11.二维连续型随机变量(X,Y)的概率分布为f(x,y),则关于协方差以下错误的是()A.(X,Y)=E[ X-E(X)] cdot [ Y-Y(Y)] A.(X,Y)=E[ X-E(X)] cdot [ Y-Y(Y)] C.A.(X,Y)=E[ X-E(X)] cdot [ Y-Y(Y)] D.A.(X,Y)=E[ X-E(X)] cdot [ Y-Y(Y)]
11.二维连续型随机变量(X,Y)的概率分布为f(x,y),则关于协方差以下错误的是()
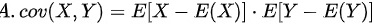
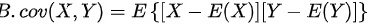
C.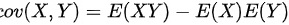
D.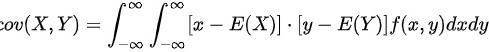
题目解答
答案
解:∵协方差的定义:设(X,Y)为二维随机变量,若E{[X-E(X)][Y-E(Y)]}存在,则称其为随机变量X,Y的协方差,记为cov(X,Y),即cov(X,Y)=E{[X-E(X)][Y-E(Y)]}。
∴A错误,B正确
∵E(Y)]}=E(XY)-E(X)E(Y)-E(Y)E(X)+E(X)E(Y)=cov(X,Y)
=E(XY)-E(X)E(Y)。∴C正确
∵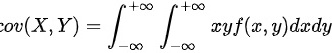
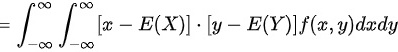
∴D正确
∴此题选A
解析
协方差是描述两个随机变量线性相关程度的量,其核心定义为:
$\text{cov}(X,Y) = E\left\{[X - E(X)][Y - E(Y)]\right\}$
本题需判断选项中哪一表述不符合该定义。关键点在于:
- 协方差的展开形式:$\text{cov}(X,Y) = E(XY) - E(X)E(Y)$;
- 积分形式:对连续型随机变量,协方差需通过二重积分计算;
- 错误选项特征:若表达式未体现“乘积的期望”或“期望的乘积”混淆,则可能错误。
选项分析
选项A
$\text{cov}(X,Y) = E\left[ X - E(X) \right] \cdot \left[ Y - E(Y) \right]$
错误。协方差应为两个差乘积的期望,而非期望的乘积。正确形式应为:
$\text{cov}(X,Y) = E\left\{ [X - E(X)][Y - E(Y)] \right\}$
选项B
$\text{cov}(X,Y) = E\left\{ [X - E(X)][Y - E(Y)] \right\}$
正确。此为协方差的标准定义。
选项C
$\text{cov}(X,Y) = E(XY) - E(X)E(Y)$
正确。通过展开定义式可得:
$\begin{aligned}\text{cov}(X,Y) &= E\left\{ [X - E(X)][Y - E(Y)] \right\} \\&= E(XY) - E(X)E(Y) - E(Y)E(X) + E(X)E(Y) \\&= E(XY) - E(X)E(Y).\end{aligned}$
选项D
$\text{cov}(X,Y) = \int_{-\infty}^{\infty} \int_{-\infty}^{\infty} [x - E(X)][y - E(Y)] f(x,y) \, dx \, dy$
正确。对连续型随机变量,协方差需通过概率密度函数的二重积分计算。