下面是1978-1998年我国消费(CONS)对国内生产总值(GDP)的回归结果。Dependent Variable: CONSMethod: Least SquaresSample: 1978 1998Included observations: 21VariableCoefficientStd. Errort-StatisticProb. C620.6414①6.5689330.0000GDP0.5730040.002688②0.0000R-squared0.999582 Mean dependent var14984.05Adjusted R-squared0.999560 S.D. dependent var14470.05S.E. of regression303.5092 Akaike info criterion14.35909Sum squared resid1750239. Schwarz criterion14.45857Log likelihood-148.7705 F-statistic③Durbin-Watson stat0.805802 Prob(F-statistic)0.0000001)根据回归结果中的数据,补齐表中的空格。(每空2分)① ② ③2)写出回归方程,并释回归系数的经济意义。(2分)3)假设1999年GDP为100000亿,请估计当年的消费额?(2分)4)判断该回归模型是否存在序列相关性?(1分)请说明理由。(当n=21,k=2时, )(2分)如果存在序列相关性,可以采用哪些方法补救?(2分)
下面是1978-1998年我国消费(CONS)对国内生产总值(GDP)的回归结果。
Dependent Variable: CONS
Method: Least Squares
Sample: 1978 1998
Included observations: 21
Variable
Coefficient
Std. Error
t-Statistic
Prob.
C
620.6414
①
6.568933
0.0000
GDP
0.573004
0.002688
②
0.0000
R-squared
0.999582
Mean dependent var
14984.05
Adjusted R-squared
0.999560
S.D. dependent var
14470.05
S.E. of regression
303.5092
Akaike info criterion
14.35909
Sum squared resid
1750239.
Schwarz criterion
14.45857
Log likelihood
-148.7705
F-statistic
③
Durbin-Watson stat
0.805802
Prob(F-statistic)
0.000000
1)根据回归结果中的数据,补齐表中的空格。(每空2分)
① ② ③
2)写出回归方程,并释回归系数的经济意义。(2分)
3)假设1999年GDP为100000亿,请估计当年的消费额?(2分)
4)判断该回归模型是否存在序列相关性?(1分)请说明理由。(当n=21,k=2时, )(2分)如果存在序列相关性,可以采用哪些方法补救?(2分)
题目解答
答案
1)① 94.48 ② 213.17 ③ 45435.5
2)答:回归方程为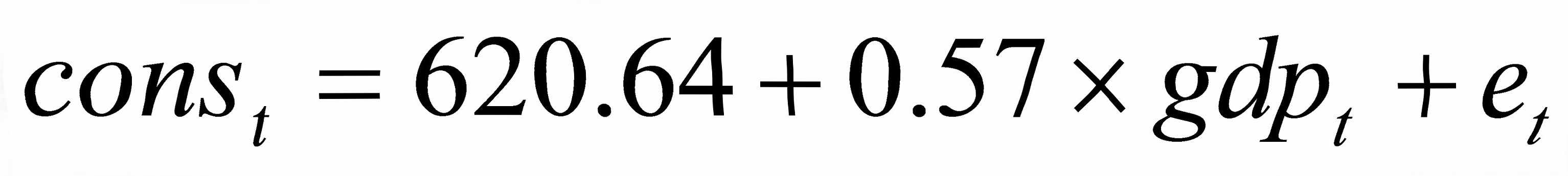 620.64可以释为自发性消费支出,0.57为边际消费倾向。
620.64可以释为自发性消费支出,0.57为边际消费倾向。
3)答:当GDP为100000亿时,当年消费额估计值为 620.64+0.57×100000=57620.64亿
4)答:可以得出回归中存在序列相关性,因为D.W.统计量低于下界。存在序列相关时可以用广义最小二乘法和广义差分法就行补救。
解析
本题主要考查多元线性回归分析的相关知识,包括回归系数的计算、回归方程的建立与经济意义解释、预测以及序列相关性的判断与补救方法。解题思路如下:
- 补齐表格空格:
- 对于①,根据$t -$统计量的计算公式$t=\frac{\hat{\beta}}{s_{\hat{\beta}}}$(其中$\hat{\beta}$为回归系数,$s_{\hat{\beta}}$为回归系数的标准误),已知$C$的系数$\hat{\beta}_0 = 620.6414$,$t -$统计量$t_0 = 6.568933$,则$C$的标准误$s_{\hat{\beta}_0}=\frac{\hat{\beta}_0}{t_0}$。
- 对于②,同样根据$t -$统计量的计算公式,已知$GDP$的系数$\hat{\beta}_1 = 0.573004$,$GDP$的标准误$s_{\hat{\beta}_1}=0.002688$,则$GDP$的$t -$统计量$t_1=\frac{\hat{\beta}_1}{s_{\hat{\beta}_1}}$。
- 对于③,根据$F -$统计量与$t -$统计量的关系$F = t^2$(在一元线性回归中),这里$GDP$的$t -$统计量为$t_1$,则$F -$统计量$F=t_1^2$。
- 写出回归方程并解释回归系数的经济意义:
- 回归方程的一般形式为$CONS=\hat{\beta}_0+\hat{\beta}_1GDP$,将$C$的系数$\hat{\beta}_0$和$GDP$的系数$\hat{\beta}_1$代入即可得到回归方程。
- 其中$\hat{\beta}_0$表示自发性消费支出,即不随国内生产总值变化的消费部分;$\hat{\beta}_1$表示边际消费倾向,即国内生产总值每增加一单位时消费的增加量。
- 估计当年的消费额:
- 将$1999$年的$GDP$值代入回归方程$CONS=\hat{\beta}_0+\hat{\beta}_1GDP$,即可得到当年消费额的估计值。
- 判断该回归模型是否存在序列相关性:
- 给定显著性水平$\alpha$,根据样本容量$n = 21$和解释变量个数$k = 2$,查$D.W.$分布表得到$D.W.$统计量的下界$d_L$和上界$d_U$。
- 若$0
- 本题中已知$D.W. = 0.805802$,若$0.805802
- 若存在序列相关性,可采用广义最小二乘法和广义差分法进行补救。
- 本题中已知$D.W. = 0.805802$,若$0.805802
下面进行详细计算:
- 补齐表格空格:
- ① $C$的标准误$s_{\hat{\beta}_0}=\frac{\hat{\beta}_0}{t_0}=\frac{620.6414}{6.568933}\approx94.48$。
- ② $GDP$的$t -$统计量$t_1=\frac{\hat{\beta}_1}{s_{\hat{\beta}_1}}=\frac{0.573004}{0.002688}\approx213.17$。
- ③ $F -$统计量$F=t_1^2=(213.17)^2\approx45435.5$。
- 写出回归方程并解释回归系数的经济意义:
- 回归方程为$CONS = 620.6414 + 0.573004GDP$,可近似写为$CONS = 620.64 + 0.57GDP$。
- $620.64$表示自发性消费支出,即不随国内生产总值变化的消费部分;$0.57$表示边际消费倾向,即国内生产总值每增加一单位时消费的增加量。
- 估计当年的消费额:
- 当$GDP = 100000$亿时,代入回归方程可得$CONS = 620.64 + 0.57\times100000 = 57620.64$亿。
- 判断该回归模型是否存在序列相关性:
- 已知$D.W. = 0.805802$,当$n = 21$,$k = 2$时,查$D.W.$分布表(假设给定显著性水平$\alpha = 0.05$),可得$d_L\approx1.22$,$d_U\approx1.42$。
- 因为$0.805802<1.22$,即$D.W.$统计量低于下界,所以可以得出回归中存在序列相关性。
- 存在序列相关时可以用广义最小二乘法和广义差分法进行补救。