题目
设随机变量 X 与 Y 相互独立,X N ( 0 ,1 ) ,Y N ( 1 ,1 )(A) P ( X + Y ≤ 0 ) = dfrac (1)(2) (B) P ( X + Y ≤ 1 ) =dfrac (1)(2) (C) P ( X − Y ≤ 0 ) = dfrac (1)(2) (D) P ( X − Y ≤ 1 ) = dfrac (1)(2)
设随机变量 X 与 Y 相互独立,X N ( 0 ,1 ) ,Y N ( 1 ,1 )
(A) P ( X + Y ≤ 0 ) = 
(B) P ( X + Y ≤ 1 ) =
(C) P ( X − Y ≤ 0 ) =
(D) P ( X − Y ≤ 1 ) =
题目解答
答案
答案选B
解析:
X N ( 0 ,1 ) ,Y-1 N (0 ,1 ) ,
X+Y-1~N ( 0 ,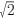 ) P(X+Y-10)=
) P(X+Y-10)=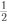
类似 X-(Y-1)~N ( 0 ,) P(X-Y+10)=
对的仅是(B)P ( X + Y ≤ 1 ) = ;
两个独立正态分布相加仍是正态分布,均值=两均值和,方差平方=原方差平方和
解析
考查要点:本题主要考查独立正态随机变量的线性组合的分布性质,以及利用正态分布的对称性计算概率。
解题核心思路:
- 确定线性组合的分布:根据独立正态变量的性质,若$X \sim N(\mu_X, \sigma_X^2)$,$Y \sim N(\mu_Y, \sigma_Y^2)$,则$X+Y \sim N(\mu_X+\mu_Y, \sigma_X^2+\sigma_Y^2)$,$X-Y \sim N(\mu_X-\mu_Y, \sigma_X^2+\sigma_Y^2)$。
- 标准化求概率:将线性组合的表达式标准化为标准正态分布,利用$\Phi(0)=\dfrac{1}{2}$的性质判断选项。
破题关键点:
- 选项B的关键:$X+Y \sim N(1, 2)$,当求$P(X+Y \leq 1)$时,恰好等于均值,概率为$\dfrac{1}{2}$。
- 其他选项错误原因:均值与所求点的位置关系导致概率不等于$\dfrac{1}{2}$。
选项分析
选项B
- 确定分布:
$X \sim N(0,1)$,$Y \sim N(1,1)$,且独立,故$X+Y \sim N(0+1, 1+1) = N(1, 2)$。 - 标准化:
$P(X+Y \leq 1) = P\left(\frac{X+Y - 1}{\sqrt{2}} \leq \frac{1 - 1}{\sqrt{2}}\right) = P(Z \leq 0) = \Phi(0) = \dfrac{1}{2}.$
因此选项B正确。
其他选项错误分析
- 选项A:
$X+Y \sim N(1, 2)$,求$P(X+Y \leq 0)$对应均值左侧1个单位,概率小于$\dfrac{1}{2}$。 - 选项C:
$X-Y \sim N(-1, 2)$,求$P(X-Y \leq 0)$对应均值右侧1个单位,概率大于$\dfrac{1}{2}$。 - 选项D:
$X-Y \sim N(-1, 2)$,求$P(X-Y \leq 1)$对应均值右侧$\sqrt{2}$个单位,概率约为$\Phi(\sqrt{2}) \approx 0.928$,不等于$\dfrac{1}{2}$。