题目
设X1,X2,···,Yn是来自总体X1,X2,···,Yn的样本,且 X1,X2,···,Yn。则下列说法中正确的是 ()A 、a 的矩估计为X1,X2,···,Yn;B 、a 的矩估计为X1,X2,···,Yn ; C 、b 的最大似然估计为X1,X2,···,Yn ; D 、b 的最大似然估计为 X1,X2,···,Yn
设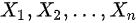 是来自总体
是来自总体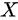 的样本,且
的样本,且 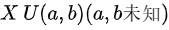 。则下列说法中正确的是 ()
。则下列说法中正确的是 ()
A 、a 的矩估计为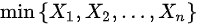 ;
;
B 、a 的矩估计为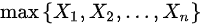 ;
;
C 、b 的最大似然估计为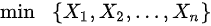 ;
;
D 、b 的最大似然估计为
题目解答
答案
AB选项,a 的矩估计为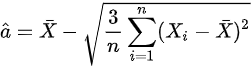
AB错误;
CD选项,b 的最大似然估计为 。
D正确。
因此答案选D
解析
步骤 1:理解矩估计和最大似然估计
矩估计是通过样本矩来估计总体参数的方法,而最大似然估计是通过最大化似然函数来估计参数的方法。对于均匀分布$XU(a,b)$,其概率密度函数为$f(x)=\frac{1}{b-a}$,其中$a\leq x\leq b$。
步骤 2:分析a的矩估计
对于均匀分布$XU(a,b)$,其均值$\mu=\frac{a+b}{2}$,方差$\sigma^2=\frac{(b-a)^2}{12}$。矩估计是通过样本均值和方差来估计总体参数。因此,a的矩估计不是直接通过样本的最小值或最大值来估计,而是通过样本均值和方差来估计。所以A和B选项都不正确。
步骤 3:分析b的最大似然估计
对于均匀分布$XU(a,b)$,其似然函数为$L(a,b)=\prod_{i=1}^{n}\frac{1}{b-a}I(a\leq X_i\leq b)$,其中$I$是指示函数。为了最大化似然函数,需要使$b$尽可能小,同时保证所有的样本值都在区间$[a,b]$内。因此,b的最大似然估计是样本的最大值,即$b_{MLE}=max\{X_1,X_2,\cdots,X_n\}$。所以D选项正确。
矩估计是通过样本矩来估计总体参数的方法,而最大似然估计是通过最大化似然函数来估计参数的方法。对于均匀分布$XU(a,b)$,其概率密度函数为$f(x)=\frac{1}{b-a}$,其中$a\leq x\leq b$。
步骤 2:分析a的矩估计
对于均匀分布$XU(a,b)$,其均值$\mu=\frac{a+b}{2}$,方差$\sigma^2=\frac{(b-a)^2}{12}$。矩估计是通过样本均值和方差来估计总体参数。因此,a的矩估计不是直接通过样本的最小值或最大值来估计,而是通过样本均值和方差来估计。所以A和B选项都不正确。
步骤 3:分析b的最大似然估计
对于均匀分布$XU(a,b)$,其似然函数为$L(a,b)=\prod_{i=1}^{n}\frac{1}{b-a}I(a\leq X_i\leq b)$,其中$I$是指示函数。为了最大化似然函数,需要使$b$尽可能小,同时保证所有的样本值都在区间$[a,b]$内。因此,b的最大似然估计是样本的最大值,即$b_{MLE}=max\{X_1,X_2,\cdots,X_n\}$。所以D选项正确。