题目
设随机变量的概率密度为,则A.N ( -2 , 2 )B.N ( -2 , 4 ) C.N ( -2 , 8 ) D.N ( -2 , 16 )
设随机变量 的概率密度为
的概率密度为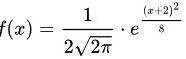 ,则
,则
A.
N ( -2 , 2 )
B.
N ( -2 , 4 )
C.
N ( -2 , 8 )
D.
N ( -2 , 16 )
题目解答
答案
已知正态分布的密度函数为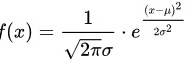 ,而的概率密度为,
,而的概率密度为,
∴不难看出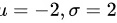
∴服从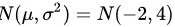 ,
,
∴正确答案为B
解析
考查要点:本题主要考查正态分布的概率密度函数形式,需要根据给定的密度函数识别均值$\mu$和方差$\sigma^2$。
解题核心思路:
- 对比标准正态分布密度函数:标准形式为$f(x)=\dfrac{1}{\sigma \sqrt{2\pi}} e^{-\dfrac{(x-\mu)^2}{2\sigma^2}}$。
- 匹配系数和指数部分:通过题目中的系数$\dfrac{1}{2\sqrt{2\pi}}$确定$\sigma$,通过指数部分$\dfrac{(x+2)^2}{8}$确定$\mu$和$\sigma^2$。
破题关键点:
- 指数部分的分母对应关系:题目中的分母$8$对应标准形式中的$2\sigma^2$,从而求出$\sigma^2=4$。
- 均值$\mu$的符号处理:指数中的$(x+2)$等价于$(x-\mu)$,因此$\mu=-2$。
步骤1:对比系数部分
标准正态分布的系数为$\dfrac{1}{\sigma \sqrt{2\pi}}$,题目中的系数为$\dfrac{1}{2\sqrt{2\pi}}$。
通过等式$\dfrac{1}{\sigma \sqrt{2\pi}} = \dfrac{1}{2\sqrt{2\pi}}$,解得$\sigma=2$。
步骤2:分析指数部分
标准正态分布的指数为$-\dfrac{(x-\mu)^2}{2\sigma^2}$,题目中的指数为$\dfrac{(x+2)^2}{8}$。
通过对比可得:
- 分母关系:$2\sigma^2 = 8 \implies \sigma^2 = 4$。
- 均值关系:$(x-\mu) = (x+2) \implies \mu = -2$。
结论
随机变量服从正态分布$N(-2, 4)$,对应选项B。