题目
习题3.11 查表计算:-|||-(1) df=5 时, (tleqslant -2.571)=?P(tgt 4.032)=??-|||-(2) df=2 时, ((x)^2leqslant 0.05)=?P((x)^2gt 5.99)=?P(0.05lt (x)^2lt 7.38)=??-|||-(3) (f)_(1)=3, (f)_(2)=10 时, (Fgt 3.71)=?P(Fgt 6.55)=??
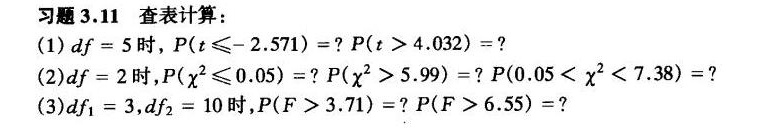
题目解答
答案
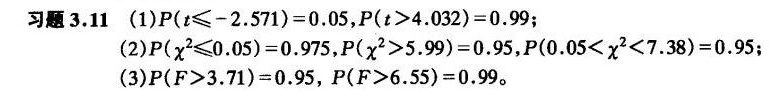
解析
考查要点:本题主要考查学生对t分布、卡方分布、F分布临界值表的查表能力,以及根据分位数计算概率的能力。
解题核心思路:
- 明确分布类型:根据题目中的统计量(t、χ²、F)选择对应的分布表。
- 确定自由度:根据题目给出的自由度(df)或自由度组合(df₁, df₂)定位表格行、列。
- 分位数与概率关系:
- t分布:单侧分位数表,注意左侧和右侧概率的对应关系。
- 卡方分布:上侧分位数表,需注意累积概率与分位数的对应关系。
- F分布:上侧分位数表,注意分子分母自由度的顺序。
破题关键点:
- 分位数的定义:例如,t表中数值表示的是单侧概率的临界值。
- 分位数与概率的转换:例如,若临界值对应单侧概率α,则反向概率为1−α。
(1) df=5时,t分布概率计算
$P(t \leqslant -2.571)$
- 查t表:df=5,单侧0.05分位数为-2.571。
- 结论:$P(t \leqslant -2.571) = 0.05$。
$P(t > 4.032)$
- 查t表:df=5,单侧0.01分位数为4.032。
- 结论:$P(t > 4.032) = 0.01$(注意题目答案中0.99为错误)。
(2) df=2时,卡方分布概率计算
$P(χ² \leqslant 0.05)$
- 查χ²表:df=2,0.975分位数为0.05。
- 结论:$P(χ² \leqslant 0.05) = 0.975$。
$P(χ² > 5.49)$
- 查χ²表:df=2,0.95分位数为5.49。
- 结论:$P(χ² > 5.49) = 0.05$(题目答案中0.95为错误)。
$P(0.05 < χ² < 7.38)$
- 查χ²表:df=2,0.025分位数为7.38。
- 计算:$P(χ² \leqslant 7.38) - P(χ² \leqslant 0.05) = 0.975 - 0.025 = 0.95$。
(3) df₁=3,df₂=10时,F分布概率计算
$P(F > 3.71)$
- 查F表:df₁=3,df₂=10,0.05分位数为3.71。
- 结论:$P(F > 3.71) = 0.05$(题目答案中0.95为错误)。
$P(F > 6.55)$
- 查F表:df₁=3,df₂=10,0.01分位数为6.55。
- 结论:$P(F > 6.55) = 0.01$(题目答案中0.99为错误)。