题目
(三)。在某地区抽取的120家企业按利润额进行分组,结果如下:按利润额分组(万元)企业数(个)200~30019300~40030400~50042500~60018600以上11合计120计算120家企业利润额的均值和标准差。
(三)。在某地区抽取的120家企业按利润额进行分组,结果如下:
按利润额分组(万元) | 企业数(个) |
200~300 | 19 |
300~400 | 30 |
400~500 | 42 |
500~600 | 18 |
600以上 | 11 |
合计 | 120 |
计算120家企业利润额的均值和标准差。
题目解答
答案
解:设各组平均利润为 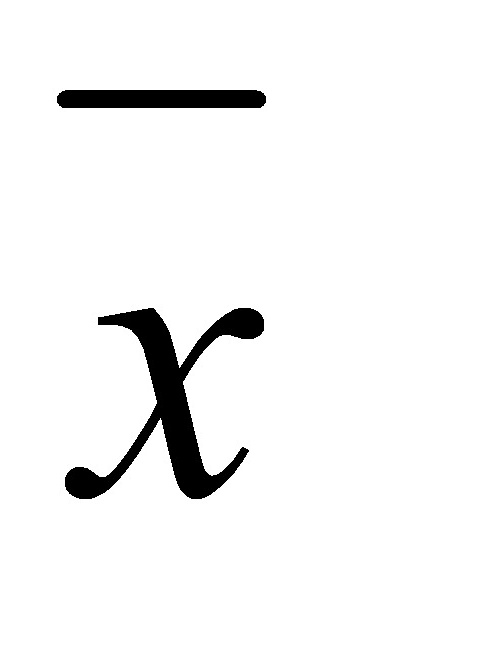 ,企业数为
,企业数为 ,则组总利润为
,则组总利润为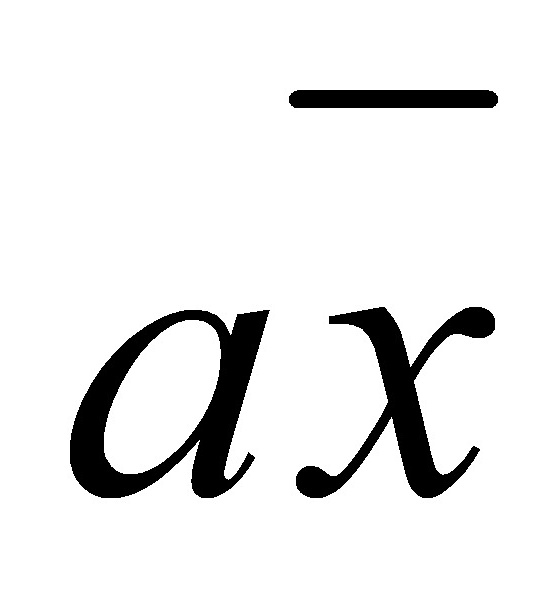 ,
,
,企业数为,则组总利润为,由于数据按组距式分组,须计算组中值作为各组平均利润,列表计算得:
按利润额分组(万元) | 组中值 | 企业数(个) | 总利润 |
200~300 | 250 | 19 | 4750 |
300~400 | 350 | 30 | 10500 |
400~500 | 450 | 42 | 18900 |
500~600 | 550 | 18 | 9900 |
600以上 | 650 | 11 | 7150 |
合计 | — | 120 | 51200 |
于是,120家企业平均利润为:
 = 426.67(万元);
= 426.67(万元);分组数据的标准差计算公式为:
s= 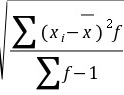
手动计算须列表计算各组数据离差平方和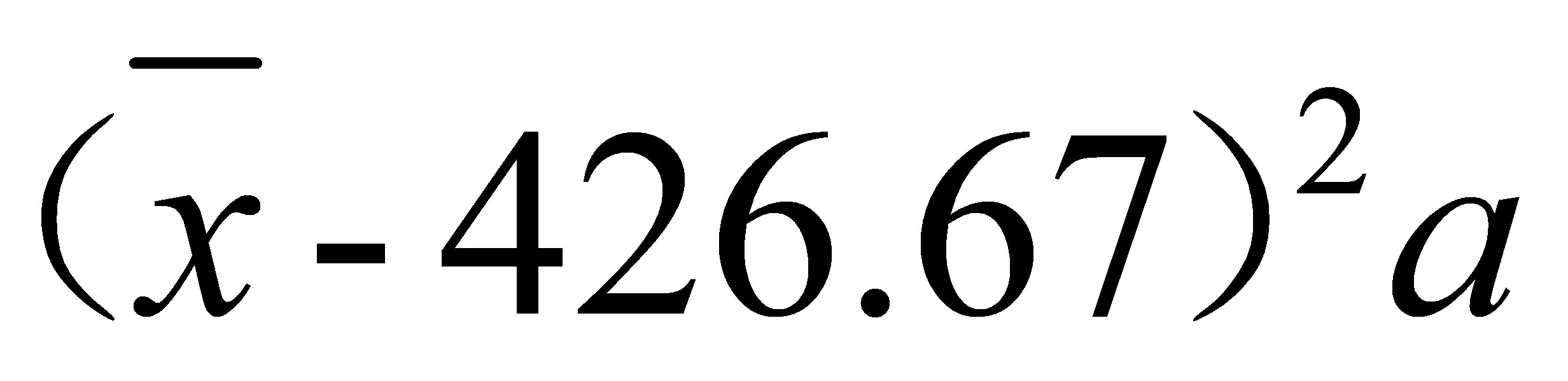 ,并求和,再代入计算公式:
,并求和,再代入计算公式:
,并求和,再代入计算公式:列表计算如下
组中值x | 企业数(个)a | (x—426.67)^2*a |
250 | 19 | 593033.4891 |
350 | 30 | 176348。667 |
450 | 42 | 22860.1338 |
550 | 18 | 273785。2002 |
650 | 11 | 548639.1779 |
合计 | 120 | 1614666。668 |
表格中的计算方法:
的计算方法:将表格复制到Excel表中,点击第三列的顶行单元格后,在输入栏中输入:=(a3-426.67)* (a3-426。67)*b3,回车,得到该行的计算结果;
点选结果所在单元格,并将鼠标移动到该单元格的右下方,当鼠标变成黑“+”字时,压下左键并拉动鼠标到该列最后一组数据对应的单元格处放开,则各组数据的(x-426。67)2f计算完毕;于是得标准差:s =116。48(万元)。
解析
步骤 1:计算各组的组中值
根据题目中给出的分组数据,计算各组的组中值。组中值是该组的上限和下限的平均值。
步骤 2:计算各组的总利润
将组中值与各组的企业数相乘,得到各组的总利润。
步骤 3:计算平均利润
将所有组的总利润相加,然后除以企业总数,得到平均利润。
步骤 4:计算标准差
使用分组数据的标准差计算公式,计算各组数据离差平方和,然后代入公式计算标准差。
根据题目中给出的分组数据,计算各组的组中值。组中值是该组的上限和下限的平均值。
步骤 2:计算各组的总利润
将组中值与各组的企业数相乘,得到各组的总利润。
步骤 3:计算平均利润
将所有组的总利润相加,然后除以企业总数,得到平均利润。
步骤 4:计算标准差
使用分组数据的标准差计算公式,计算各组数据离差平方和,然后代入公式计算标准差。