7标准分数有哪些用途?给出了一组数据中各数值的相对位置;并可以用它来判断一组数据是否有异常值。在对多个不同量纲的变量进行处理时,常常需要对各变量进行标准化处理。4.8为什么要计算离散系数?对于平均数不同或计量单位不同的不同组别的变量值,是不能用标准差直接比较其离散程度,为消除变量值水平高低和计量单位不同对离散程度测度值的影响,需要计算离散系数。7.2简述评价估计量好坏的标准?无偏性,指估计量抽样分布的数学期望等于被估计的总体参数;有效性,指对同一参数总体的两个无偏估计量,有更小标准的估计量更有效;一致性,随样本量的增大,点估计量的值越来越接近被估计总体的参数。7.5 Za/2δ/√(n)的含义是什么?Za/2δ/√(n)是估计总体均值时的估计误差。A是事先所确定的一个概率值,也被称为风险值,它是总体均值不包括在置信区间的概率,Za/2是标准正态分布上侧面积为a/2时的Z值8.3什么是假设检验中的两类错误?一类错误是原假设H0为真却被我们拒绝了,犯这种错误的概率用a表示,也称a错误或弃真错误;另一类错误是原假设为伪我们却没有拒绝,犯这种错误的概率用β表示,所以也称β错误或取伪错误。8.7假设检验依据的基本原理是什么?它的基本思想可以用小概率原理来解释.所谓小概率原理,就是认为小概率事件在一次试验中是几乎不可能发生的.也就是说,对总体的某个假设是真实的,那么不利于或不能支持这一假设的事件A在一次试验中是几乎不可能发一的;要是在一次试验中事件A竟然发生了,我们就有理由怀疑这一假设的真实性,拒绝这一假设.11.8一元线性回归模型中有哪些基本的假定?因变量y与自变量x之间具有线性关系;在重复抽样中,自变量x的取值是固定的,即假定x是非随机的;误差项ε是一个期望值为0的随机变量,即E(ε)=0;对于所有的x值,ε的方差&2都相同;误差项ε是一个服从正态分布的随机变量。11.10解释总平方和、回归平方合、残差平方和的含义,并说明它们之间的关系。对一个具体的观测值来说,变差的大小可以用实际观测值y与其均差来表示,而n次观察值的总变差可由这些离差的平方和来表示,称为总平方和(SST)。由于自变量x的变化引起的y的变化,而其平方和反映了Y的总变差中由于x与y之间的线性关系因其的y的变化部分,它是可以由回归直线来解释的变差部分,称为回归平方和(SSR)。除了x对y眼的线性影响之外的其他因素对y变差的作用,是不能由回归直线来解释的变差部分,称为残差平方和(SSE).关系:SST=SSR+SSE.11.11简述判定系数的含义和作用?判定系数是对估计的归回方程拟合优度的度量。判定系数R^2测度了回归直线对观测数据的拟合优度。取值范围[1,1]。越接近1,表明回归平方和占总平方和的比例越大,拟合程度越好,反之。11.14怎样评价回归分析的结果?所估计的回归系数^β1的符号是否与理论或事先预期相一致;如果理论上认为y与x之间的关系不仅是正的,而且是统计上显著的,那么所建立的回归方程也应该如此;回归方程多大程度上解释了因变量y取值的差异?考虑关于误差项ε的正态性假定是否成立。12.2多元回归模型中有哪些基本的假定?误差项ε是一个期望值为0的随机变量,即E(ε)=0;对自变量x1,x2,…,xk的所有值,ε的方差&^2都相同;误差项ε是一个服从正态分布的随机变量,且相互独立,即ε~N(0,&^2)12.3解释多重判定系数和调整的多重判定系数的含义和作用?是多元回归中的归回平方和占总平方和的比例,它是多元回归方程拟合优度的一个统计量,反映了在因变量y的变差中被估计的回归方程所解释的比例。为避免增加自变量而高估R^2,统计学家提出用样本量n和自变量的个数k去调整R^2,即调整的多重判定系数(Ra^2)。13.1简述时间序列的构成要素。成分分为四种,即趋势---是时间序列在长时期内呈现出来的某种持续向上或持续向下的变动(T)、季节性或者季节变动---是时间序列一年内重复出现的周期性波动(S),周期性或循环波动---时间序列中呈现出来的围绕长期趋势的一种波浪形或者振荡式变动(C),随机性或不规则变动(I)。。平稳序列是基本上不存在趋势的序列,这类序列中各观察值基本上在某个固定的水平上波动,虽然在不同的时间段波动的程度不同,但并不存在某种规律,波动可以看成是随机的。非平稳序列是包含趋势、季节性或周期性的序列,它可能只含有其中的一种成分,也可能是几种成分的组合。14.3拉氏指数与帕氏指数各有什么特点?拉氏指数:计算综合指数时将作为权数的同度量因素固定在基期;帕氏指数:计算综合指数时将作为权数的同度量因素固定在报告期。14.5什么是指数体系,它有什么作用?指数体系是指,一个总量往往可以分解成为若干个构成要素,其数量关系可以用指标体系的形式表现出来。反映了总量指标与因素指标之间的相互关系,它们之间的这种联系同样可以表现为各指标指数之间的联系。备注:11.10问题因为符号未能打出来,建议翻阅书籍进行背记,详见P315要求:(1)试根据上述资料编制频数分布数列。(2)编制向上和向下累计频数、频率数列。(3)根据所编制的向上(向下)累计频数(频率)数列绘制累计曲线图。(4)根据所编制的频数分布数列绘制直方图、折线图与曲线图,并说明其属于何种分布类型。(5)绘制茎叶图,并与直方图比较。.
7标准分数有哪些用途?
给出了一组数据中各数值的相对位置;并可以用它来判断一组数据是否有异常值。在对多个不同量纲的变量进行处理时,常常需要对各变量进行标准化处理。
4.8为什么要计算离散系数?
对于平均数不同或计量单位不同的不同组别的变量值,是不能用标准差直接比较其离散程度,为消除变量值水平高低和计量单位不同对离散程度测度值的影响,需要计算离散系数。
7.2简述评价估计量好坏的标准?
无偏性,指估计量抽样分布的数学期望等于被估计的总体参数;有效性,指对同一参数总体的两个无偏估计量,有更小标准的估计量更有效;一致性,随样本量的增大,点估计量的值越来越接近被估计总体的参数。
7.5 Za/2δ/√(n)的含义是什么?
Za/2δ/√(n)是估计总体均值时的估计误差。A是事先所确定的一个概率值,也被称为风险值,它是总体均值不包括在置信区间的概率,Za/2是标准正态分布上侧面积为a/2时的Z值
8.3什么是假设检验中的两类错误?
一类错误是原假设H0为真却被我们拒绝了,犯这种错误的概率用a表示,也称a错误或弃真错误;另一类错误是原假设为伪我们却没有拒绝,犯这种错误的概率用β表示,所以也称β错误或取伪错误。
8.7假设检验依据的基本原理是什么?
它的基本思想可以用小概率原理来解释.所谓小概率原理,就是认为小概率事件在一次试验中是几乎不可能发生的.也就是说,对总体的某个假设是真实的,那么不利于或不能支持这一假设的事件A在一次试验中是几乎不可能发一的;要是在一次试验中事件A竟然发生了,我们就有理由怀疑这一假设的真实性,拒绝这一假设.
11.8一元线性回归模型中有哪些基本的假定?
因变量y与自变量x之间具有线性关系;在重复抽样中,自变量x的取值是固定的,即假定x是非随机的;误差项ε是一个期望值为0的随机变量,即E(ε)=0;对于所有的x值,ε的方差&2都相同;误差项ε是一个服从正态分布的随机变量。
11.10解释总平方和、回归平方合、残差平方和的含义,并说明它们之间的关系。
对一个具体的观测值来说,变差的大小可以用实际观测值y与其均差来表示,而n次观察值的总变差可由这些离差的平方和来表示,称为总平方和(SST)。由于自变量x的变化引起的y的变化,而其平方和反映了Y的总变差中由于x与y之间的线性关系因其的y的变化部分,它是可以由回归直线来解释的变差部分,称为回归平方和(SSR)。除了x对y眼的线性影响之外的其他因素对y变差的作用,是不能由回归直线来解释的变差部分,称为残差平方和(SSE).关系:SST=SSR+SSE.
11.11简述判定系数的含义和作用?
判定系数是对估计的归回方程拟合优度的度量。判定系数R^2测度了回归直线对观测数据的拟合优度。取值范围[1,1]。越接近1,表明回归平方和占总平方和的比例越大,拟合程度越好,反之。
11.14怎样评价回归分析的结果?
所估计的回归系数^β1的符号是否与理论或事先预期相一致;如果理论上认为y与x之间的关系不仅是正的,而且是统计上显著的,那么所建立的回归方程也应该如此;回归方程多大程度上解释了因变量y取值的差异?考虑关于误差项ε的正态性假定是否成立。
12.2多元回归模型中有哪些基本的假定?
误差项ε是一个期望值为0的随机变量,即E(ε)=0;对自变量x1,x2,…,xk的所有值,ε的方差&^2都相同;误差项ε是一个服从正态分布的随机变量,且相互独立,即ε~N(0,&^2)
12.3解释多重判定系数和调整的多重判定系数的含义和作用?
是多元回归中的归回平方和占总平方和的比例,它是多元回归方程拟合优度的一个统计量,反映了在因变量y的变差中被估计的回归方程所解释的比例。为避免增加自变量而高估R^2,统计学家提出用样本量n和自变量的个数k去调整R^2,即调整的多重判定系数(Ra^2)。
13.1简述时间序列的构成要素。
成分分为四种,即趋势---是时间序列在长时期内呈现出来的某种持续向上或持续向下的变动(T)、季节性或者季节变动---是时间序列一年内重复出现的周期性波动(S),周期性或循环波动---时间序列中呈现出来的围绕长期趋势的一种波浪形或者振荡式变动(C),随机性或不规则变动(I)。
。
平稳序列是基本上不存在趋势的序列,这类序列中各观察值基本上在某个固定的水平上波动,虽然在不同的时间段波动的程度不同,但并不存在某种规律,波动可以看成是随机的。非平稳序列是包含趋势、季节性或周期性的序列,它可能只含有其中的一种成分,也可能是几种成分的组合。
14.3拉氏指数与帕氏指数各有什么特点?
拉氏指数:计算综合指数时将作为权数的同度量因素固定在基期;帕氏指数:计算综合指数时将作为权数的同度量因素固定在报告期。
14.5什么是指数体系,它有什么作用?
指数体系是指,一个总量往往可以分解成为若干个构成要素,其数量关系可以用指标体系的形式表现出来。反映了总量指标与因素指标之间的相互关系,它们之间的这种联系同样可以表现为各指标指数之间的联系。
备注:11.10问题因为符号未能打出来,建议翻阅书籍进行背记,详见P315
要求:(1)试根据上述资料编制频数分布数列。(2)编制向上和向下累计频数、频率数列。(3)根据所编制的向上(向下)累计频数(频率)数列绘制累计曲线图。(4)根据所编制的频数分布数列绘制直方图、折线图与曲线图,并说明其属于何种分布类型。(5)绘制茎叶图,并与直方图比较。
.题目解答
答案
解:(1)首先对上面的数据按数值大小进行排序,结果如下:
87 88 92 95 97 100 103 103 104 105 105 107 107 108 108 110 112 113 114 115
115 117 117 118 119 119 120 123 124 125 126 127 127 129 136 137 138 142 146 158
用最大值与最小值相减计算出全距:R=158—87=71元,对上述资料采用等距分组,分为8组,组距为10,以80为第一组下限。经过整理,得出计算结果如下表第一、二、三列所示。分组统计信息表
分组 | 频数 | 频率% | 向上累计频数 | 向下累计频数 | 向上累计频率 | 向下累计频率 |
80~90 90~100 100~110 110~120 120~130 130~140 140~150 150~160 合计 | 2 3 10 11 8 3 2 1 40 | 5 25 20 5 IOO | 2 5 15 26 34 37 39 40 — | 40 38 35 25 14 6 3 1 — | 5 65 85 100 — | 100 95 35 15 — |
(2)累计频数和累计频率见上表
(3)累计曲线图如下所示
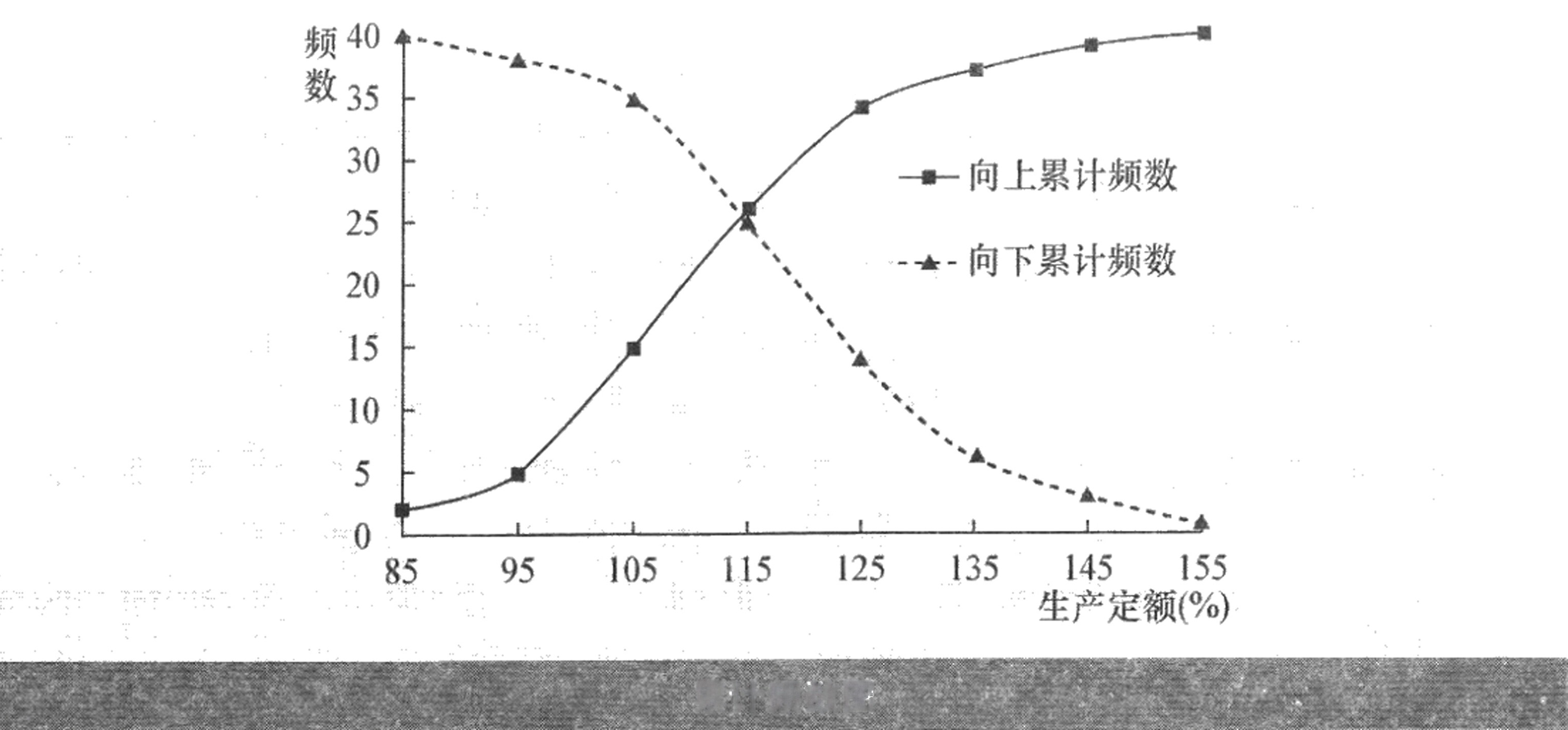
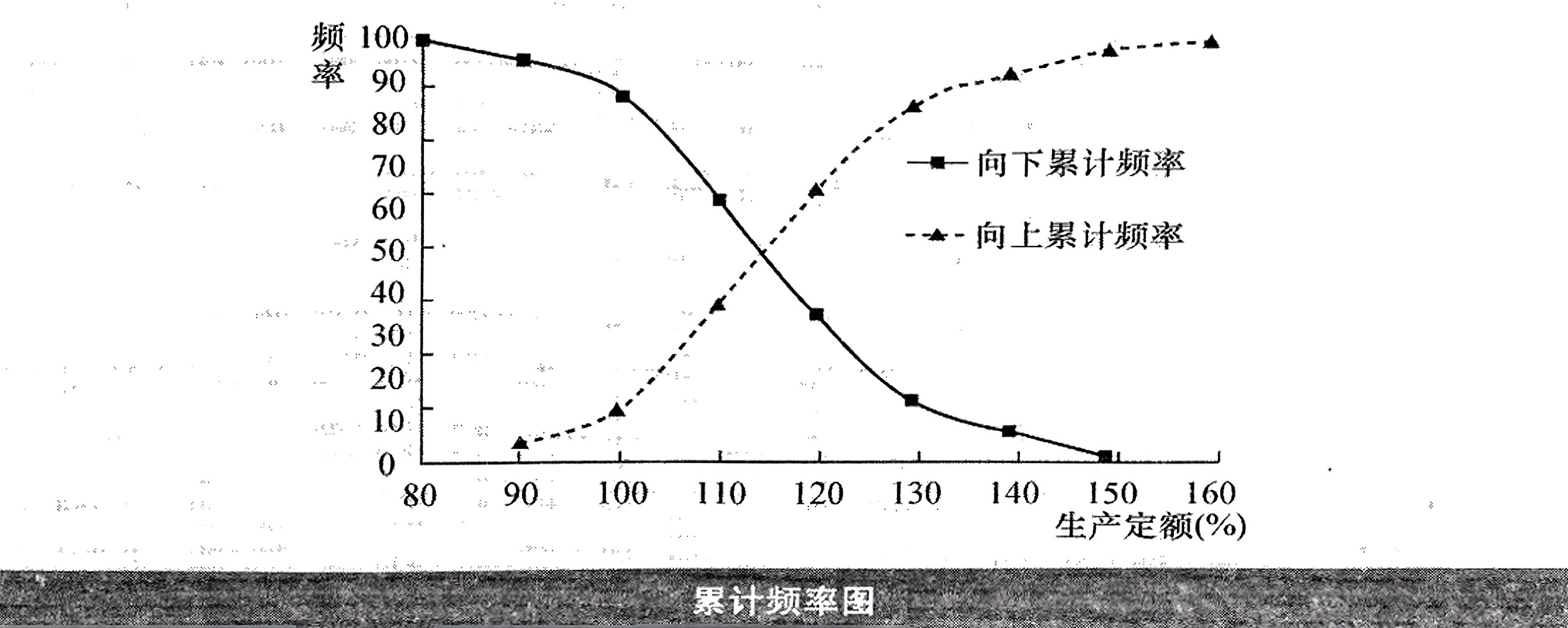
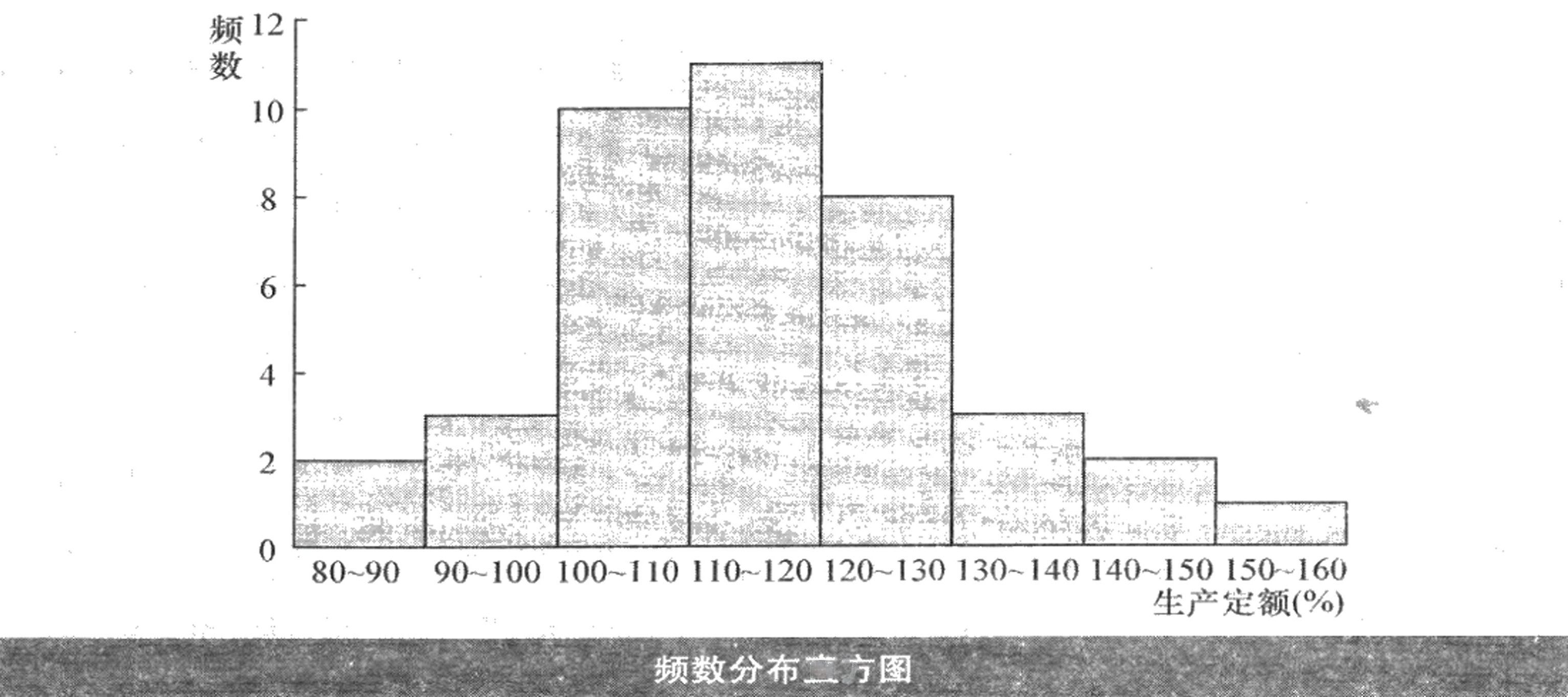
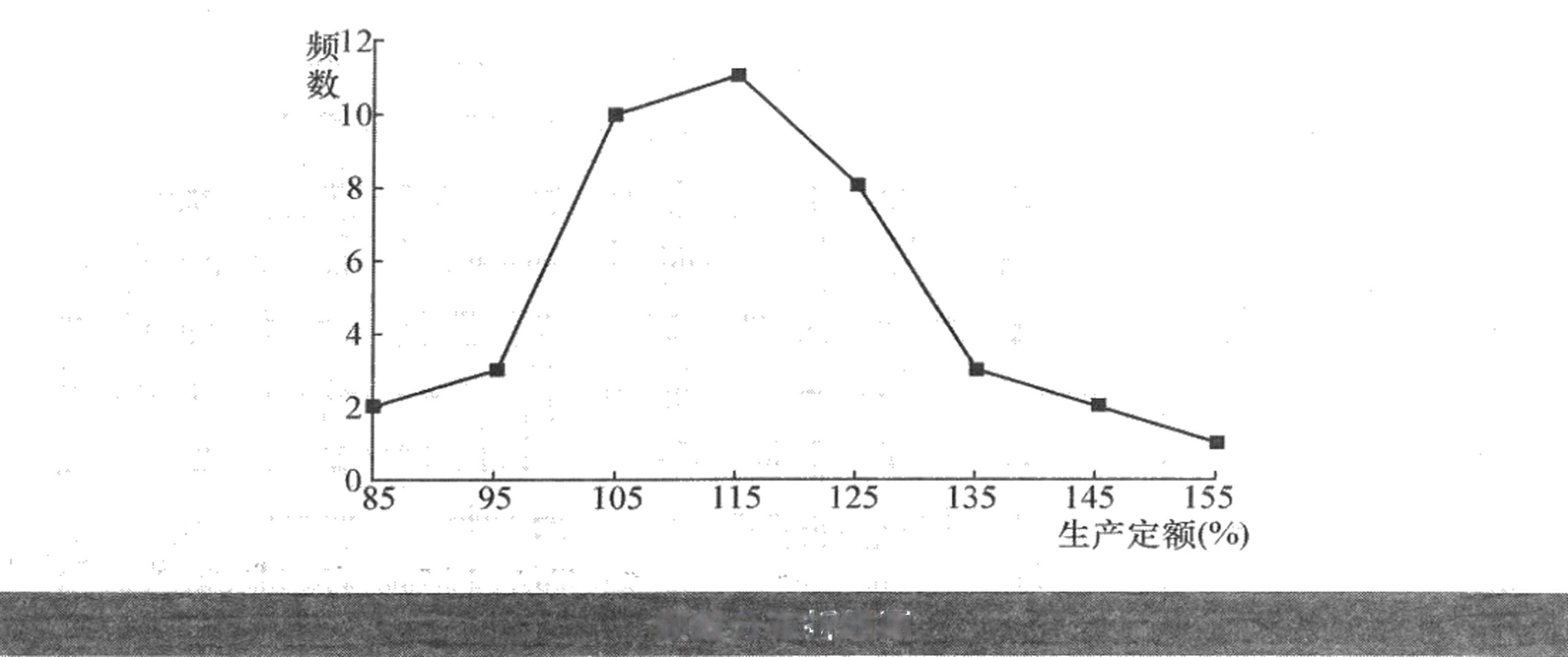
(4)直方图、折线图和曲线图如下面各图所示,分布属于钟形分布,呈现“中间大、两头小”的特征。
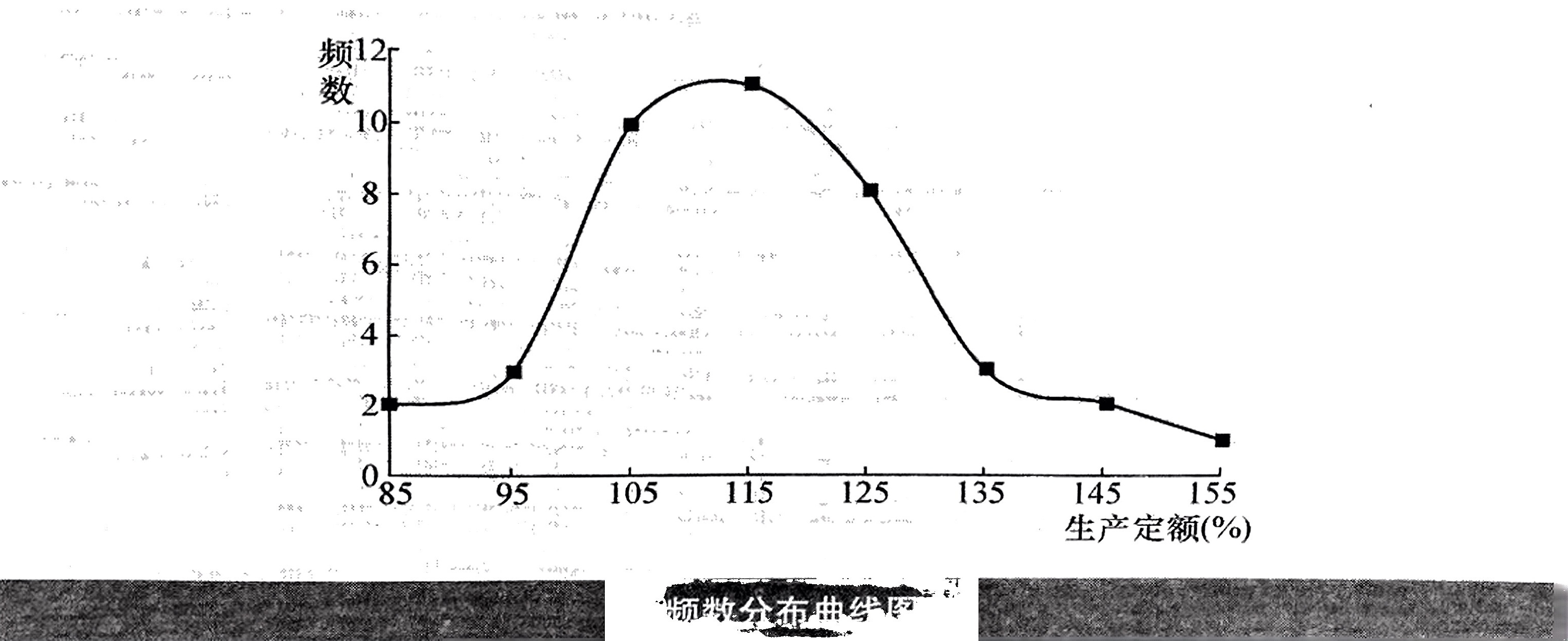
(5)茎叶图绘制如下,从分布形状上看,茎叶图与直方图相似,且茎叶图可以显示更详细的样本数据信息。
8 | 7 8 |
9 | 2 5 7 |
10 | 0 3 3 4 5 5 7 7 8 8 |
11 | 0 2 3 4 5 5 7 7 8 9 9 |
12 | 0 3 4 5 6 7 7 9 |
13 | 6 7 8 |
14 | 2 6 |
15 | 8 |