题目
[二十四]某地区18岁的女青年的血压(收缩区,以mm-Hg计)服从N(110,12在该地区任选—18岁女青年,测量她的血压X。求(1)P(X≤105),P(100<X≤120).(2)确定最小的X使P(X>x)≤0.05
[二十四]某地区18岁的女青年的血压(收缩区,以mm-Hg计)服从N(110,12
在该地区任选—18岁女青年,测量她的血压X。求
(1)P(X≤105),P(100<X≤120).(2)确定最小的X使P(X>x)≤0.05
题目解答
答案
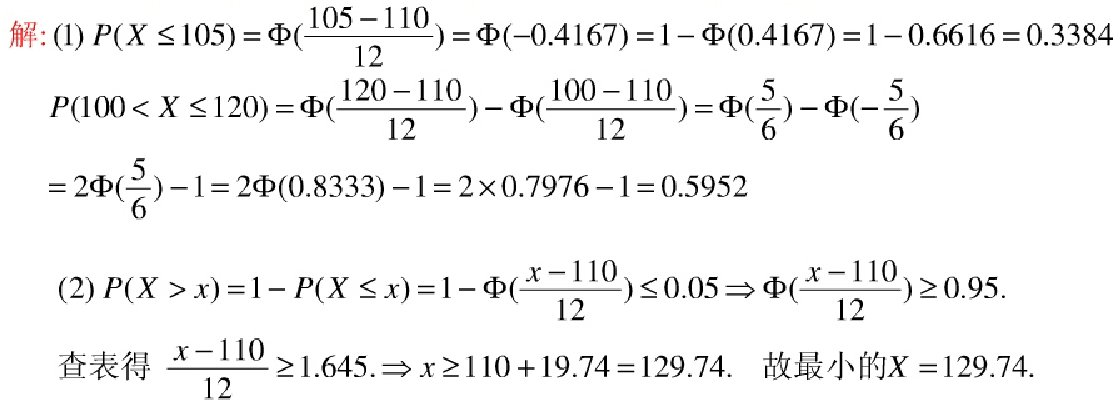
解析
考查要点:本题主要考查正态分布的概率计算及分位数的应用。
解题思路:
- 标准化转换:将实际观测值转化为标准正态分布变量$Z$,利用标准正态分布表查概率。
- 区间概率计算:通过上下限的标准化值之差求解区间概率。
- 分位数求解:根据概率要求反推对应的原始数据值,需注意分位数的查表方法。
关键点:
- 标准化公式:$Z = \frac{X - \mu}{\sigma}$
- 分位数对应关系:$P(X > x) = 0.05$对应标准正态分布的上侧$0.05$分位数$Z = 1.645$。
第(1)题
P(X ≤ 105)
- 标准化:
$Z = \frac{105 - 110}{12} = -0.4167$ - 查标准正态分布表:
$P(Z \leq -0.4167) = 1 - P(Z \leq 0.4167) = 1 - 0.6616 = 0.3384$
P(100 < X ≤ 120)
- 标准化上下限:
$Z_1 = \frac{100 - 110}{12} = -0.8333, \quad Z_2 = \frac{120 - 110}{12} = 0.8333$ - 计算概率差:
$P(Z \leq 0.8333) - P(Z \leq -0.8333) = 0.7976 - (1 - 0.7976) = 0.5952$
第(2)题
确定最小的X使P(X > x) ≤ 0.05
- 转化为标准正态分布:
$P\left(Z > \frac{x - 110}{12}\right) = 0.05$ - 查分位数:
上侧$0.05$分位数$Z = 1.645$,解得:
$\frac{x - 110}{12} = 1.645 \implies x = 110 + 1.645 \times 12 = 129.74$