题目
11.设X1,X2是取自总体 approx N(mu ,(sigma )^2) 的一个样本,μ的无偏估计量中最有效的是-|||-() .-|||-(A) (hat {mu )}_(1)=dfrac (1)(2)(X)_(1)+dfrac (1)(2)(X)_(2); (B) (hat {mu )}_(2)=dfrac (2)(3)(X)_(1)+dfrac (1)(3)(X)_(2);-|||-(C) (hat {mu )}_(3)=dfrac (1)(4)(X)_(1)+dfrac (3)(4)(X)_(2) ; (D) (hat {mu )}_(4)=dfrac (1)(5)(X)_(1)+dfrac (4)(5)(X)_(2)
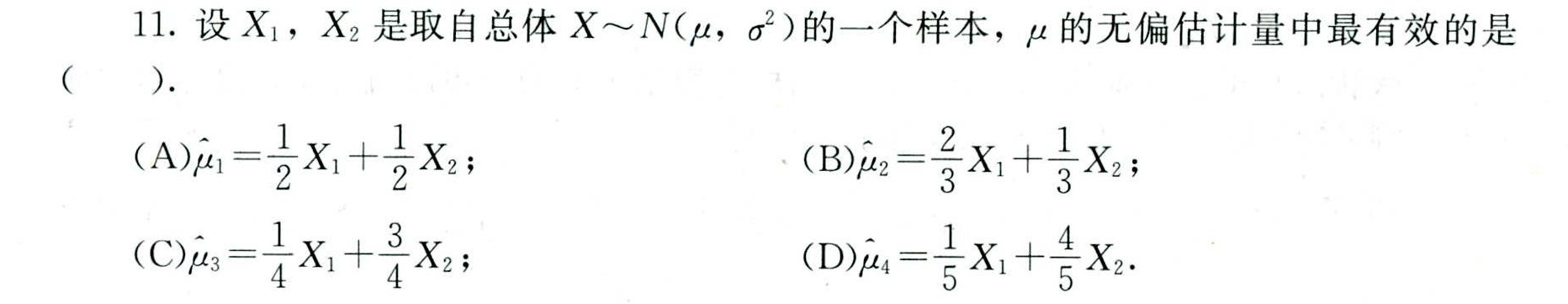
题目解答
答案
解析
步骤 1:确定无偏估计量
无偏估计量是指估计量的期望值等于被估计参数的真实值。对于正态分布 $X\sim N(\mu ,{\sigma }^{2})$,样本均值 $\bar{X} = \frac{1}{n}\sum_{i=1}^{n}X_i$ 是 $\mu$ 的无偏估计量。因此,对于样本 $X_1, X_2$,$\hat{\mu} = \frac{1}{2}X_1 + \frac{1}{2}X_2$ 是 $\mu$ 的无偏估计量。
步骤 2:计算方差
估计量的方差越小,估计量越有效。对于正态分布 $X\sim N(\mu ,{\sigma }^{2})$,样本均值 $\bar{X}$ 的方差为 $\frac{\sigma^2}{n}$。因此,对于样本 $X_1, X_2$,$\hat{\mu} = \frac{1}{2}X_1 + \frac{1}{2}X_2$ 的方差为 $\frac{\sigma^2}{2}$。
步骤 3:比较方差
对于选项 (A) 到 (D),我们计算每个估计量的方差:
- (A) $\hat{\mu}_1 = \frac{1}{2}X_1 + \frac{1}{2}X_2$ 的方差为 $\frac{\sigma^2}{2}$。
- (B) $\hat{\mu}_2 = \frac{2}{3}X_1 + \frac{1}{3}X_2$ 的方差为 $\frac{2^2\sigma^2}{3^2} + \frac{1^2\sigma^2}{3^2} = \frac{5\sigma^2}{9}$。
- (C) $\hat{\mu}_3 = \frac{1}{4}X_1 + \frac{3}{4}X_2$ 的方差为 $\frac{1^2\sigma^2}{4^2} + \frac{3^2\sigma^2}{4^2} = \frac{10\sigma^2}{16} = \frac{5\sigma^2}{8}$。
- (D) $\hat{\mu}_4 = \frac{1}{5}X_1 + \frac{4}{5}X_2$ 的方差为 $\frac{1^2\sigma^2}{5^2} + \frac{4^2\sigma^2}{5^2} = \frac{17\sigma^2}{25}$。
比较这些方差,我们发现 $\frac{\sigma^2}{2}$ 是最小的,因此 $\hat{\mu}_1$ 是最有效的估计量。
无偏估计量是指估计量的期望值等于被估计参数的真实值。对于正态分布 $X\sim N(\mu ,{\sigma }^{2})$,样本均值 $\bar{X} = \frac{1}{n}\sum_{i=1}^{n}X_i$ 是 $\mu$ 的无偏估计量。因此,对于样本 $X_1, X_2$,$\hat{\mu} = \frac{1}{2}X_1 + \frac{1}{2}X_2$ 是 $\mu$ 的无偏估计量。
步骤 2:计算方差
估计量的方差越小,估计量越有效。对于正态分布 $X\sim N(\mu ,{\sigma }^{2})$,样本均值 $\bar{X}$ 的方差为 $\frac{\sigma^2}{n}$。因此,对于样本 $X_1, X_2$,$\hat{\mu} = \frac{1}{2}X_1 + \frac{1}{2}X_2$ 的方差为 $\frac{\sigma^2}{2}$。
步骤 3:比较方差
对于选项 (A) 到 (D),我们计算每个估计量的方差:
- (A) $\hat{\mu}_1 = \frac{1}{2}X_1 + \frac{1}{2}X_2$ 的方差为 $\frac{\sigma^2}{2}$。
- (B) $\hat{\mu}_2 = \frac{2}{3}X_1 + \frac{1}{3}X_2$ 的方差为 $\frac{2^2\sigma^2}{3^2} + \frac{1^2\sigma^2}{3^2} = \frac{5\sigma^2}{9}$。
- (C) $\hat{\mu}_3 = \frac{1}{4}X_1 + \frac{3}{4}X_2$ 的方差为 $\frac{1^2\sigma^2}{4^2} + \frac{3^2\sigma^2}{4^2} = \frac{10\sigma^2}{16} = \frac{5\sigma^2}{8}$。
- (D) $\hat{\mu}_4 = \frac{1}{5}X_1 + \frac{4}{5}X_2$ 的方差为 $\frac{1^2\sigma^2}{5^2} + \frac{4^2\sigma^2}{5^2} = \frac{17\sigma^2}{25}$。
比较这些方差,我们发现 $\frac{\sigma^2}{2}$ 是最小的,因此 $\hat{\mu}_1$ 是最有效的估计量。