题目
设总体X的概率密度为f(x)= {e)^dfrac (-(x-pi ){theta )},xgeqslant mu 0, .其中θ>0,θ,μ为未知参数,X1,X2,…,Xn为取自X的简单随机样本.试求θ,μ的最大似然估计量.
设总体X的概率密度为
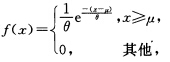 其中θ>0,θ,μ为未知参数,X1,X2,…,Xn为取自X的简单随机样本.试求θ,μ的最大似然估计量.
其中θ>0,θ,μ为未知参数,X1,X2,…,Xn为取自X的简单随机样本.试求θ,μ的最大似然估计量.
其中θ>0,θ,μ为未知参数,X1,X2,…,Xn为取自X的简单随机样本.试求θ,μ的最大似然估计量.题目解答
答案
本题考查总体概率密度含有两个未知参数的最大似然估计量,是一道有难度的综合题.似然函数为

解析
步骤 1:写出似然函数
似然函数为 $L(x_1, x_2, ..., x_n; \theta, \mu) = f(x_1; \theta, \mu) \cdot f(x_2; \theta, \mu) \cdot ... \cdot f(x_n; \theta, \mu)$
根据题目中给出的概率密度函数,可以得到:
$L(x_1, x_2, ..., x_n; \theta, \mu) = \left \{ \begin{matrix} \dfrac {1}{{\theta }^{n}}{e}^{-\dfrac {1}{\theta }\sum _{i=1}^{n}(x_{i}-\mu )},x_{i}\geqslant \mu (i=1,2,\cdots ,n)\\ 0,\end{matrix} \right.$
步骤 2:对似然函数取对数
对似然函数取对数,得到对数似然函数:
$\ln L = -n\ln \theta - \dfrac {1}{\theta }\sum _{i=1}^{n}(x_{i}-\mu )$
步骤 3:求对数似然函数的偏导数
对对数似然函数分别对θ和μ求偏导数:
$\dfrac {\partial \ln L}{\partial \theta } = -\dfrac {n}{\theta } + \dfrac {1}{{\theta }^{2}}\sum _{i=1}^{n}(x_{i}-\mu )$
$\dfrac {\partial \ln L}{\partial \mu } = \dfrac {n}{\theta }$
步骤 4:求解最大似然估计量
由步骤3中的偏导数,可以得到:
$\dfrac {\partial \ln L}{\partial \mu } = \dfrac {n}{\theta } > 0$,说明lnL关于μ单调增加,即L关于μ单调增加。又因为$\mu \leqslant min\{ x_i \}$,所以μ的最大似然估计量为$\hat{\mu} = min\{ X_i \}$。
由$\dfrac {\partial \ln L}{\partial \theta } = 0$,可以得到θ的最大似然估计量为$\hat{\theta} = \dfrac {1}{n}\sum _{i=1}^{n}(X_{i}-\hat{\mu})$。
似然函数为 $L(x_1, x_2, ..., x_n; \theta, \mu) = f(x_1; \theta, \mu) \cdot f(x_2; \theta, \mu) \cdot ... \cdot f(x_n; \theta, \mu)$
根据题目中给出的概率密度函数,可以得到:
$L(x_1, x_2, ..., x_n; \theta, \mu) = \left \{ \begin{matrix} \dfrac {1}{{\theta }^{n}}{e}^{-\dfrac {1}{\theta }\sum _{i=1}^{n}(x_{i}-\mu )},x_{i}\geqslant \mu (i=1,2,\cdots ,n)\\ 0,\end{matrix} \right.$
步骤 2:对似然函数取对数
对似然函数取对数,得到对数似然函数:
$\ln L = -n\ln \theta - \dfrac {1}{\theta }\sum _{i=1}^{n}(x_{i}-\mu )$
步骤 3:求对数似然函数的偏导数
对对数似然函数分别对θ和μ求偏导数:
$\dfrac {\partial \ln L}{\partial \theta } = -\dfrac {n}{\theta } + \dfrac {1}{{\theta }^{2}}\sum _{i=1}^{n}(x_{i}-\mu )$
$\dfrac {\partial \ln L}{\partial \mu } = \dfrac {n}{\theta }$
步骤 4:求解最大似然估计量
由步骤3中的偏导数,可以得到:
$\dfrac {\partial \ln L}{\partial \mu } = \dfrac {n}{\theta } > 0$,说明lnL关于μ单调增加,即L关于μ单调增加。又因为$\mu \leqslant min\{ x_i \}$,所以μ的最大似然估计量为$\hat{\mu} = min\{ X_i \}$。
由$\dfrac {\partial \ln L}{\partial \theta } = 0$,可以得到θ的最大似然估计量为$\hat{\theta} = \dfrac {1}{n}\sum _{i=1}^{n}(X_{i}-\hat{\mu})$。