题目
下列关于抽样设计方法的描述中,错误的是()A.等距抽样仅在抽取第一个样本单元时采用随机抽取,后续样本单元随之确定,所以等距抽样的样本不满足随机性B.整群抽样虽然精度不高,但是实施非常便利,能够节省调查经费C.当总体IV越大时,实施不等概率抽样就会变得越复杂D.分层抽样精度较高,但要求构建层的抽样框,有时难以满足
下列关于抽样设计方法的描述中,错误的是()
A.等距抽样仅在抽取第一个样本单元时采用随机抽取,后续样本单元随之确定,所以等距抽样的样本不满足随机性
B.整群抽样虽然精度不高,但是实施非常便利,能够节省调查经费
C.当总体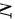 越大时,实施不等概率抽样就会变得越复杂
越大时,实施不等概率抽样就会变得越复杂
D.分层抽样精度较高,但要求构建层的抽样框,有时难以满足
题目解答
答案
A:先将总体的全部单元按照一定顺序排列,采用简单随机抽样抽取第一个样本单元(或称为随机起点),再顺序抽取其余的样本单元,这类抽样方法被称为等距抽样,且等距抽样也是属于随机抽样,所以等距抽样的样本具有随机性,故A错误;
B:整群抽样是指整群地抽选样本单位,对被抽选的各群进行全面调查的一种抽样组织方式。整群抽样的优点是实施方便、节省经费;缺点是往往由于不同群之间的差异较大,由此而引起的抽样误差往往大于简单随机抽样,且样本分布面不广、样本对总体的代表性相对较差。故B正确;
C:不等概率抽样是指在抽取样本之前给总体的每一个单元赋予一定的被抽中概率。不等概率抽样分为放回与不放回两种情况。有放回的不等概率中,最常用的是按总体单元的规模大小来确定抽选的概率。不放回的不等概率抽样,是指在抽样的过程中被抽中的单元不能再被抽中,因此在抽取了第一个单元之后,余下的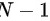 的单元中再以什么样的概率抽选就比较复杂。接着抽取第三和第四个单元时就面临更复杂的问题,因此抽样的实施比较困难。所以当总体越大时,实施不等概率抽样就会变得越复杂,故C正确;
的单元中再以什么样的概率抽选就比较复杂。接着抽取第三和第四个单元时就面临更复杂的问题,因此抽样的实施比较困难。所以当总体越大时,实施不等概率抽样就会变得越复杂,故C正确;
D:分层抽样法也叫类型抽样法。它是从一个可以分成不同子总体(或称为层)的总体中,按规定的比例从不同层中随机抽取样品(个体)的方法。这种方法的优点是,样本的代表性比较好,抽样误差比较小。缺点是抽样手续较简单随机抽样还要繁杂些。故D正确;
综上所述故选A
解析
步骤 1:等距抽样
等距抽样是指先将总体的全部单元按照一定顺序排列,采用简单随机抽样抽取第一个样本单元(或称为随机起点),再顺序抽取其余的样本单元。尽管后续样本单元是按照等距方式确定的,但第一个样本单元是随机抽取的,因此等距抽样的样本具有随机性。所以,选项A的描述是错误的。
步骤 2:整群抽样
整群抽样是指整群地抽选样本单位,对被抽选的各群进行全面调查的一种抽样组织方式。整群抽样的优点是实施方便、节省调查经费;缺点是往往由于不同群之间的差异较大,由此而引起的抽样误差往往大于简单随机抽样,且样本分布面不广、样本对总体的代表性相对较差。所以,选项B的描述是正确的。
步骤 3:不等概率抽样
不等概率抽样是指在抽取样本之前给总体的每一个单元赋予一定的被抽中概率。不等概率抽样分为放回与不放回两种情况。有放回的不等概率中,最常用的是按总体单元的规模大小来确定抽选的概率。不放回的不等概率抽样,是指在抽样的过程中被抽中的单元不能再被抽中,因此在抽取了第一个单元之后,余下的N-1的单元中再以什么样的概率抽选就比较复杂。接着抽取第三和第四个单元时就面临更复杂的问题,因此抽样的实施比较困难。所以当总体越大时,实施不等概率抽样就会变得越复杂。所以,选项C的描述是正确的。
步骤 4:分层抽样
分层抽样法也叫类型抽样法。它是从一个可以分成不同子总体(或称为层)的总体中,按规定的比例从不同层中随机抽取样品(个体)的方法。这种方法的优点是,样本的代表性比较好,抽样误差比较小。缺点是抽样手续较简单随机抽样还要繁杂些。所以,选项D的描述是正确的。
等距抽样是指先将总体的全部单元按照一定顺序排列,采用简单随机抽样抽取第一个样本单元(或称为随机起点),再顺序抽取其余的样本单元。尽管后续样本单元是按照等距方式确定的,但第一个样本单元是随机抽取的,因此等距抽样的样本具有随机性。所以,选项A的描述是错误的。
步骤 2:整群抽样
整群抽样是指整群地抽选样本单位,对被抽选的各群进行全面调查的一种抽样组织方式。整群抽样的优点是实施方便、节省调查经费;缺点是往往由于不同群之间的差异较大,由此而引起的抽样误差往往大于简单随机抽样,且样本分布面不广、样本对总体的代表性相对较差。所以,选项B的描述是正确的。
步骤 3:不等概率抽样
不等概率抽样是指在抽取样本之前给总体的每一个单元赋予一定的被抽中概率。不等概率抽样分为放回与不放回两种情况。有放回的不等概率中,最常用的是按总体单元的规模大小来确定抽选的概率。不放回的不等概率抽样,是指在抽样的过程中被抽中的单元不能再被抽中,因此在抽取了第一个单元之后,余下的N-1的单元中再以什么样的概率抽选就比较复杂。接着抽取第三和第四个单元时就面临更复杂的问题,因此抽样的实施比较困难。所以当总体越大时,实施不等概率抽样就会变得越复杂。所以,选项C的描述是正确的。
步骤 4:分层抽样
分层抽样法也叫类型抽样法。它是从一个可以分成不同子总体(或称为层)的总体中,按规定的比例从不同层中随机抽取样品(个体)的方法。这种方法的优点是,样本的代表性比较好,抽样误差比较小。缺点是抽样手续较简单随机抽样还要繁杂些。所以,选项D的描述是正确的。