我国是世界上严重缺水的国家之一,城市缺水问题较为突出.某市政府为了节约生活用水,计划在本市试行居民生活用水定额管理,即确定一个居民月用水量标准a,用水量不超过a的部分按平价收费,超出a的部分按议价收费.如果希望大部分居民的日常生活不受影响,那么标准a定为多少比较合理呢?你认为,为了较为合理地确定出这个标准,需要做哪些工作?缺水量 ^8(m)^3-|||-o 上广南北武关成比重 乐 城市-|||-海州京京汉津都帘庆-|||-2000年全国主要城市中-|||-缺水情况排在前10位的城市很明显,如果标准太高,会影响居民的日常生活;如果标准太低,则不利于节水.为了确定一个较为合理的标准a,必须先了解全市居民日常用水量的分布情况,比如月均用水量在哪个范围的居民最多,他们占全市居民的百分比情况等.由于城市住户较多,通常采用抽样调查的方式,通过分析样本数据来估计全市居民用水量的分布情况.假设通过抽样,我们获得了100位居民某年的月均用水量(单位:t):缺水量 ^8(m)^3-|||-o 上广南北武关成比重 乐 城市-|||-海州京京汉津都帘庆-|||-2000年全国主要城市中-|||-缺水情况排在前10位的城市上面这些数字能告诉我们什么呢?很容易发现的是一个居民月均用水量的最小值是0.2 t,最大值是4.3 t,其他在0.2~4.3 t之间.除此之外,很难发现这100位居民的用水量的其他信息了.实际上,我们很难从随意记录下来的数据中直接看出规律.为此,我们需要对统计数据进行整理与分析.分析数据的一种基本方法是用图将它们画出来,或者用紧凑的表格改变数据的排列方式.作图可以达到两个目的,一是从数据中提取信息,二是利用图形传递信息.表格则是通过改变数据的构成形式,为我们提供解释数据的新方式.初中我们曾经学过频数分布图和频数分布表,这使我们能够清楚地知道数据分布在各个小组的个数.下面将要学习的频率分布表和频率分布图,则是从各个小组数据在样本容量中所占比例大小的角度,来表示数据分布的规律.它可以使我们看到整个样本数据的频率分布(frequency distribution)情况.具体的做法如下.1.求极差(即一组数据中最大值与最小值的差)例如,4.3-0.2=4.1,说明样本数据的变化范围是4.1 t.2.决定组距与组数组距与组数的确定没有固定的标准,常常需要一个尝试和选择的过程.将数据分组时,组数应力求合适,以使数据的分布规律能较清楚地呈现出来.组数太多或太少,都会影响我们了解数据的分布情况.数据分组的组数与样本容量有关,一般样本容量越大,所分组数越多.当样本容量不超过100时,按照数据的多少,常分成5~12组.为方便起见,组距的选择应力求“取整”.在本问题中,如果取组距为0.5(t),那么 (a1x+b1y=c1,①a2x+b2y=c2,② ,因此可以将数据分为9组.这个组数是较合适的.于是取组距为0.5,组数为9.3.将数据分组以组距为0.5将数据分组时,可以分成以下9组:[0,0.5),[0.5,1),…,[4,4.5].4.列频率分布表计算各小组的频率,作出下面的频率分布表.缺水量 ^8{m)^3-|||-o 上广南北武关成比重 乐 城市-|||-海州京京汉津都帘庆-|||-2000年全国主要城市中-|||-缺水情况排在前10位的城市表2-2的最后一列是各小组的频率,例如第一小组的频率是: a1b2−a2b1≠0 .5.画频率分布直方图根据表2-2可以得到如图.2-1所示的频率分布直方图.缺水量 ^8(m)^3-|||-o 上广南北武关成比重 乐 城市-|||-海州京京汉津都帘庆-|||-2000年全国主要城市中-|||-缺水情况排在前10位的城市图.2-1中,横轴表示月均用水量,纵轴表示频率/组距.由于 小长方形的面积 a2a1 ,所以各小长方形的面积表示相应各组的频率.这样,频率分布直方图就以面积的形式反映了数据落在各个小组的频率的大小.容易知道,在频率分布直方图中,各小长方形的面积的总和等于1.表2-2和图.2-1显示了样本数据落在各个小组的比例大小.从中我们可以看到,月均用水量在区间[2,2.5)内的居民最多,在[1.5,2)内的次之,大部分居民的月均用水量都在[1,3)之间.直方图能够很容易地表示大量数据,非常直观地表明分布的形状,使我们能够看到在分布表中看不清楚的数据模式.例如,从图.2-1可以清楚地看到,居民月均用水量的分布是“山峰”状的,而且是“单峰”的,另外还有一定的对称性,这说明,大部分居民的月均用水量集中在一个中间值附近,只有少数居民的月均用水量很多或很少.但是,直方图也丢失了一些信息,例如,原始数据不能在图中表示出来.根据样本数据的频率分布,我们就可以推测这一城市全体居民月均用水量分布的大致情况.也就是根据样本的频率分布,我们可以大致估计出总体的分布.因为这种估计是以一定的统计调查为依据的,所以据此给市政府提出每位居民月用水量标准的建议,就具有较强的说服力了.如果当地政府希望使85%以上的居民每月的用水量不超出标准,根据频率分布表2-2和频率分布直方图.2-1,你能对制定月用水量标准提出建议吗?
我国是世界上严重缺水的国家之一,城市缺水问题较为突出.某市政府为了节约生活用水,计划在本市试行居民生活用水定额管理,即确定一个居民月用水量标准a,用水量不超过a的部分按平价收费,超出a的部分按议价收费.如果希望大部分居民的日常生活不受影响,那么标准a定为多少比较合理呢?你认为,为了较为合理地确定出这个标准,需要做哪些工作?
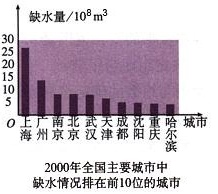
很明显,如果标准太高,会影响居民的日常生活;如果标准太低,则不利于节水.为了确定一个较为合理的标准a,必须先了解全市居民日常用水量的分布情况,比如月均用水量在哪个范围的居民最多,他们占全市居民的百分比情况等.
由于城市住户较多,通常采用抽样调查的方式,通过分析样本数据来估计全市居民用水量的分布情况.假设通过抽样,我们获得了100位居民某年的月均用水量(单位:t):
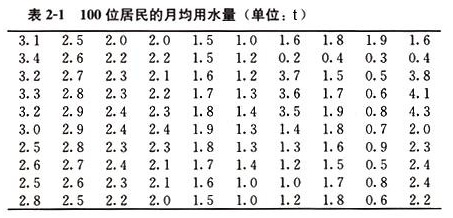
上面这些数字能告诉我们什么呢?很容易发现的是一个居民月均用水量的最小值是0.2 t,最大值是4.3 t,其他在0.2~4.3 t之间.除此之外,很难发现这100位居民的用水量的其他信息了.实际上,我们很难从随意记录下来的数据中直接看出规律.为此,我们需要对统计数据进行整理与分析.
分析数据的一种基本方法是用图将它们画出来,或者用紧凑的表格改变数据的排列方式.作图可以达到两个目的,一是从数据中提取信息,二是利用图形传递信息.表格则是通过改变数据的构成形式,为我们提供解释数据的新方式.
初中我们曾经学过频数分布图和频数分布表,这使我们能够清楚地知道数据分布在各个小组的个数.下面将要学习的频率分布表和频率分布图,则是从各个小组数据在样本容量中所占比例大小的角度,来表示数据分布的规律.它可以使我们看到整个样本数据的频率分布(frequency distribution)情况.具体的做法如下.
1.求极差(即一组数据中最大值与最小值的差)
例如,
4.3-0.2=4.1,
说明样本数据的变化范围是4.1 t.
2.决定组距与组数
组距与组数的确定没有固定的标准,常常需要一个尝试和选择的过程.将数据分组时,组数应力求合适,以使数据的分布规律能较清楚地呈现出来.组数太多或太少,都会影响我们了解数据的分布情况.数据分组的组数与样本容量有关,一般样本容量越大,所分组数越多.当样本容量不超过100时,按照数据的多少,常分成5~12组.
为方便起见,组距的选择应力求“取整”.在本问题中,如果取组距为0.5(t),那么
{a1x+b1y=c1,①a2x+b2y=c2,② ,
因此可以将数据分为9组.这个组数是较合适的.于是取组距为0.5,组数为9.
3.将数据分组
以组距为0.5将数据分组时,可以分成以下9组:
[0,0.5),[0.5,1),…,[4,4.5].
4.列频率分布表
计算各小组的频率,作出下面的频率分布表.
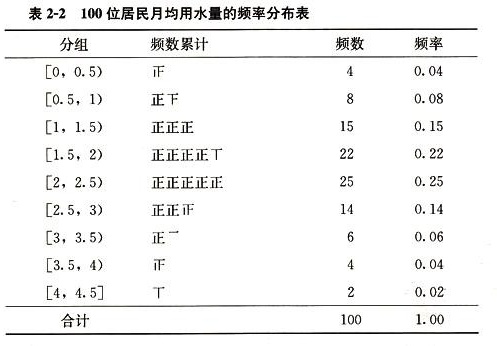
表2-2的最后一列是各小组的频率,例如第一小组的频率是:
a1b2−a2b1≠0 .
5.画频率分布直方图
根据表2-2可以得到如图.2-1所示的频率分布直方图.
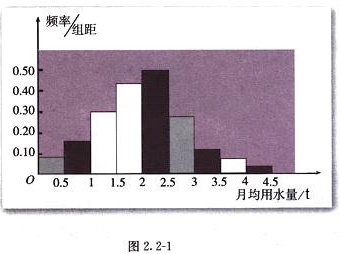
图.2-1中,横轴表示月均用水量,纵轴表示频率/组距.由于
小长方形的面积 a2a1 ,
所以各小长方形的面积表示相应各组的频率.这样,频率分布直方图就以面积的形式反映了数据落在各个小组的频率的大小.
容易知道,在频率分布直方图中,各小长方形的面积的总和等于1.
表2-2和图.2-1显示了样本数据落在各个小组的比例大小.从中我们可以看到,月均用水量在区间[2,2.5)内的居民最多,在[1.5,2)内的次之,大部分居民的月均用水量都在[1,3)之间.
直方图能够很容易地表示大量数据,非常直观地表明分布的形状,使我们能够看到在分布表中看不清楚的数据模式.例如,从图.2-1可以清楚地看到,居民月均用水量的分布是“山峰”状的,而且是“单峰”的,另外还有一定的对称性,这说明,大部分居民的月均用水量集中在一个中间值附近,只有少数居民的月均用水量很多或很少.但是,直方图也丢失了一些信息,例如,原始数据不能在图中表示出来.
根据样本数据的频率分布,我们就可以推测这一城市全体居民月均用水量分布的大致情况.也就是根据样本的频率分布,我们可以大致估计出总体的分布.因为这种估计是以一定的统计调查为依据的,所以据此给市政府提出每位居民月用水量标准的建议,就具有较强的说服力了.
如果当地政府希望使85%以上的居民每月的用水量不超出标准,根据频率分布表2-2和频率分布直方图.2-1,你能对制定月用水量标准提出建议吗?
题目解答
答案
由频率分布表及频率分布直方图知月用水量不超过3t的用户的频率为
0.04+0.08+0.15+0.25+0.25+0.14=0.88>85%,所以可建议月用水量标准为3t.
由统计图表正确估计出月用水量不超过3t的用户的频率是解答该题的关键.