某批矿砂的5个样品中的镍含量(以%计),经测定为 3.25,3.27,3.24,3.26,3.24设测定值总体服从正态分布,但参数均未知,问在α=0.01下能否接受假设:这批矿砂的镍含量的均值为3.25?
某批矿砂的5个样品中的镍含量(以%计),经测定为
3.25,3.27,3.24,3.26,3.24
设测定值总体服从正态分布,但参数均未知,问在α=0.01下能否接受假设:这批矿砂的镍含量的均值为3.25?
题目解答
答案
解:
建立假设:
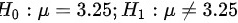
∵总体方差未知,且样本量n较小,所以应采用t统计量
已知n=5,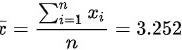 ,
,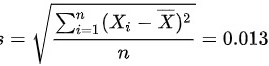
所以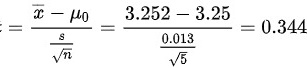 ,
,
由α=0.01和自由度n-1=4,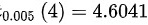
∵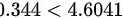
所以在α=0.01下接受原假设,即这批矿砂的镍含量的均值为3.25
解析
考查要点:本题主要考查单样本t检验的应用,用于检验正态分布总体均值是否等于某个假设值,尤其在总体方差未知且样本量较小的情况下。
解题核心思路:
- 建立假设:明确原假设($H_0$)和备择假设($H_1$)。
- 选择检验统计量:由于总体方差未知且样本量小($n=5$),采用t统计量。
- 计算样本均值和标准差:用于构造t统计量。
- 确定临界值:根据显著性水平$\alpha=0.01$和自由度$n-1=4$,查t分布表。
- 比较t值与临界值:判断是否拒绝原假设。
破题关键:
- 正确选择检验方法(t检验而非z检验)。
- 准确计算样本均值和标准差。
- 双侧检验的临界值需注意自由度和$\alpha/2$分位数。
建立假设
- 原假设:$H_0: \mu = 3.25$(镍含量均值为3.25%)
- 备择假设:$H_1: \mu \neq 3.25$(镍含量均值不等于3.25%)
计算样本均值
$\overline{x} = \frac{3.25 + 3.27 + 3.24 + 3.26 + 3.24}{5} = \frac{16.26}{5} = 3.252$
计算样本标准差
-
计算离差平方和:
$\begin{align*} (3.25-3.252)^2 &= 0.000004, \\ (3.27-3.252)^2 &= 0.000324, \\ (3.24-3.252)^2 &= 0.000144, \\ (3.26-3.252)^2 &= 0.000064, \\ (3.24-3.252)^2 &= 0.000144. \end{align*}$
总和为 $0.000004 + 0.000324 + 0.000144 + 0.000064 + 0.000144 = 0.00068$。 -
样本方差:
$s^2 = \frac{0.00068}{5-1} = 0.00017$ -
样本标准差:
$s = \sqrt{0.00017} \approx 0.013$
构造t统计量
$t = \frac{\overline{x} - \mu}{s/\sqrt{n}} = \frac{3.252 - 3.25}{0.013/\sqrt{5}} = \frac{0.002}{0.00581} \approx 0.344$
确定临界值
- 自由度 $df = n-1 = 4$,双侧检验下 $\alpha/2 = 0.005$。
- 查t分布表得临界值 $t_{0.005}(4) = 4.6041$。
做出决策
- 比较:$|t| = 0.344 < 4.6041$。
- 结论:不拒绝原假设,即在$\alpha=0.01$下,这批矿砂的镍含量均值为3.25%。