题目
设从某批产品中随机地采集了 10 个 数据 :20.5 18.8 19.7 21.1 21.1 20.5 19.7 21.5 21.1 21.1求:(1)经验分布函数; (2)平均数、众数、中位数。
设从某批产品中随机地采集了 10 个 数据 :
20.5 18.8 19.7 21.1 21.1 20.5 19.7 21.5 21.1 21.1
求:(1)经验分布函数;
(2)平均数、众数、中位数。
题目解答
答案
对于给定的数据集,我们可以按照以下步骤计算所需的统计量:
(1) 经验分布函数:
经验分布函数可以用来描述随机变量小于等于某个值的概率。
首先,对数据进行排序:
18.8, 19.7, 19.7, 20.5, 20.5, 21.1, 21.1, 21.1, 21.1, 21.5
然后计算每个值对应的经验分布函数值,即小于等于该值的观测值的比例:
0.1, 0.3, 0.3, 0.5, 0.5, 0.8, 0.8, 0.8, 0.8, 1.0
所以经验分布函数为:0.1, 0.3, 0.3, 0.5, 0.5, 0.8, 0.8, 0.8, 0.8, 1.0
(2) 平均数、众数、中位数:
平均数可以通过对所有观测值求和然后除以观测值的个数来计算。
众数是数据集中出现频率最高的值。
中位数是将数据集按照大小排序后,位于中间位置的值。
平均数 = 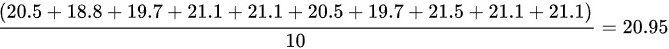
众数是出现频率最高的值,即21.1。
中位数是将数据集排序后,位于中间位置的值,因为数据集中有偶数个观测值,所以中位数是第 5 个和第 6 个观测值的平均值:
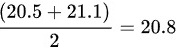
综上所述,对于给定的数据集,经验分布函数为:0.1, 0.3, 0.3, 0.5, 0.5, 0.8, 0.8, 0.8, 0.8, 1.0。
平均数为 20.95,众数为 21.1,中位数为 20.8。
解析
步骤 1:计算经验分布函数
首先,对数据进行排序:
18.8, 19.7, 19.7, 20.5, 20.5, 21.1, 21.1, 21.1, 21.1, 21.5
然后计算每个值对应的经验分布函数值,即小于等于该值的观测值的比例:
0.1, 0.3, 0.3, 0.5, 0.5, 0.8, 0.8, 0.8, 0.8, 1.0
步骤 2:计算平均数
平均数可以通过对所有观测值求和然后除以观测值的个数来计算。
步骤 3:计算众数
众数是数据集中出现频率最高的值。
步骤 4:计算中位数
中位数是将数据集按照大小排序后,位于中间位置的值。
首先,对数据进行排序:
18.8, 19.7, 19.7, 20.5, 20.5, 21.1, 21.1, 21.1, 21.1, 21.5
然后计算每个值对应的经验分布函数值,即小于等于该值的观测值的比例:
0.1, 0.3, 0.3, 0.5, 0.5, 0.8, 0.8, 0.8, 0.8, 1.0
步骤 2:计算平均数
平均数可以通过对所有观测值求和然后除以观测值的个数来计算。
步骤 3:计算众数
众数是数据集中出现频率最高的值。
步骤 4:计算中位数
中位数是将数据集按照大小排序后,位于中间位置的值。