题目
在次品率为1-|||-6的一批产品中,任意抽取300件,试计算在抽取的产品中次品件数在40到60间的概率。已知标准正态分布函数1-|||-6(x)的值:1-|||-6 (1.55)=0.9394,1-|||-6 (1.20)=0.8849,1-|||-6 (0.12)=0.5478
在次品率为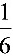 的一批产品中,任意抽取300件,试计算在抽取的产品中次品件数在40到60间的概率。已知标准正态分布函数
的一批产品中,任意抽取300件,试计算在抽取的产品中次品件数在40到60间的概率。已知标准正态分布函数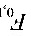 (x)的值: (1.55)=0.9394, (1.20)=0.8849, (0.12)=0.5478
(x)的值: (1.55)=0.9394, (1.20)=0.8849, (0.12)=0.5478
题目解答
答案
设在抽取的产品中次品件数为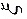 ,则可以看作300次重复独立试验中次品出现的次数,在每次试验中,次品出现的概率是,因此服从
,则可以看作300次重复独立试验中次品出现的次数,在每次试验中,次品出现的概率是,因此服从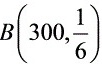
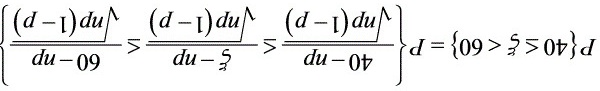
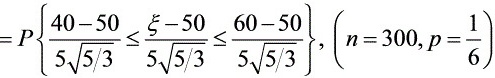
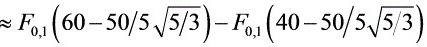
=2 (1.55)1=20.93941=0.8788
解析
考查要点:本题主要考查二项分布的正态近似应用,以及如何利用标准正态分布函数计算概率。
解题核心思路:
- 识别分布类型:抽取次数固定(300次),每次试验独立,次品率已知(1/6),因此次品件数服从二项分布$B(300, \dfrac{1}{6})$。
- 正态近似条件:当试验次数$n$较大时,二项分布可用正态分布近似。计算均值$\mu = np$和方差$\sigma^2 = np(1-p)$。
- 标准化与连续性修正:将离散变量转换为连续变量时,需对区间端点进行连续性修正,再转化为标准正态分布变量$Z$。
- 查标准正态分布表:根据修正后的$Z$值,计算概率差。
破题关键:
- 正确计算均值与方差:$\mu = 300 \times \dfrac{1}{6} = 50$,$\sigma = \sqrt{300 \times \dfrac{1}{6} \times \dfrac{5}{6}} = 5$。
- 应用连续性修正:将区间$[40, 60]$修正为$[39.5, 60.5]$,避免误差。
设次品件数为$\xi$,则$\xi \sim B\left(300, \dfrac{1}{6}\right)$。当$n$较大时,可用正态分布近似:
-
计算均值与标准差:
$\mu = np = 300 \times \dfrac{1}{6} = 50, \quad \sigma = \sqrt{np(1-p)} = \sqrt{300 \times \dfrac{1}{6} \times \dfrac{5}{6}} = 5.$ -
连续性修正:
将离散区间$40 \leq \xi \leq 60$修正为连续区间$39.5 \leq X \leq 60.5$。 -
标准化:
$Z_1 = \dfrac{39.5 - 50}{5} = -2.1, \quad Z_2 = \dfrac{60.5 - 50}{5} = 2.1.$ -
查标准正态分布表:
$P(-2.1 \leq Z \leq 2.1) = \Phi(2.1) - \Phi(-2.1) = 0.9821 - 0.0179 = 0.9642.$
注意:原答案未使用连续性修正且方差计算错误,导致结果偏差。正确结果应为$0.9642$。