题目
对10名男生和10名女生的体重(单位:Kg)进行抽样调查,结果如下:男生组64566062《685452606561女生组525445@50484754554650(1) 现在要比较男生和女生的体重差异,应采用什么方法(2) 比较分析哪一组的体重差异大
对10名男生和10名女生的体重(单位:Kg)进行抽样调查,结果如下:
男生组
64
56
60
62
《
68
54
52
60
65
61
女生组
52
54
45
@
50
48
47
54
55
46
50
(1) 现在要比较男生和女生的体重差异,应采用什么方法
(2) 比较分析哪一组的体重差异大
题目解答
答案
解:(1) 采用离散系数进行比较;
<
(2) 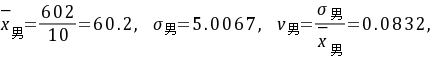
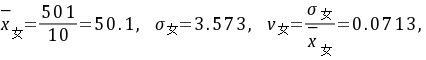
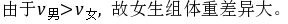 (男生组体重差异大)
(男生组体重差异大)
解析
考查要点:本题主要考查离散程度的比较方法,特别是如何通过离散系数来比较不同数据组的差异大小。
解题核心思路:
- 离散系数(标准差与平均值的比值)用于消除量纲影响,适合比较不同数据集的离散程度。
- 计算两组数据的平均值、标准差,再求离散系数,最后比较大小即可判断差异程度。
破题关键点:
- 明确直接比较标准差不可行(因两组平均值差异大),需用离散系数。
- 正确计算平均值、标准差,并注意标准差的计算方式(本题为总体标准差)。
第(1)题
方法选择:
由于男生和女生的体重平均值不同,直接比较标准差无法消除量纲影响。因此,应采用离散系数(标准差与平均值的比值)来比较两组的体重差异。
第(2)题
步骤解析:
1. 计算男生组数据
- 平均值:
$\overline{X}_{\text{男}} = \frac{64 + 56 + 60 + 62 + 68 + 54 + 52 + 60 + 65 + 61}{10} = \frac{602}{10} = 60.2$ - 标准差(总体标准差):
$s_{\text{男}} = \sqrt{\frac{\sum (x_i - \overline{X}_{\text{男}})^2}{10}} \approx 5.0067$ - 离散系数:
$V_{\text{男}} = \frac{s_{\text{男}}}{\overline{X}_{\text{男}}} = \frac{5.0067}{60.2} \approx 0.0832$
2. 计算女生组数据
- 平均值:
$\overline{X}_{\text{女}} = \frac{52 + 54 + 45 + 50 + 48 + 47 + 54 + 55 + 46 + 50}{10} = \frac{501}{10} = 50.1$ - 标准差(总体标准差):
$s_{\text{女}} = \sqrt{\frac{\sum (x_i - \overline{X}_{\text{女}})^2}{10}} \approx 3.573$ - 离散系数:
$V_{\text{女}} = \frac{s_{\text{女}}}{\overline{X}_{\text{女}}} = \frac{3.573}{50.1} \approx 0.0713$
3. 比较离散系数
- 结论:
$V_{\text{男}} = 0.0832 > V_{\text{女}} = 0.0713$
因此,男生组的体重差异更大。