解:本题采用完全随机设计的方差分析。表9-6 三种方案治疗一个月后缺铁性贫血患者红细胞的升高数(102/L)一般疗法一般疗法+A1一般疗法+A2合计0.811.322.350.751.412.500.741.352.430.861.382.360.821.402.440.871.332.460.751.432.400.741.382.430.721.402.210.821.402.450.801.342.380.751.462.4012121236 ()9.4316.6028.8154.84()0.78581.38332.40087.438522.982869.228199.6494()(1) 方差分析1) 建立检验假设,确定检验水准0H:0H,即三种方案治疗后缺铁性贫血患者红细胞升高数相同0H:0H不全相同,即三种方案治疗后缺铁性贫血患者红细胞升高数不全相同0H=0.052) 计算检验统计量方差分析结果见表9-7。表9-7完全随机资料的方差分析表变异来源总变异16.109835组间变异16.00222 8.00112452.7216<0.01组内变异0.107633 0.00333) 确定0H值,作出统计推断查0H界值表(附表4)得P<0.01,按0H=0.05水准,拒绝0H,接受0H,差别有统计学意义,可以认为三种不同方案治疗后患者红细胞升高数的总体均数不全相同。(2) 用Dunnett-0H法进行多重比较。1) 建立检验假设,确定检验水准0H:任一实验组与对照组的总体均数相同0H:任一实验组与对照组的总体均数不同2)计算检验统计量表9-8多个样本均数的Dunnett-0H检验计算表对比组(1)均数差值(2)标准误(3)(4)Dunnett-界值一般疗法与一般疗法+A1 0.600.02302.32<0.05一般疗法与一般疗法+A2 1.620.02812.32<0.053) 确定0H值,作出统计推断将表9-8中0H取绝对值,并以计算0H时的自由度0H和实验组数a=k−1=2(不含对照组)查Dunnett-0H界值表得0H值,列于表中。按0H=0.05水准,一般疗法+A1与一般疗法相比,疗效差别有统计学意义,可以认为一般疗法+A1与一般疗法治疗缺铁性贫血疗效不同。同理,可以认为一般疗法+A2与一般疗法治疗缺铁性贫血疗效不同SPSS操作数据录入:打开SPSS Data Editor窗口,点击Variable View标签,定义要输入的变量,group表示组别 (1为一般疗法,2为一般疗法+药物A低剂量,3为一般疗法+药物A高剂量),x表示患者红细胞的升高数(102/L);再点击Data View标签,录入数据(见图9-1,图9-2)。图9-1 Variable View窗口内定义要输入的变量group和x图9-2 Data View窗口内录入数据
解:本题采用完全随机设计的方差分析。
表9-6 三种方案治疗一个月后缺铁性贫血患者红细胞的升高数(102/L)
一般疗法
一般疗法+A1
一般疗法+A2
合计
0.81
1.32
2.35
0.75
1.41
2.50
0.74
1.35
2.43
0.86
1.38
2.36
0.82
1.40
2.44
0.87
1.33
2.46
0.75
1.43
2.40
0.74
1.38
2.43
0.72
1.40
2.21
0.82
1.40
2.45
0.80
1.34
2.38
0.75
1.46
2.40
12
12
12
36 ()
9.43
16.60
28.81
54.84()
0.7858
1.3833
2.4008
7.4385
22.9828
69.2281
99.6494()
(1) 方差分析
1) 建立检验假设,确定检验水准
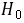 :
: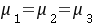 ,即三种方案治疗后缺铁性贫血患者红细胞升高数相同
,即三种方案治疗后缺铁性贫血患者红细胞升高数相同
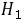 :
: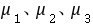 不全相同,即三种方案治疗后缺铁性贫血患者红细胞升高数不全相同
不全相同,即三种方案治疗后缺铁性贫血患者红细胞升高数不全相同
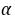 =0.05
=0.05
2) 计算检验统计量
方差分析结果见表9-7。
表9-7完全随机资料的方差分析表
变异来源
总变异
16.1098
35
组间变异
16.0022
2
8.0011
2452.7216
<0.01
组内变异
0.1076
33
0.0033
3) 确定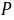 值,作出统计推断
值,作出统计推断
查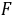 界值表(附表4)得P<0.01,按=0.05水准,拒绝,接受,差别有统计学意义,可以认为三种不同方案治疗后患者红细胞升高数的总体均数不全相同。
界值表(附表4)得P<0.01,按=0.05水准,拒绝,接受,差别有统计学意义,可以认为三种不同方案治疗后患者红细胞升高数的总体均数不全相同。
(2) 用Dunnett-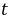 法进行多重比较。
法进行多重比较。
1) 建立检验假设,确定检验水准
:任一实验组与对照组的总体均数相同
:任一实验组与对照组的总体均数不同
2)计算检验统计量
表9-8多个样本均数的Dunnett-检验计算表
对比组
(1)
均数差值
(2)
标准误
(3)
(4)
Dunnett-界值
一般疗法与一般疗法+A1
0.60
0.02
30
2.32
<0.05
一般疗法与一般疗法+A2
1.62
0.02
81
2.32
<0.05
3) 确定值,作出统计推断
将表9-8中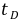 取绝对值,并以计算
取绝对值,并以计算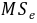 时的自由度
时的自由度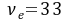 和实验组数a=k−1=2(不含对照组)查Dunnett-界值表得值,列于表中。按=0.05水准,一般疗法+A1与一般疗法相比,疗效差别有统计学意义,可以认为一般疗法+A1与一般疗法治疗缺铁性贫血疗效不同。同理,可以认为一般疗法+A2与一般疗法治疗缺铁性贫血疗效不同
和实验组数a=k−1=2(不含对照组)查Dunnett-界值表得值,列于表中。按=0.05水准,一般疗法+A1与一般疗法相比,疗效差别有统计学意义,可以认为一般疗法+A1与一般疗法治疗缺铁性贫血疗效不同。同理,可以认为一般疗法+A2与一般疗法治疗缺铁性贫血疗效不同
SPSS操作
数据录入:
打开SPSS Data Editor窗口,点击Variable View标签,定义要输入的变量,group表示组别 (1为一般疗法,2为一般疗法+药物A低剂量,3为一般疗法+药物A高剂量),x表示患者红细胞的升高数(102/L);再点击Data View标签,录入数据(见图9-1,图9-2)。
图9-1 Variable View窗口内定义要输入的变量group和x
图9-2 Data View窗口内录入数据
题目解答
答案
分析:
Analyze→Compare Means →one-Way ANOVA
Dependent List框:x
Factor框:group
Post Hoc… →Equal Variances Assumed: Dunnett:Control Category:first
Dunnett:Control Category:first
Continue
Option... →Statistics: Homogeneity of Variances test
Continue
OK
输出结果
Test of Homogeneity of Variances
红细胞升高数(102/L)
Levene Statistic | df1 | df2 | Sig. |
.774 | 2 | 33 | .469 |
ANOVA
红细胞升高数(102/L)
Sum of Squares | df | Mean Square | F | Sig. | |
Between Groups | 16.002 | 2 | 8.001 | 2452.722 | .000 |
Within Groups | .108 | 33 | .003 | ||
Total | 16.110 | 35 |
Multiple Comparisons
Dependent Variable: 红细胞升高数(102/L)
Dunnett t (2-sided) a
(I) G | (J) G | Mean Difference (I-J) | Std. Error | Sig. | 95% Confidence Interval | |
Lower Bound | Upper Bound | |||||
2 | 1 | .59750(*) | .02332 | .000 | .5436 | .6514 |
3 | 1 | 1.61500(*) | .02332 | .000 | 1.5611 | 1.6689 |
* The mean difference is significant at the .05 level.
a Dunnett t-tests treat one group as a control, and compare all other groups against it.