拟合优度[1]和统计检验拟合优度的度量:由表中可以看出本题中可决系数为0.,说明所建模型整体上对样本数据拟合度较好,即解释变量[2]“本市生产总值”对被解释变量“地方预算内财政收入”的绝大部分差异做出了解释。对回归系数的t检验:针对: 和:,由表中还可以看出,估计的回归系数的标准误差[3]和t值分别为:SE()=9.,t()=2.;的标准误差和t值分别为:SE()=0.,t()=26.10376。取ɑ=0.05,查t分布表得自由度[4]为n-2=18-2=16的临界值。因为t()=2.<,所以应拒绝: ;因为t()=26.10376>,所以应拒绝:。这表明,本市生产总值对地方预算内财政收入确有显著影响。2.41) . 模型设定[5]为了研究最终消费(Y)与国民总收入(X)的关系,作如下散点图从散点图可以看出最终消费(Y)和国民总收入(X)大体上呈现为线性关系[6],为分析最终消费随国民总收入变动的数量规律性,可以建立如下简单线性回归模型:(221.5775) (0.0457)t= (0.) (15.74411)=0.89526,F=247.8769(2).根据While检验,辅助函数为:,经经估计出现While检验结果,如表:从表中可以看出,=10.52295,由While检验知,在下,查分布表,得临界值,同时和的t检验值也显著,因为=10.52295>,表明模型确实存在异方差。分析该模型存在异方差的理由是,从数据可以看出,一是截面数据;二是各省市经济发展不平衡,使得一些省市农村居民收入高出其它省市很多,如上海市、北京市、天津市和浙江省等。而有的省就很低,如甘肃省、贵州省、云南省和陕西省等。(3).分别选用权数w1=1/x,w2=1/x^2,w3=1/sqr(x),经检验用权数的效果最好,用权数w3的结果如下:估计结果为:(190.6975) (0.)t = (2.) (14.58626)=0.,DW=1.,F=212.75915.4(1).(118.1625) (0.)t = (-5.) (17.34164)=0.91205,F=300.7324根据While检验,辅助函数为:,经经估计出现While检验结果,如表:从表中可以看出,=11.12883,由While检验知,在下,查分布表,得临界值,同时和的t检验值也显著,因为=11.12883>,表明模型确实存在异方差。(2).分别选用权数w1=1/x,w2=1/x^2,w3=1/sqr(x),经检验用权数的效果最好,用权数w3的结果如下:估计结果为:(87.89896) (0.)t = (-8.) (20.13992)=0.,DW=0.,F=405.61645.5(36196.79) (0.)t = (-0.80098) (20.82325)=0.,F=433.6076根据While检验,辅助函数为:,经经估计出现While检验结果,如表:从表中可以看出,=7.,由While检验知,在下,查分布表,得临界值,同时和的t检验值也显著,因为=7.>,表明模型确实存在异方差。分别选用权数w1=1/x,w2=1/x^2,w3=1/sqr(x),经检验用权数的效果最好,用权数w3的结果如下:估计结果为:(15289.93) (0.)t = (-0.) (17.60107)=0.,DW=2.,F=309.79785.6(18.07729) (0.)t = (3.) (70.33617)=0.,F=4947.177根据While检验,辅助函数为:,经经估计出现While检验结果,如表:从表中可以看出,=2.,由While检验知,在下,查分布表,得临界值,同时和的t检验值也显著,因为=2.>,表明模型确实存在异方差。分别选用权数w1=1/x,w2=1/x^2,w3=1/sqr(x),经检验用权数的效果最好,用权数w3的结果如下:估计结果为:(10.3865) (0.)t = (3.) (59.89897)=0.,DW=0.,F=3587.8876.1(1).根据数据其回归结果为:建立模型如下:(2.) (0.)t= (-3.) (125.3411)=0.,F=15710.39,DW=0.(2).其残差图如下:由残差图可知,残差的变动有系统模式,连续为正和连续为负,表明残差项可能存在一阶正自相关。对样本容量[7]为36、一个解释变量的模型、1%显著水平,查DW统计表可知,=1.026,=1.315,0<DW<,显然模型中存在自相关。(3) 对残差进行回归分析:回归方程为:对原模型进行广义差分,得广义差分方程:回归结果为:可得回归方程为:(1.) (0.)t= (-2.) (50.1682)=0.,F=2516.848,DW=2.其中=,=。由于使用了广义差分数据,样本容量减少了一个,为35个,查1%显著水平的DW统计表可知=1.195,=1.307,模型中DW>,说明模型在1%显著性水平[8]下广义差分模型已无自相关,不必再进行迭代。同时可见,可决系数,t,F统计量也均达到理想水平。由差分方程得:所以,最终模型为:6.3(1).根据数据其回归结果为:建立模型如下:(12.39919) (0.)t= (6.) (53.62068)=0.,F=2875.178,DW=0.其残差图如下:由残差图可知,残差的变动有系统模式,连续为正和连续为负,表明残差项可能存在一阶正自相关。对样本容量为19、一个解释变量的模型、1%显著水平,查DW统计表可知,=0.928,=1.132,0<DW<,显然模型中存在自相关。(2). 对残差进行回归分析:回归方程为:对原模型进行广义差分,得广义差分方程:回归结果为:可得回归方程为:(8.) (0.)t= (4.) (32.39512)=0.,F=1049.444,DW=1.其中=,=。由于使用了广义差分数据,样本容量减少了一个,为18个,查1%显著水平的DW统计表可知=0.902,=1.132,模型中DW>,说明模型在1%显著性水平下广义差分模型已无自相关,不必再进行迭代。同时可见,可决系数,t,F统计量也均达到理想水平。由差分方程得:所以,最终模型为:(3).其经济意义为:其经济意义为:北京市人均实际收入增加1元时,平均说来人均实际生活消费支出将增加0.元。6.4(1).根据数据其回归结果为:建立模型如下:(8.) (0.)t= (6.) (30.00846)=0.,F=900.5078,DW=0.其残差图如下:由残差图可知,残差的变动有系统模式,连续为正和连续为负,表明残差项可能存在一阶正自相关。对样本容量为25、一个解释变量的模型、1%显著水平,查DW统计表可知,=1.055,=1.211,0<DW<,显然模型中存在自相关。(2). 对残差进行回归分析:回归方程为:对原模型进行广义差分,得广义差分方程:回归结果为:可得回归方程为:(4.) (0.)t= (2.) (7.)=0.,F=51.1911,DW=2.37766其中=,=。由于使用了广义差分数据,样本容量减少了一个,为24个,查1%显著水平的DW统计表可知=1.037,=1.199,模型中DW>,说明模型在1%显著性水平下广义差分模型已无自相关,不必再进行迭代。同时可见,可决系数,t,F统计量也均达到理想水平。由差分方程得:所以,最终模型为:(3).模型说明日本工薪居民的边际消费倾向为0.,即收入每增加1元,平均说来消费增加0.元。
拟合优度[1]和统计检验
拟合优度的度量:由表中可以看出本题中可决系数为0.,说明所建模型整体上对样本数据拟合度较好,即解释变量[2]“本市生产总值”对被解释变量“地方预算内财政收入”的绝大部分差异做出了解释。
对回归系数的t检验:针对: 和:,由表中还可以看出,估计的回归系数的标准误差[3]和t值分别为:SE()=9.,t()=2.;的标准误差和t值分别为:SE()=0.,t()=26.10376。取ɑ=0.05,查t分布表得自由度[4]为n-2=18-2=16的临界值。因为t()=2.<,所以应拒绝: ;因为t()=26.10376>,所以应拒绝:。这表明,本市生产总值对地方预算内财政收入确有显著影响。
2.4
1) . 模型设定[5]
为了研究最终消费(Y)与国民总收入(X)的关系,作如下散点图
从散点图可以看出最终消费(Y)和国民总收入(X)大体上呈现为线性关系[6],为分析最终消费随国民总收入变动的数量规律性,可以建立如下简单线性回归模型:
(221.5775) (0.0457)
t= (0.) (15.74411)
=0.89526,F=247.8769
(2).根据While检验,辅助函数为:,经经估计出现While检验结果,如表:
从表中可以看出,=10.52295,由While检验知,在下,查分布表,得临界值,同时和的t检验值也显著,因为
=10.52295>,表明模型确实存在异方差。
分析该模型存在异方差的理由是,从数据可以看出,一是截面数据;二是各省市经济发展不平衡,使得一些省市农村居民收入高出其它省市很多,如上海市、北京市、天津市和浙江省等。而有的省就很低,如甘肃省、贵州省、云南省和陕西省等。
(3).分别选用权数w1=1/x,w2=1/x^2,w3=1/sqr(x),经检验用权数的效果最好,用权数w3的结果如下:
估计结果为:
(190.6975) (0.)
t = (2.) (14.58626)
=0.,DW=1.,F=212.7591
5.4
(1).
(118.1625) (0.)
t = (-5.) (17.34164)
=0.91205,F=300.7324
根据While检验,辅助函数为:,经经估计出现While检验结果,如表:
从表中可以看出,=11.12883,由While检验知,在下,查分布表,得临界值,同时和的t检验值也显著,因为
=11.12883>,表明模型确实存在异方差。
(2).分别选用权数w1=1/x,w2=1/x^2,w3=1/sqr(x),经检验用权数的效果最好,用权数w3的结果如下:
估计结果为:
(87.89896) (0.)
t = (-8.) (20.13992)
=0.,DW=0.,F=405.6164
5.5
(36196.79) (0.)
t = (-0.80098) (20.82325)
=0.,F=433.6076
根据While检验,辅助函数为:,经经估计出现While检验结果,如表:
从表中可以看出,=7.,由While检验知,在下,查分布表,得临界值,同时和的t检验值也显著,因为
=7.>,表明模型确实存在异方差。
分别选用权数w1=1/x,w2=1/x^2,w3=1/sqr(x),经检验用权数的效果最好,用权数w3的结果如下:
估计结果为:
(15289.93) (0.)
t = (-0.) (17.60107)
=0.,DW=2.,F=309.7978
5.6
(18.07729) (0.)
t = (3.) (70.33617)
=0.,F=4947.177
根据While检验,辅助函数为:,经经估计出现While检验结果,如表:
从表中可以看出,=2.,由While检验知,在下,查分布表,得临界值,同时和的t检验值也显著,因为=2.>,表明模型确实存在异方差。
分别选用权数w1=1/x,w2=1/x^2,w3=1/sqr(x),经检验用权数的效果最好,用权数w3的结果如下:
估计结果为:
(10.3865) (0.)
t = (3.) (59.89897)
=0.,DW=0.,F=3587.887
6.1
(1).根据数据其回归结果为:
建立模型如下:
(2.) (0.)
t= (-3.) (125.3411)
=0.,F=15710.39,DW=0.
(2).其残差图如下:
由残差图可知,残差的变动有系统模式,连续为正和连续为负,表明残差项可能存在一阶正自相关。
对样本容量[7]为36、一个解释变量的模型、1%显著水平,查DW统计表可知,=1.026,=1.315,0<DW<,显然模型中存在自相关。
(3) 对残差进行回归分析:
回归方程为:
对原模型进行广义差分,得广义差分方程:
回归结果为:
可得回归方程为:
(1.) (0.)
t= (-2.) (50.1682)
=0.,F=2516.848,DW=2.
其中=,=。
由于使用了广义差分数据,样本容量减少了一个,为35个,查1%显著水平的DW统计表可知=1.195,=1.307,模型中DW>,说明模型在1%显著性水平[8]下广义差分模型已无自相关,不必再进行迭代。同时可见,可决系数,t,F统计量也均达到理想水平。
由差分方程得:
所以,最终模型为:
6.3
(1).根据数据其回归结果为:
建立模型如下:
(12.39919) (0.)
t= (6.) (53.62068)
=0.,F=2875.178,DW=0.
其残差图如下:
由残差图可知,残差的变动有系统模式,连续为正和连续为负,表明残差项可能存在一阶正自相关。
对样本容量为19、一个解释变量的模型、1%显著水平,查DW统计表可知,=0.928,=1.132,0<DW<,显然模型中存在自相关。
(2). 对残差进行回归分析:
回归方程为:
对原模型进行广义差分,得广义差分方程:
回归结果为:
可得回归方程为:
(8.) (0.)
t= (4.) (32.39512)
=0.,F=1049.444,DW=1.
其中=,=。
由于使用了广义差分数据,样本容量减少了一个,为18个,查1%显著水平的DW统计表可知=0.902,=1.132,模型中DW>,说明模型在1%显著性水平下广义差分模型已无自相关,不必再进行迭代。同时可见,可决系数,t,F统计量也均达到理想水平。
由差分方程得:
所以,最终模型为:
(3).其经济意义为:其经济意义为:北京市人均实际收入增加1元时,平均说来人均实际生活消费支出将增加0.元。
6.4
(1).根据数据其回归结果为:
建立模型如下:
(8.) (0.)
t= (6.) (30.00846)
=0.,F=900.5078,DW=0.
其残差图如下:
由残差图可知,残差的变动有系统模式,连续为正和连续为负,表明残差项可能存在一阶正自相关。
对样本容量为25、一个解释变量的模型、1%显著水平,查DW统计表可知,=1.055,=1.211,0<DW<,显然模型中存在自相关。
(2). 对残差进行回归分析:
回归方程为:
对原模型进行广义差分,得广义差分方程:
回归结果为:
可得回归方程为:
(4.) (0.)
t= (2.) (7.)
=0.,F=51.1911,DW=2.37766
其中=,=。
由于使用了广义差分数据,样本容量减少了一个,为24个,查1%显著水平的DW统计表可知=1.037,=1.199,模型中DW>,说明模型在1%显著性水平下广义差分模型已无自相关,不必再进行迭代。同时可见,可决系数,t,F统计量也均达到理想水平。
由差分方程得:
所以,最终模型为:
(3).模型说明日本工薪居民的边际消费倾向为0.,即收入每增加1元,平均说来消费增加0.元。
题目解答
答案
拟合优度和统计检验
拟合优度的度量:由表中可以看出本题中可决系数为0.,说明所建模型整体上对样本数据拟合度较好,即解释变量“国民总收入”对被解释变量“最终消费”的绝大部分差异做出了解释。
对回归系数的t检验:针对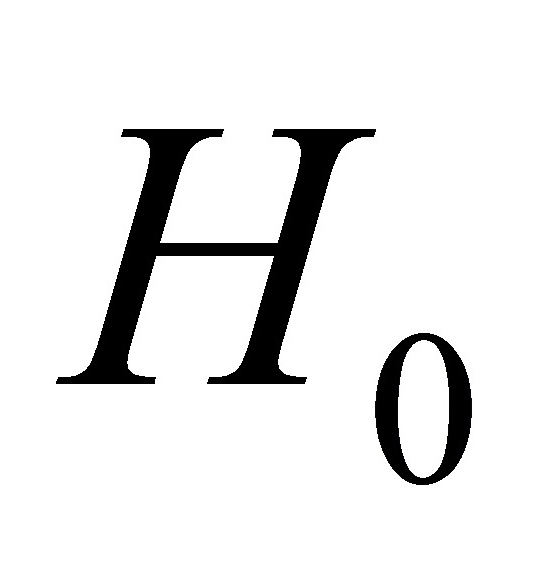 :
: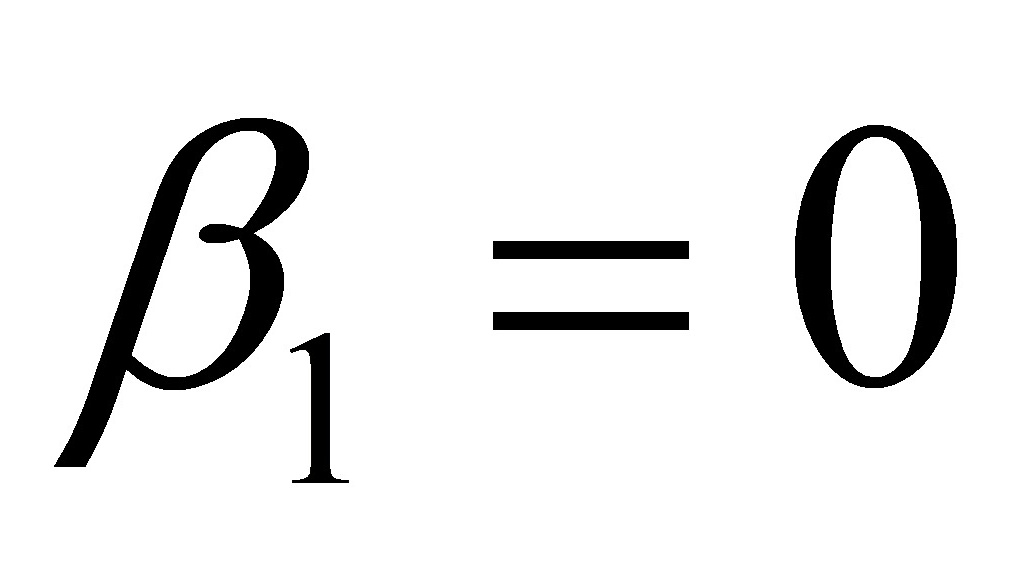 和:
和: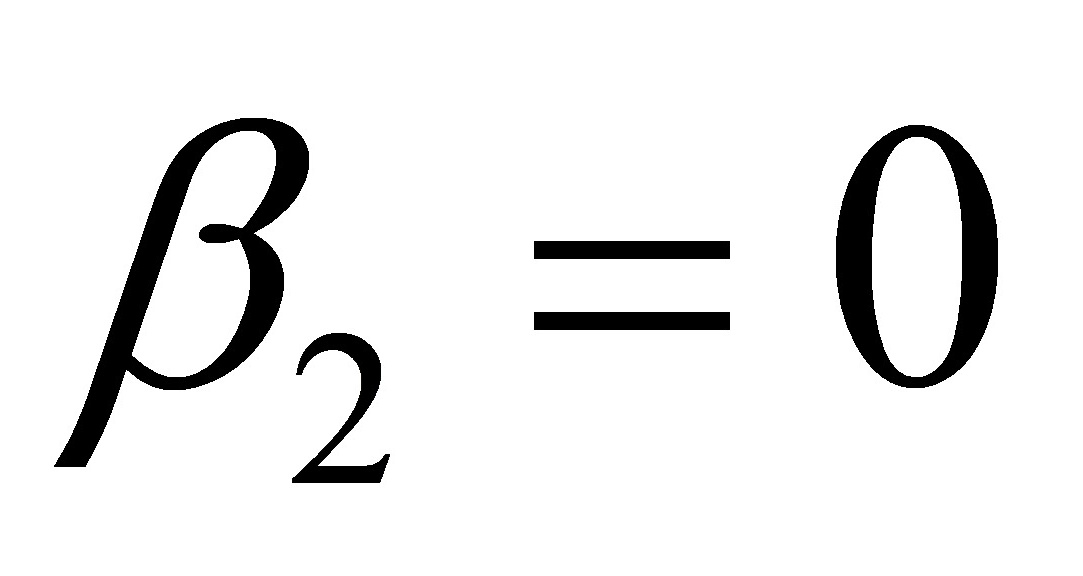 ,由表中还可以看出,估计的回归系数
,由表中还可以看出,估计的回归系数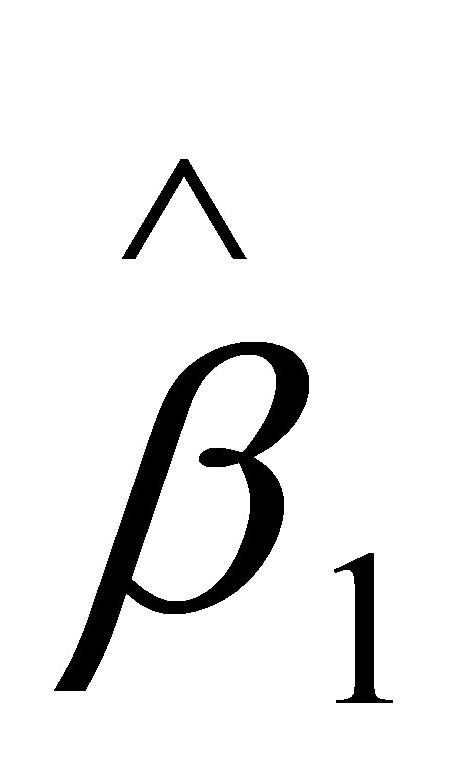 的标准误差和t值分别为:SE()=895.4040,t()=3.;
的标准误差和t值分别为:SE()=895.4040,t()=3.;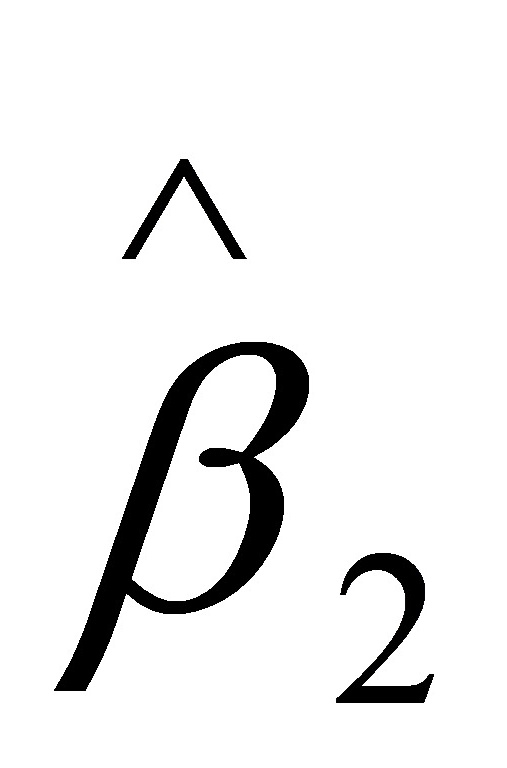 的标准误差和t值分别为:SE()=0.,t()=54.82076。取ɑ=0.05,查t分布表得自由度为n-2=30-2=28的临界值
的标准误差和t值分别为:SE()=0.,t()=54.82076。取ɑ=0.05,查t分布表得自由度为n-2=30-2=28的临界值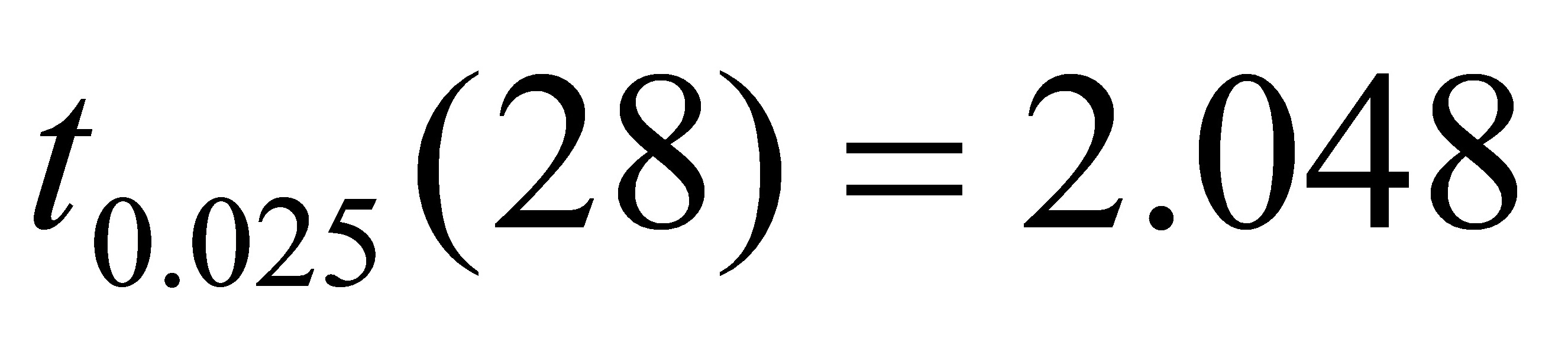 。因为t()=3.>,所以应拒绝: ;因为t()=54.82076>,所以应拒绝:。这表明,国民总收入对最终消费确有显著影响。
。因为t()=3.>,所以应拒绝: ;因为t()=54.82076>,所以应拒绝:。这表明,国民总收入对最终消费确有显著影响。
2.5
1). 模型设定
选择“航班正点率”为解释变量(用X表示),“每10万乘客投诉一次的投诉率”为被解释变量(用Y表示)。为了研究航班正点率(X)与每10万乘客投诉一次的投诉率(Y)的关系,作如下散点图:
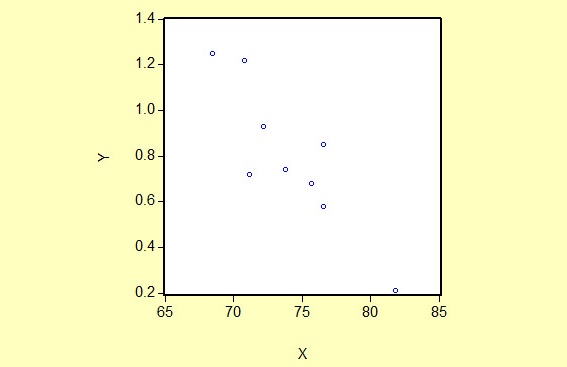
从散点图可以看出投诉率(Y)和航班正点率(X)大体上呈现为负相关关系,为分析投诉率随航班正点率变动的数量规律性,可以建立如下简单线性回归模型:
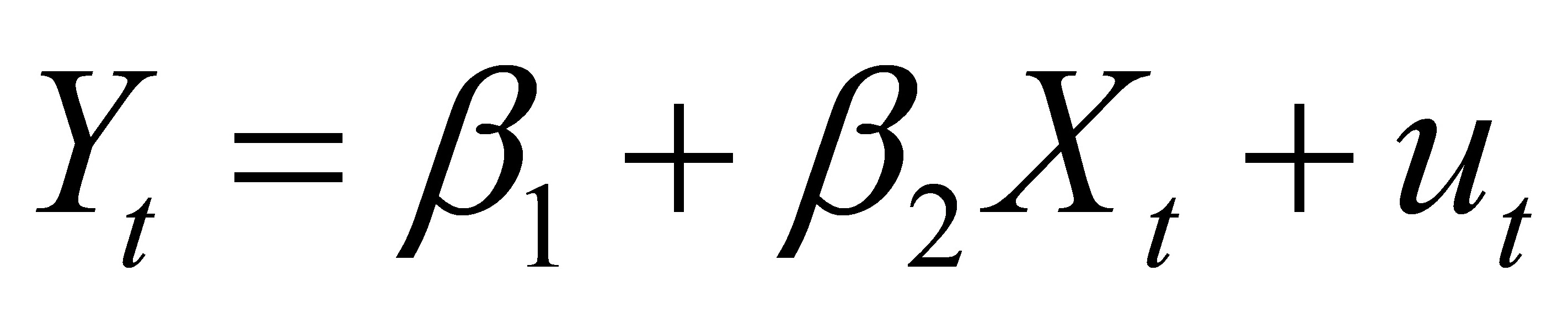
2). 估计参数
假定所建模型及其中的随机扰动项uᵢ满足各项古典假设,用EViews软件分析的回归结果如下表所示:
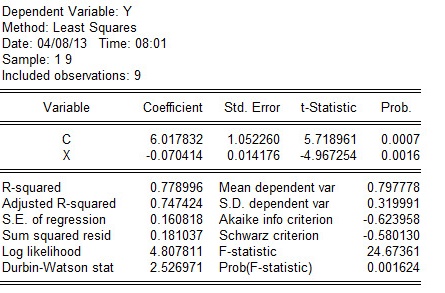
可用规范的形式将参数估计和检验的结果写为
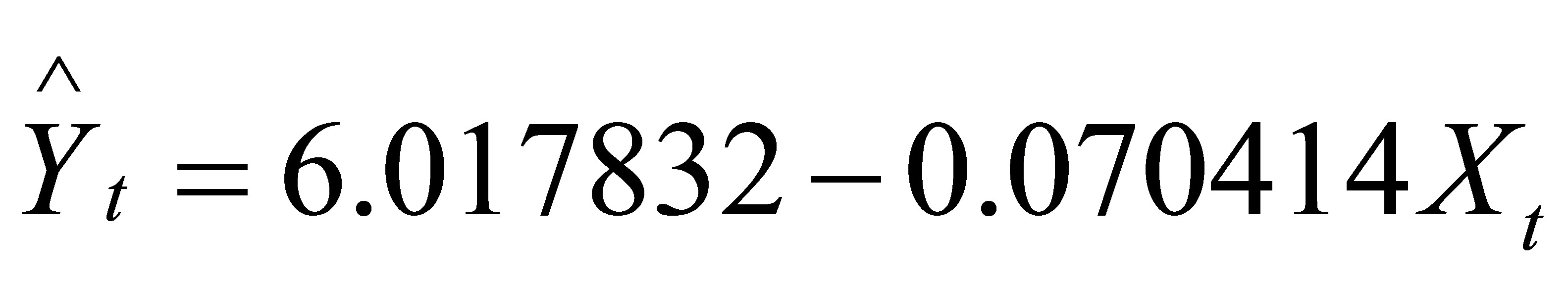
(1.)(0.)
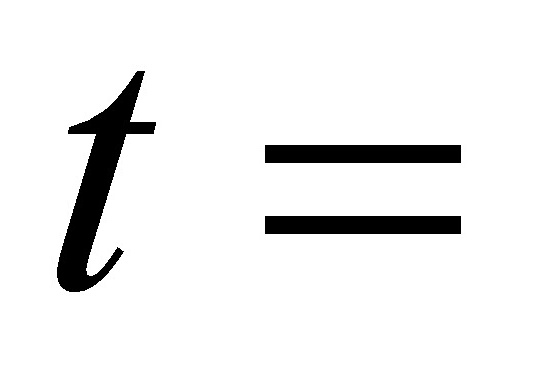 (5.) (-4.)
(5.) (-4.)
R2 = 0. F=24.67361 n=9
从表中可以看出航班正点率对投诉率确有显著影响,本题中可决系数为0.,说明所建模型整体上对样本数据拟合度较好,即解释变量“航班正点率”对被解释变量“投诉率”的绝大部分差异做出了解释。
所估计的参数=6.,=-0.,说明航班正点率每下降一个百分点,平均说来可导致投诉率增加0.个百分点
2.6
1) . 模型设定
为了研究某年公益股票的每股账面价值(Y)与当年红利(X)的关系,作如下散点图
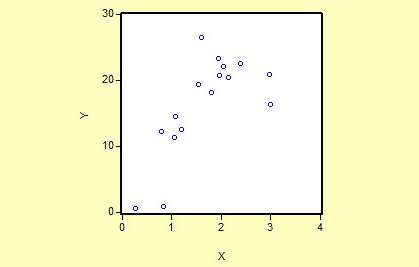
从散点图可以看出每股账面价值(Y)和当年红利(X)大体上呈现为一定的相关关系,为分析每股账面价值随当年红利变动的数量规律性,可以建立如下简单线性回归模型:
2). 估计参数
假定所建模型及其中的随机扰动项uᵢ满足各项古典假设,用EViews软件分析的回归结果如下表所示:
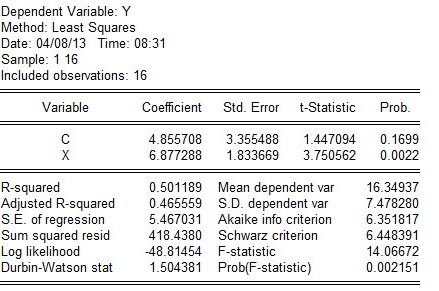
可用规范的形式将参数估计和检验的结果写为
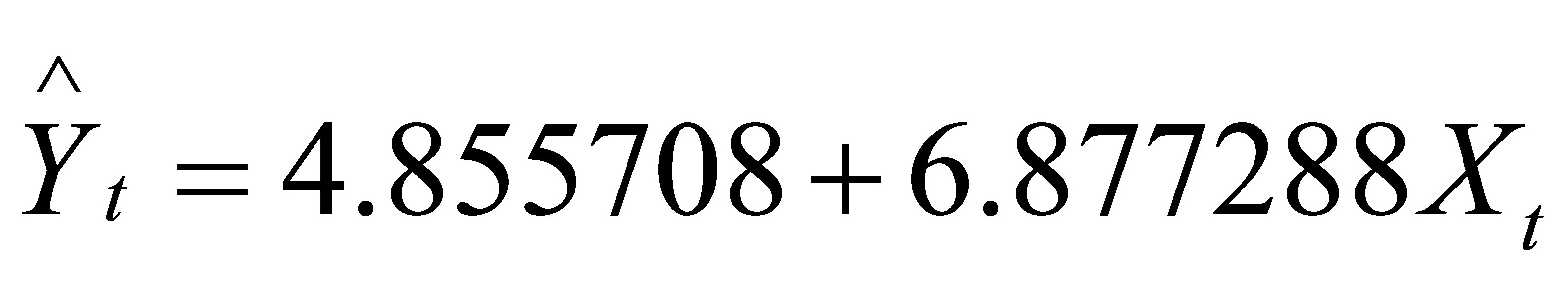
(3.)(1.)
(1.) (3.)
R2 = 0. n=16
3). 模型检验