题目
设总体X的概率密度为(x;theta )= ) sqrt (theta )cdot (x)^sqrt (theta -1),0leqslant xleqslant 1 0, .其中θ>0为未知参数,(x1,x2,…,xn)为X的简单随机样本值. (Ⅰ)求θ的矩估计值; (Ⅱ)求θ的最大似然估计量.
设总体X的概率密度为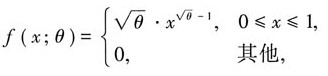 其中θ>0为未知参数,(x1,x2,…,xn)为X的简单随机样本值.
其中θ>0为未知参数,(x1,x2,…,xn)为X的简单随机样本值.
(Ⅰ)求θ的矩估计值;
(Ⅱ)求θ的最大似然估计量.
其中θ>0为未知参数,(x1,x2,…,xn)为X的简单随机样本值.(Ⅰ)求θ的矩估计值;
(Ⅱ)求θ的最大似然估计量.
题目解答
答案
解:(Ⅰ)由.
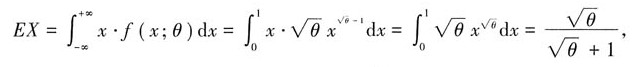
解得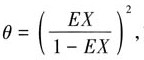 故θ的矩估计值为
故θ的矩估计值为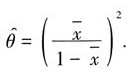
(Ⅱ)似然函数为
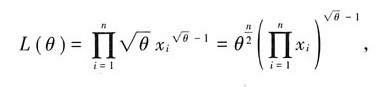
两边取对数得
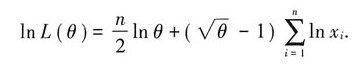
令
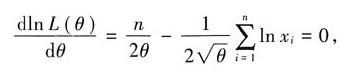
则θ的最大似然估计量为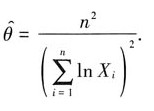
解得
故θ的矩估计值为(Ⅱ)似然函数为
两边取对数得
令
则θ的最大似然估计量为
解析
步骤 1:求解总体X的期望E(X)
根据给定的概率密度函数$f(x;\theta )=$ $\left \{ \begin{matrix} \sqrt {\theta }\cdot {x}^{\sqrt {\theta }-1},0\leqslant x\leqslant 1\\ 0,\end{matrix} \right.$,计算总体X的期望E(X)。
$E(X) = \int_{0}^{1} x \cdot f(x;\theta) dx = \int_{0}^{1} x \cdot \sqrt{\theta} \cdot x^{\sqrt{\theta}-1} dx = \sqrt{\theta} \int_{0}^{1} x^{\sqrt{\theta}} dx = \sqrt{\theta} \cdot \frac{1}{\sqrt{\theta}+1} = \frac{\sqrt{\theta}}{\sqrt{\theta}+1}$
步骤 2:求解θ的矩估计值
根据矩估计法,令总体X的期望E(X)等于样本均值$\overline{x}$,即$\frac{\sqrt{\theta}}{\sqrt{\theta}+1} = \overline{x}$,解得$\theta$的矩估计值$\hat{\theta}$。
$\frac{\sqrt{\theta}}{\sqrt{\theta}+1} = \overline{x}$
$\sqrt{\theta} = \overline{x}(\sqrt{\theta}+1)$
$\sqrt{\theta} = \frac{\overline{x}}{1-\overline{x}}$
$\hat{\theta} = \left(\frac{\overline{x}}{1-\overline{x}}\right)^2$
步骤 3:求解θ的最大似然估计量
根据给定的概率密度函数$f(x;\theta )=$ $\left \{ \begin{matrix} \sqrt {\theta }\cdot {x}^{\sqrt {\theta }-1},0\leqslant x\leqslant 1\\ 0,\end{matrix} \right.$,写出似然函数$L(\theta)$。
$L(\theta) = \prod_{i=1}^{n} f(x_i;\theta) = \prod_{i=1}^{n} \sqrt{\theta} \cdot x_i^{\sqrt{\theta}-1} = \theta^{\frac{n}{2}} \cdot \prod_{i=1}^{n} x_i^{\sqrt{\theta}-1}$
对似然函数取对数,得到对数似然函数$\ln L(\theta)$。
$\ln L(\theta) = \frac{n}{2} \ln \theta + (\sqrt{\theta}-1) \sum_{i=1}^{n} \ln x_i$
对对数似然函数求导,令导数等于0,解得θ的最大似然估计量$\hat{\theta}$。
$\frac{d \ln L(\theta)}{d \theta} = \frac{n}{2 \theta} + \frac{1}{2 \sqrt{\theta}} \sum_{i=1}^{n} \ln x_i = 0$
$\frac{n}{2 \theta} = -\frac{1}{2 \sqrt{\theta}} \sum_{i=1}^{n} \ln x_i$
$\sqrt{\theta} = -\frac{n}{\sum_{i=1}^{n} \ln x_i}$
$\hat{\theta} = \left(-\frac{n}{\sum_{i=1}^{n} \ln x_i}\right)^2$
根据给定的概率密度函数$f(x;\theta )=$ $\left \{ \begin{matrix} \sqrt {\theta }\cdot {x}^{\sqrt {\theta }-1},0\leqslant x\leqslant 1\\ 0,\end{matrix} \right.$,计算总体X的期望E(X)。
$E(X) = \int_{0}^{1} x \cdot f(x;\theta) dx = \int_{0}^{1} x \cdot \sqrt{\theta} \cdot x^{\sqrt{\theta}-1} dx = \sqrt{\theta} \int_{0}^{1} x^{\sqrt{\theta}} dx = \sqrt{\theta} \cdot \frac{1}{\sqrt{\theta}+1} = \frac{\sqrt{\theta}}{\sqrt{\theta}+1}$
步骤 2:求解θ的矩估计值
根据矩估计法,令总体X的期望E(X)等于样本均值$\overline{x}$,即$\frac{\sqrt{\theta}}{\sqrt{\theta}+1} = \overline{x}$,解得$\theta$的矩估计值$\hat{\theta}$。
$\frac{\sqrt{\theta}}{\sqrt{\theta}+1} = \overline{x}$
$\sqrt{\theta} = \overline{x}(\sqrt{\theta}+1)$
$\sqrt{\theta} = \frac{\overline{x}}{1-\overline{x}}$
$\hat{\theta} = \left(\frac{\overline{x}}{1-\overline{x}}\right)^2$
步骤 3:求解θ的最大似然估计量
根据给定的概率密度函数$f(x;\theta )=$ $\left \{ \begin{matrix} \sqrt {\theta }\cdot {x}^{\sqrt {\theta }-1},0\leqslant x\leqslant 1\\ 0,\end{matrix} \right.$,写出似然函数$L(\theta)$。
$L(\theta) = \prod_{i=1}^{n} f(x_i;\theta) = \prod_{i=1}^{n} \sqrt{\theta} \cdot x_i^{\sqrt{\theta}-1} = \theta^{\frac{n}{2}} \cdot \prod_{i=1}^{n} x_i^{\sqrt{\theta}-1}$
对似然函数取对数,得到对数似然函数$\ln L(\theta)$。
$\ln L(\theta) = \frac{n}{2} \ln \theta + (\sqrt{\theta}-1) \sum_{i=1}^{n} \ln x_i$
对对数似然函数求导,令导数等于0,解得θ的最大似然估计量$\hat{\theta}$。
$\frac{d \ln L(\theta)}{d \theta} = \frac{n}{2 \theta} + \frac{1}{2 \sqrt{\theta}} \sum_{i=1}^{n} \ln x_i = 0$
$\frac{n}{2 \theta} = -\frac{1}{2 \sqrt{\theta}} \sum_{i=1}^{n} \ln x_i$
$\sqrt{\theta} = -\frac{n}{\sum_{i=1}^{n} \ln x_i}$
$\hat{\theta} = \left(-\frac{n}{\sum_{i=1}^{n} \ln x_i}\right)^2$