题目
某电子设备制造厂所用的元件是由三家元件制造厂提供的。根据以往的记录有以下的数据:元件厂次品率市场份额10.020.1520.010.8030.030.05设这三家工厂的产品在仓库中是均匀混合的,且无区别的标志。(1)在仓库中随机地取一只元件,求它是次品的概率;(2)在仓库中随机地取一只元件,若已知取到的是次品,试分析此次品出自何厂的概率最大。
某电子设备制造厂所用的元件是由三家元件制造厂提供的。根据以往的记录有以下的数据:
元件厂
次品率
市场份额
1
0.02
0.15
2
0.01
0.80
3
0.03
0.05
设这三家工厂的产品在仓库中是均匀混合的,且无区别的标志。
(1)在仓库中随机地取一只元件,求它是次品的概率;
(2)在仓库中随机地取一只元件,若已知取到的是次品,试分析此次品出自何厂的概率最大。
题目解答
答案
解:设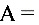 “取到的一只元件是次品”,
“取到的一只元件是次品”, 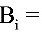 “所取到的产品是由第i家工厂提供的”,i=1,2,3. 则
“所取到的产品是由第i家工厂提供的”,i=1,2,3. 则
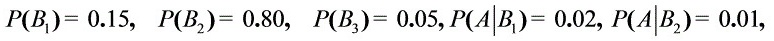
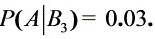 ……………………(2分)
……………………(2分)
于是(1) 由全概率公式得
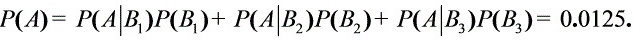
……………………(2分)
(2) 由贝叶斯公式得
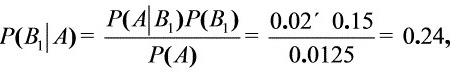
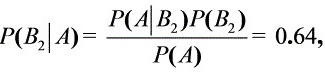
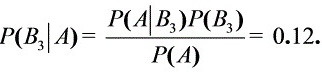
故这只次品来自于第二家工厂的概率最大。……………………(3分)
解析
考查要点:本题主要考查全概率公式和贝叶斯定理的应用,涉及条件概率的理解与计算。
解题思路:
- 第一问:计算随机取到次品的概率,需将各元件厂的市场份额与对应的次品率结合,利用全概率公式求和。
- 第二问:已知取到次品,求来自各厂的概率,需用贝叶斯定理计算后验概率,比较后验概率大小。
关键点:
- 全概率公式:将总概率分解为各子事件的加权和。
- 贝叶斯定理:通过先验概率和条件概率计算后验概率,注意分母是第一问的结果。
第(1)题
目标:计算随机取到次品的概率 $P(A)$。
应用全概率公式
$P(A) = \sum_{i=1}^{3} P(B_i)P(A|B_i)$
代入数据
- $P(B_1)P(A|B_1) = 0.15 \times 0.02 = 0.003$
- $P(B_2)P(A|B_2) = 0.80 \times 0.01 = 0.008$
- $P(B_3)P(A|B_3) = 0.05 \times 0.03 = 0.0015$
求和
$P(A) = 0.003 + 0.008 + 0.0015 = 0.0125$
第(2)题
目标:计算 $P(B_i|A)$,比较大小。
应用贝叶斯定理
$P(B_i|A) = \frac{P(A|B_i)P(B_i)}{P(A)}$
计算各厂后验概率
- 第1厂:
$P(B_1|A) = \frac{0.02 \times 0.15}{0.0125} = \frac{0.003}{0.0125} = 0.24$ - 第2厂:
$P(B_2|A) = \frac{0.01 \times 0.80}{0.0125} = \frac{0.008}{0.0125} = 0.64$ - 第3厂:
$P(B_3|A) = \frac{0.03 \times 0.05}{0.0125} = \frac{0.0015}{0.0125} = 0.12$
比较结果
$P(B_2|A) = 0.64$ 最大,因此次品最可能来自第2家工厂。