}}{x_{i}!}=e^{-n\lambda}\frac{\lambda^{\sum_{i = 1}^{n}x_{i}}}{\prod_{i = 1}^{n}x_{i}!}$。
- 为了方便计算,取对数似然函数$\ln L(\lambda)=\ln\left(e^{-n\lambda}\frac{\lambda^{\sum_{i = 1}^{n}x_{i}}}{\prod_{i = 1}^{n}x_{i}!}\right)$。
- 根据对数运算法则$\ln(ab)=\ln a+\ln b$和$\ln\frac{a}{b}=\ln a - \ln b$,可得$\ln L(\lambda)=-n\lambda+\left(\sum_{i = 1}^{n}x_{i}\right)\ln\lambda-\ln\left(\prod_{i = 1}^{n}x_{i}!\right)$。
- 对$\ln L(\lambda)$求关于$\lambda$的导数:
- $\frac{d\ln L(\lambda)}{d\lambda}=-n+\frac{\sum_{i = 1}^{n}x_{i}}{\lambda}$。
- 令$\frac{d\ln L(\lambda)}{d\lambda}=0$,即$-n+\frac{\sum_{i = 1}^{n}x_{i}}{\lambda}=0$。
- 移项可得$\frac{\sum_{i = 1}^{n}x_{i}}{\lambda}=n$,解得$\lambda=\frac{\sum_{i = 1}^{n}x_{i}}{n}=\overline{X}$,所以$\lambda$的最大似然估计量为$\hat{\lambda}=\overline{X}$。
- 由前面计算可知样本均值$\overline{X}=1$,所以$\lambda$的最大似然估计值为$\hat{\lambda}=1$。