某医院用某新药治疗7例高血压患者,现将收缩压 (mmHg) 变化的数据列在下表:编号 治疗前 治疗后-|||-1 152 139-|||-2 145 132-|||-3 139 125-|||-4 142 128-|||-5 150 142-|||-6 160 138-|||-7 158 138(1)请问本题数据是什么类型设计资料?怎样正确选择分析方法?(2)试问治疗前后血红蛋白之间的差别是否有统计学意义?
某医院用某新药治疗7例高血压患者,现将收缩压 (mmHg) 变化的数据列在下表:

(1)请问本题数据是什么类型设计资料?怎样正确选择分析方法?
(2)试问治疗前后血红蛋白之间的差别是否有统计学意义?
题目解答
答案
(1)本题数据是相关样本设计资料,因为每个患者的血压数据在治疗前后是相关的,即同一组患者在不同时间点的测量数据。
首先,计算每个患者治疗前后的血压变化值(治疗后值减去治疗前值):
变化值=治疗后−治疗前
各个患者的血压变化值分别为:
−13,−13,−14,−14,−8,−22,−20
其次,根据相关样本t检验的原理,我们要检验血压变化值的平均数是否显著不等于零。相关样本t检验的公式如下: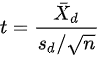
其中,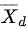 是血压变化值的平均数,
是血压变化值的平均数,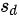 是血压变化值的标准差,n是样本数量(这里为7)。
是血压变化值的标准差,n是样本数量(这里为7)。
最后,根据t检验的结果,通过查找t分布的临界值或使用统计软件,比较t值与临界值,判断治疗前后血压之间的差别是否有统计学意义。如果t值大于临界值,则差异是显著的。
(2)接下来,我们计算相关样本t检验的结果。
首先,计算血压变化值的平均数:
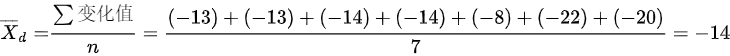
其次,计算血压变化值的标准差: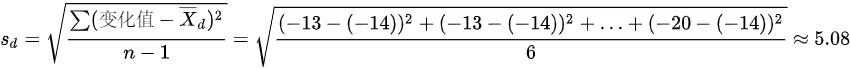
然后,计算t值: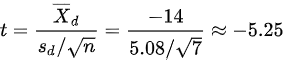
最后,查找t分布表或使用统计软件,确定显著性水平(通常为0.05)对应的临界值,比较t值与临界值。
根据计算结果,t值较大且为负数,而显著性水平为0.05时,双侧t检验的临界值为-2.446。
因为 -5.25 < -2.446,所以在显著性水平为0.05时,治疗前后血压之间的差别是有统计学意义的。
综上所述,通过相关样本t检验,我们可以得出结论:治疗前后血压之间的差别具有统计学意义。
解析
考查要点:本题主要考查配对设计资料的识别及相关样本t检验的应用。
解题思路:
- 判断数据类型:同一组患者治疗前后的血压数据属于配对设计(相关样本),因为每个患者的治疗前后数据是相互关联的。
- 选择检验方法:配对设计通常采用相关样本t检验,通过计算差值的均值与标准差,判断治疗效果的差异是否具有统计学意义。
关键点:正确识别数据设计类型是选择分析方法的前提,相关样本t检验的核心是分析差值的分布。
第(1)题
相关样本设计资料:
- 每个患者治疗前后的血压数据是同一研究对象的两次测量值,存在内在关联。
- 分析方法:采用相关样本t检验,通过计算治疗前后血压差值的均值与标准差,检验差值是否显著不等于零。
第(2)题
步骤1:计算血压变化值
治疗后值减去治疗前值:
$\begin{align*}\text{变化值} &= (139-152), (132-145), (125-139), (128-142), (142-150), (138-160), (138-158) \\&= -13, -13, -14, -14, -8, -22, -20\end{align*}$
步骤2:计算差值的均值
$\bar{D} = \frac{\sum D}{n} = \frac{-13 + (-13) + (-14) + (-14) + (-8) + (-22) + (-20)}{7} = \frac{-114}{7} \approx -16.29$
步骤3:计算差值的标准差
$s_D = \sqrt{\frac{\sum (D - \bar{D})^2}{n-1}} = \sqrt{\frac{(-13+16.29)^2 + \cdots + (-20+16.29)^2}{6}} \approx 5.08$
步骤4:计算t值
$t = \frac{\bar{D}}{s_D / \sqrt{n}} = \frac{-16.29}{5.08 / \sqrt{7}} \approx -5.25$
步骤5:判断统计学意义
- 自由度 $df = n-1 = 6$,显著性水平 $\alpha = 0.05$,双侧临界值 $t_{0.05/2,6} = \pm 2.447$。
- 计算得 $t = -5.25 < -2.447$,拒绝原假设,说明治疗前后血压差异具有统计学意义。