题目
关于假设检验,下列说法正确的是()A 用单侧检验还是双侧检验要根据专业知识确定B 若p小于等于,则越有理由拒绝C 单侧检验优于双侧检验D 检验水准只能取0.05
关于假设检验,下列说法正确的是()
A 用单侧检验还是双侧检验要根据专业知识确定
B 若p小于等于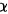 ,则越有理由拒绝
,则越有理由拒绝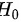
C 单侧检验优于双侧检验
D 检验水准只能取0.05
题目解答
答案
首先,使用单侧检验还是双侧检验要根据原假设与备择假设是什么,二者没有优劣之分。因此A、C错误。
其次,检验水准表示犯第一种错误的概率,主观取值,不是只能取0.05。因此D错误。
最后,p表示接受原假设的最大概率,p小于,则拒绝原假设。因此B正确。
所以选择B选项。
解析
步骤 1:理解假设检验的基本概念
假设检验是统计学中用于判断样本数据是否支持某个假设(原假设)的方法。在假设检验中,我们根据样本数据计算出一个统计量,并根据这个统计量的分布来判断原假设是否成立。原假设通常表示为\(H_0\),备择假设表示为\(H_1\)。
步骤 2:分析选项A
选项A提到,使用单侧检验还是双侧检验要根据专业知识确定。这是正确的。单侧检验和双侧检验的选择取决于研究者对备择假设的预期方向。如果研究者有明确的方向性预期(例如,新药的效果优于旧药),则使用单侧检验。如果研究者没有明确的方向性预期,则使用双侧检验。
步骤 3:分析选项B
选项B提到,若p值小于等于某个显著性水平(通常为0.05),则越有理由拒绝原假设\(H_0\)。这是正确的。p值是假设检验中用来衡量样本数据与原假设之间不一致程度的指标。如果p值小于显著性水平(如0.05),则认为样本数据与原假设之间的不一致程度足够大,从而拒绝原假设。
步骤 4:分析选项C
选项C提到,单侧检验优于双侧检验。这是不正确的。单侧检验和双侧检验没有优劣之分,它们的选择取决于研究者对备择假设的预期方向。
步骤 5:分析选项D
选项D提到,检验水准只能取0.05。这是不正确的。检验水准(显著性水平)是研究者根据研究需求主观设定的,可以是0.05,也可以是0.01、0.10等其他值。
假设检验是统计学中用于判断样本数据是否支持某个假设(原假设)的方法。在假设检验中,我们根据样本数据计算出一个统计量,并根据这个统计量的分布来判断原假设是否成立。原假设通常表示为\(H_0\),备择假设表示为\(H_1\)。
步骤 2:分析选项A
选项A提到,使用单侧检验还是双侧检验要根据专业知识确定。这是正确的。单侧检验和双侧检验的选择取决于研究者对备择假设的预期方向。如果研究者有明确的方向性预期(例如,新药的效果优于旧药),则使用单侧检验。如果研究者没有明确的方向性预期,则使用双侧检验。
步骤 3:分析选项B
选项B提到,若p值小于等于某个显著性水平(通常为0.05),则越有理由拒绝原假设\(H_0\)。这是正确的。p值是假设检验中用来衡量样本数据与原假设之间不一致程度的指标。如果p值小于显著性水平(如0.05),则认为样本数据与原假设之间的不一致程度足够大,从而拒绝原假设。
步骤 4:分析选项C
选项C提到,单侧检验优于双侧检验。这是不正确的。单侧检验和双侧检验没有优劣之分,它们的选择取决于研究者对备择假设的预期方向。
步骤 5:分析选项D
选项D提到,检验水准只能取0.05。这是不正确的。检验水准(显著性水平)是研究者根据研究需求主观设定的,可以是0.05,也可以是0.01、0.10等其他值。