题目
9.一袋中有6个正品4个次品,按下列方式抽样:每次取1个,取后放回,共取 (nleqslant 10)-|||-次,其中次品个数记为X;若一次性取出 (nleqslant 10) 个,其中次品个数记为Y。则下列正确的-|||-是 ()-|||-A. gt EY B. lt EY-|||-C. EX=EY D.若n不同,则E X、EY大小不同-|||-丫-y+1gt 0

题目解答
答案
【答案】
C
【解析】
一袋中有6个正品4个次品,每次取1个,取后放回,共取n次,所以每次取到的次品的概率为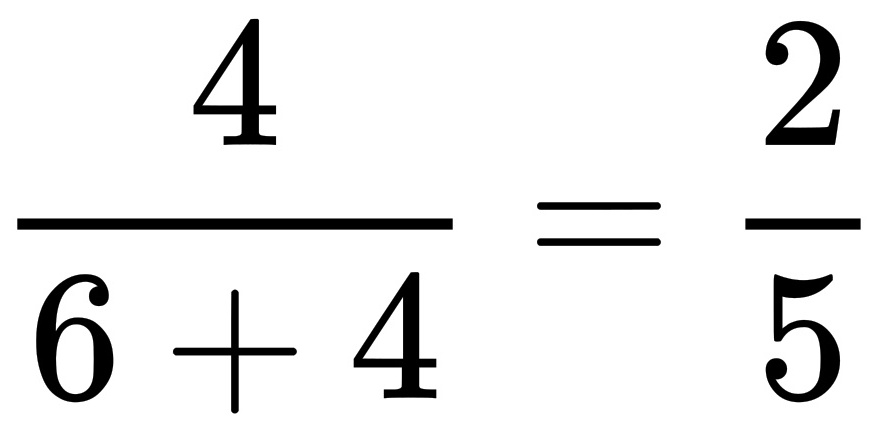
次品个数记为X,因此X服从二项分布,即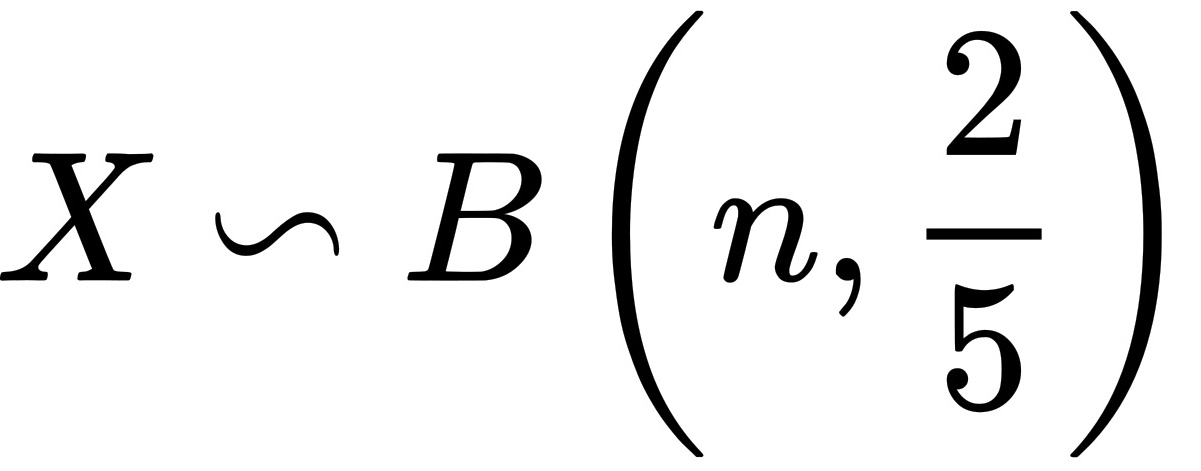 ,则
,则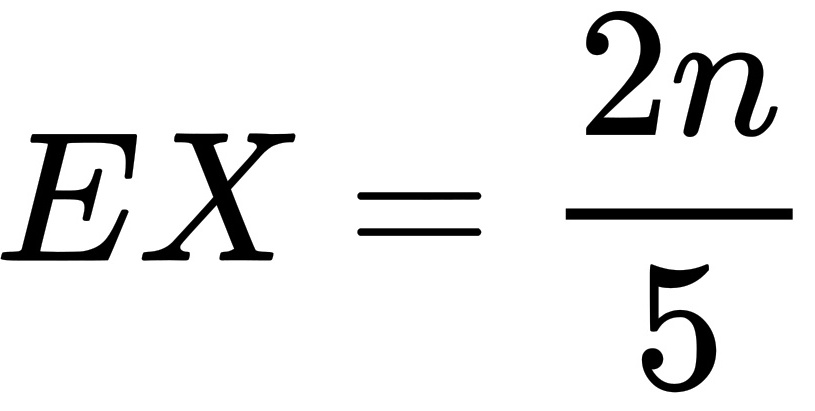
,则一次性取出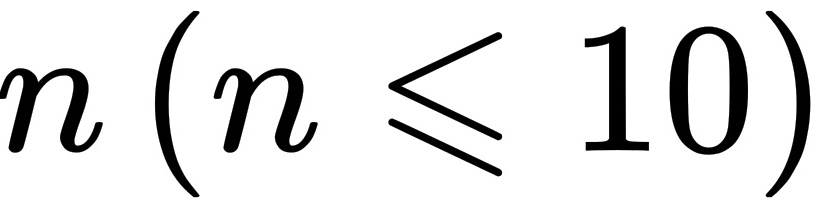 个,其中次品个数记为Y.
个,其中次品个数记为Y.
个,其中次品个数记为Y.由于次品率为,因此平均抽到次品的个数为: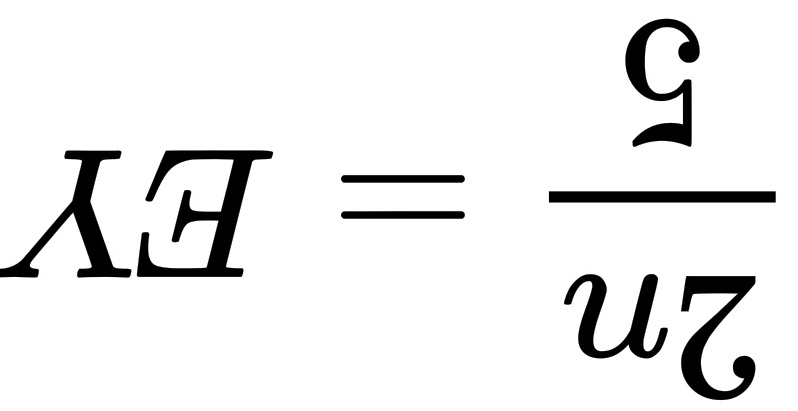
,因此平均抽到次品的个数为:所以EX=EY,故选C.
解析
考查要点:本题主要考查二项分布与超几何分布的期望计算,以及两种抽样方式(放回与不放回)对期望的影响。
解题核心思路:
- 明确两种抽样方式的分布类型:
- X的分布:每次取1个放回,独立重复试验,符合二项分布,参数为$n$和次品率$\frac{4}{10}$。
- Y的分布:一次性取$n$个不放回,符合超几何分布,参数为总数10、次品数4、抽取数$n$。
- 计算期望:
- 二项分布的期望公式为$E(X) = n \cdot p$。
- 超几何分布的期望公式为$E(Y) = n \cdot \frac{K}{N}$(其中$K$为次品总数,$N$为总数)。
- 比较期望:两种分布的期望公式形式相同,结果相等。
破题关键点:
- 区分放回与不放回的分布类型,但注意期望值在两种情况下相同,因为次品率$\frac{4}{10}$在两种分布中均保持一致。
分布类型与期望公式
X的分布(放回抽样)
- 二项分布:每次取次品的概率为$p = \frac{4}{10} = 0.4$,试验次数为$n$。
- 期望公式:
$E(X) = n \cdot p = n \cdot 0.4.$
Y的分布(不放回抽样)
- 超几何分布:总次品数$K=4$,总数$N=10$,抽取数$n$。
- 期望公式:
$E(Y) = n \cdot \frac{K}{N} = n \cdot \frac{4}{10} = n \cdot 0.4.$
期望值比较
- 计算结果:
$E(X) = E(Y) = 0.4n.$ - 结论:两种抽样方式的期望相等,因此选C。