题目
设总体X的分布律为X .-1 0 2-|||-p 2θ θ .https:/img.zuoyebang.cc/zyb_9ba32d6892d93b791d358ea6c1ca4a18.jpg-30其中X .-1 0 2-|||-p 2θ θ .https:/img.zuoyebang.cc/zyb_db1a918ca2541f738e34040fb8c003af.jpg-30是未知参数,现从总体中抽取一样本,样本值为X .-1 0 2-|||-p 2θ θ .https:/img.zuoyebang.cc/zyb_ff98ac9c26bf44bbfd415e4989017387.jpg-30,据此样本值求参数X .-1 0 2-|||-p 2θ θ .https:/img.zuoyebang.cc/zyb_db1a918ca2541f738e34040fb8c003af.jpg-30的矩估计值
设总体X的分布律为
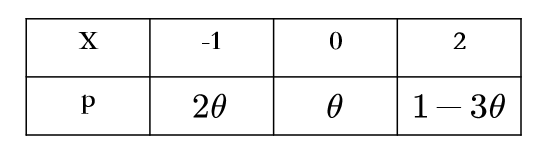
其中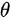 是未知参数,现从总体中抽取一样本,样本值为
是未知参数,现从总体中抽取一样本,样本值为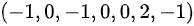 ,据此样本值求参数的矩估计值
,据此样本值求参数的矩估计值
题目解答
答案
对于离散型随机变量
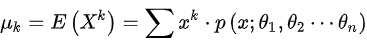
∴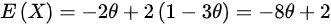
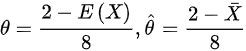

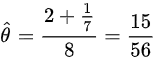
解析
矩估计法的核心思想是利用样本矩来估计总体矩。本题中,总体X为离散型随机变量,需通过一阶原点矩(期望)建立方程求解参数θ的估计值。
关键步骤:
- 计算总体期望:根据分布律,写出E(X)的表达式;
- 计算样本均值:对样本数据求平均;
- 联立方程求解:令总体期望等于样本均值,解方程得到θ的估计值。
1. 计算总体期望E(X)
根据分布律:
$E(X) = (-1) \cdot 2\theta + 0 \cdot \theta + 2 \cdot (1-3\theta) = -2\theta + 0 + 2 -6\theta = -8\theta + 2$
2. 计算样本均值$\overline{X}$
样本值为$(-1, 0, -1, 0, 0, 2, -1)$,共7个数据:
$\overline{X} = \frac{-1 + 0 + (-1) + 0 + 0 + 2 + (-1)}{7} = \frac{-1}{7} = -\frac{1}{7}$
3. 联立方程求解θ
令总体期望等于样本均值:
$-8\theta + 2 = -\frac{1}{7}$
解得:
$\theta = \frac{2 + \frac{1}{7}}{8} = \frac{15}{56}$