题目
如果要从130人中检测出唯一的病毒携带者,使用二分法,需要进行的检测轮数为( )。A.6 B.7C.8D.9
如果要从130人中检测出唯一的病毒携带者,使用二分法,需要进行的检测轮数为( )。
A.6
B.7
C.8
D.9
题目解答
答案
解:C
解析:
在二分法中,我们每次都将待检测的人群分为两部分,并检测其中一部分。
如果检测的部分包含病毒携带者,则我们继续在这一部分中进行二分;
如果检测的部分不包含病毒携带者,则我们在另一部分中进行二分。
接下来,我们根据二分法的原理来计算需要的检测轮数:
初始时,有130人,即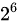 =64<130<
=64<130<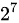 =128,所以至少需要7轮才能将人数减少到1人或0人(即找到或排除病毒携带者)。
=128,所以至少需要7轮才能将人数减少到1人或0人(即找到或排除病毒携带者)。
但是,我们需要注意到,当人数减少到小于或等于2人时,我们仍然需要一次检测来确定谁是病毒携带者(如果还存在的话)。
因此,虽然在第7轮结束后,人数可能减少到2人或更少,但我们还需要额外的1轮来确保找到病毒携带者。
所以,总共需要的检测轮数是7(用于减少人数到2人或更少)+ 1(用于确定最后的病毒携带者)= 8轮。
故答案为:C. 8。
解析
二分法的核心思想是通过每次将待检测人群分成两部分,逐步缩小病毒携带者的范围。本题的关键在于理解每轮检测后剩余人数的计算方式,以及何时需要额外一轮检测来确定最后的病毒携带者。
考查要点:
- 二分法的迭代过程:每次检测后,剩余人数约为当前人数的一半(向上取整)。
- 临界情况处理:当剩余人数为2时,仍需一轮检测来确定最终结果。
破题关键:
- 通过递推计算每轮剩余人数,直到人数减少到1。
- 注意当剩余人数为2时,必须进行额外一轮检测。
步骤1:计算每轮剩余人数
从130人开始,每轮检测后剩余人数如下:
- 第1轮:$\lceil \frac{130}{2} \rceil = 65$
- 第2轮:$\lceil \frac{65}{2} \rceil = 33$
- 第3轮:$\lceil \frac{33}{2} \rceil = 17$
- 第4轮:$\lceil \frac{17}{2} \rceil = 9$
- 第5轮:$\lceil \frac{9}{2} \rceil = 5$
- 第6轮:$\lceil \frac{5}{2} \rceil = 3$
- 第7轮:$\lceil \frac{3}{2} \rceil = 2$
- 第8轮:$\lceil \frac{2}{2} \rceil = 1$
步骤2:分析临界情况
当剩余人数为2时,需额外一轮检测来确定病毒携带者。因此,总轮数为8轮。