某校高二年级共有1600名学生,其中男生960名,女生640名.该校组织了一次满分为100分的数学学业水平模拟考试.根据研究,在正式的学业水平考试中,本次成绩在[80,100]的学生可取得A等(优秀),在[60,80)的学生可取得B等(良好),在[40,60)的学生可取得C等(合格),在不到40分的学生只能取得D等(不合格).为研究这次考试成绩优秀是否与性别有关,现按性别采用分层抽样的方法抽取100名学生,将他们的成绩按从低到高分成[30,40)、[40,50)、[50,60)、[60,70)、[70,80)、[80,90)、[90,100]七组加以统计,绘制成频率分布直方图,下图是该频率分布直方图. 频率-|||-组距-|||-0.026-|||-0.024-|||-0.018 F-- -----|||-0.012-|||-0.006 --|||-0 30 40 50 60 70 80 90 100分数 (Ⅰ)估计该校高二年级学生在正式的数学学业水平考试中,成绩不合格的人数; (Ⅱ)请你根据已知条件将下列2×2列联表补充完整.并判断是否有90%的把握认为“该校高二年级学生在本次考试中数学成绩优秀与性别有关”? 数学成绩优秀 数学成绩不优秀 合计 男生 a=12 b= 女生 c= d=34 合计 n=100 附:({K)^2}=dfrac(n{{(ad-bc))^2}}((a+b)(c+d)(a+c)(b+d)) P(K^2 > k_(0)) 0.15 0.10 0.05 K_(0) 2.072 2.706 3.841
某校高二年级共有$1600$名学生,其中男生$960$名,女生$640$名$.$该校组织了一次满分为$100$分的数学学业水平模拟考试$.$根据研究,在正式的学业水平考试中,本次成绩在$[80,100]$的学生可取得$A$等$($优秀$)$,在$[60,80)$的学生可取得$B$等$($良好$)$,在$[40,60)$的学生可取得$C$等$($合格$)$,在不到$40$分的学生只能取得$D$等$($不合格$).$为研究这次考试成绩优秀是否与性别有关,现按性别采用分层抽样的方法抽取$100$名学生,将他们的成绩按从低到高分成$[30,40)$、$[40,50)$、$[50,60)$、$[60,70)$、$[70,80)$、$[80,90)$、$[90,100]$七组加以统计,绘制成频率分布直方图,下图是该频率分布直方图.
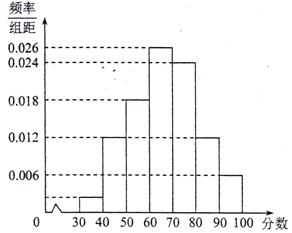
$($Ⅰ$)$估计该校高二年级学生在正式的数学学业水平考试中,成绩不合格的人数;
$($Ⅱ$)$请你根据已知条件将下列$2×2$列联表补充完整$.$并判断是否有$90%$的把握认为“该校高二年级学生在本次考试中数学成绩优秀与性别有关”?
| 数学成绩优秀 | 数学成绩不优秀 | 合计 |
男生 | $a=12$ | $b=$ | |
女生 | $c=$ | $d=34$ | |
合计 | | | $n=100$ |
附:${{K}^{2}}=\dfrac{n{{(ad-bc)}^{2}}}{(a+b)(c+d)(a+c)(b+d)}$
$P(K^{2} > k_{0})$ | $0.15$ | $0.10$ | $0.05$ |
$K_{0}$ | $2.072$ | $2.706$ | $3.841$ |
题目解答
答案
解:$($Ⅰ$)$ 抽取的$100$名学生中,本次考试成绩不合格的有$x$人,
根据题意得$x=100×[1-10×(0.006+0.012×2+0.018+0.024+0.026)]=2$
据此估计该校高二年级学生在正式的数学学业水平考试中,成绩不合格的人数为$ \dfrac{2}{100}×1600=32 ($人$)$.
$($Ⅱ$)$根据已知条件得$2×2$列联表如下:
数学成绩优秀 | 数学成绩不优秀 | 合计 | |
男生 | $a=12$ | $b=48$ | $60$ |
女生 | $c=6$ | $d=34$ | $40$ |
合计 | $18$ | $82$ | $n=100$ |
$∵{k}^{2}= \dfrac{100(12×34-6×48{)}^{2}}{18×82×40×60}≈0.407 < 2.706 $,
所以,没有$90\%$的把握认为“该校高二年级学生在本次考试中数学成绩优秀与性别有关”.
解析
根据频率分布直方图,成绩在$[30,40)$的频率为$0.006$,在$[40,50)$的频率为$0.012$,因此成绩不合格的频率为$0.006+0.012=0.018$。由于样本容量为$100$,所以成绩不合格的人数为$100\times0.018=1.8$,取整为$2$人。据此估计全校成绩不合格的人数为$\frac{2}{100}\times1600=32$人。
步骤 2:补充$2\times2$列联表
根据题意,男生$12$人成绩优秀,女生$34$人成绩不优秀,总人数为$100$人。因此,男生成绩不优秀的人数为$60-12=48$人,女生成绩优秀的人数为$100-60-34=6$人。
步骤 3:计算$K^2$值
根据$2\times2$列联表,计算$K^2$值为$\frac{100\times(12\times34-6\times48)^2}{18\times82\times60\times40}\approx0.407$。
步骤 4:判断是否有$90\%$的把握认为“该校高二年级学生在本次考试中数学成绩优秀与性别有关”
由于$0.407<2.706$,所以没有$90\%$的把握认为“该校高二年级学生在本次考试中数学成绩优秀与性别有关”。