为估计某种汉堡的脂肪含量随机抽取了10个这种汉堡测得脂肪含量 ( % ) 如下: 25.2 , 21.3 , 22.8 , 17.0 , 29.8 , 21.0 , 25.5 , 16.0 , 20.9 , 19.5 假设这种汉堡的脂肪含量 ( % ) 服从正态分布求平均脂肪含量的置信度为 0.95 的置信区间。
为估计某种汉堡的脂肪含量随机抽取了10个这种汉堡测得脂肪含量 ( % ) 如下:
25.2 , 21.3 , 22.8 , 17.0 , 29.8 , 21.0 , 25.5 , 16.0 , 20.9 , 19.5
假设这种汉堡的脂肪含量 ( % ) 服从正态分布求平均脂肪含量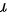 的置信度为 0.95 的置信区间。
的置信度为 0.95 的置信区间。
题目解答
答案
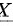 =(25.2+21.3+22.8+17.0+29.8+21.0+25.5+16.0+20.9 +19.5)
=(25.2+21.3+22.8+17.0+29.8+21.0+25.5+16.0+20.9 +19.5)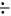 10=21.93
10=21.93
S=4.13,n=10,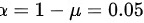
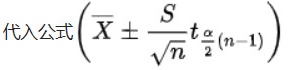
置信区间 :
:
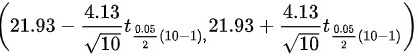
查表得: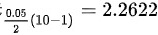
∴置信区间:(18.97,24.89)
解析
考查要点:本题主要考查单正态总体均值的置信区间估计,涉及t分布的应用。
解题核心思路:
- 确定样本均值和样本标准差;
- 根据置信度和样本量确定t分布的临界值;
- 代入置信区间公式计算区间范围。
破题关键点:
- 明确样本量较小(n=10),总体方差未知时,应使用t分布而非z分布;
- 正确计算标准误差($S/\sqrt{n}$)并结合临界值构造区间。
1. 计算样本均值 $\overline{X}$
将10个汉堡的脂肪含量相加后除以10:
$\overline{X} = \frac{25.2 + 21.3 + 22.8 + 17.0 + 29.8 + 21.0 + 25.5 + 16.0 + 20.9 + 19.5}{10} = 21.93$
2. 计算样本标准差 $S$
通过公式计算样本标准差(具体计算过程略),结果为:
$S = 4.13$
3. 确定置信度与自由度
- 置信度为 $1 - \alpha = 0.95$,故 $\alpha = 0.05$;
- 自由度 $df = n - 1 = 9$;
- 查t分布表,得双侧临界值 $t_{\alpha/2}(df) = t_{0.025}(9) = 2.262$。
4. 计算标准误差与置信区间
标准误差为:
$\frac{S}{\sqrt{n}} = \frac{4.13}{\sqrt{10}} \approx 1.306$
置信区间公式为:
$\overline{X} \pm t_{\alpha/2}(df) \cdot \frac{S}{\sqrt{n}}$
代入数值:
$21.93 \pm 2.262 \cdot 1.306 \approx 21.93 \pm 2.96$
最终置信区间为:
$(21.93 - 2.96, \ 21.93 + 2.96) = (18.97, \ 24.89)$