从某企业生产的一批零件中按简单随机重复抽样方式抽取100件,对其直径(毫米)进行调查,所得结果如下:直径(毫米)-|||-96-98-|||-98-100-|||-100-102-|||-零件个数(个)-|||-5-|||-20-|||-38-|||-29-|||-8-|||-102-104-|||-104-106要求:(1)试以95.45%的概率(t=2)估计该批零件平均直径的区间范围;(2)若标准规定直径在96-104毫米之间为合格品,试以95.45%的概率估计该批零件合格率的区间范围.
从某企业生产的一批零件中按简单随机重复抽样方式抽取$$100$$件,对其直径(毫米)进行调查,所得结果如下: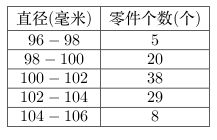
要求:(1)试以$$95.45\%$$的概率$$(t=2)$$估计该批零件平均直径的区间范围;
(2)若标准规定直径在$$96-104$$毫米之间为合格品,试以$$95.45\%$$的概率估计该批零件合格率的区间范围.
题目解答
答案
(1)该批零件平均直径的$$95.45\%$$$$(t=2)$$估计区间的计算:
样本平均直径$$=5\times 97+20\times 99+38\times101+29\times 103$$$$+$$$$8\times 105$$$$=101.3$$
令$$N=(5\times (97-101.3)^2)+20\times (99-101.3)^2$$$$+$$$$38\times (101-101.3)^2$$$$+$$$$29\times (103-101.3)^2$$$$+$$$$8\times (105-101.3)^2$$,
所以,样本标准差$$=\sqrt{\frac{N}{100-1} }$$$$=1.9975$$
所以,平均值的标准误$$=\frac{1.9975}{\sqrt{100}} =0.19975$$.
该批零件平均直径的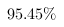 置信区间的下限
置信区间的下限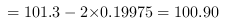 .
.
该批零件平均直径的置信区间的上限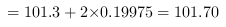 .
.
即该批零件平均直径的区间范围为:($$100.90$$毫米,$$101.70$$毫米).
(2)该批零件合格率置信区间的计算:
样本零件($$100$$个)共有$$8$$个不合格,$$92$$合格,因此该批零件合格率的估计值是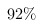 ,按照二项分布的正态近似公式有:
,按照二项分布的正态近似公式有:
样本标准差$$=\sqrt{0.92\times (1-0.92)}=0.27129$$
平均值的标准误$$=\frac{0.27129}{\sqrt{100}}=0.027129$$.
所以,零件合格率置信区间的下限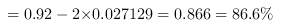
零件合格率置信区间的上限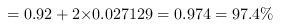 .
.
则零件合格率的区间范围:$$(86.6\%,97.4\%)$$.
解析
根据题目给出的数据,计算样本平均直径。样本平均直径的计算公式为:
$$\bar{x} = \frac{\sum_{i=1}^{n} x_i f_i}{\sum_{i=1}^{n} f_i}$$
其中,$$x_i$$为各组的组中值,$$f_i$$为各组的频数,$$n$$为组数。
步骤 2:计算样本标准差
根据题目给出的数据,计算样本标准差。样本标准差的计算公式为:
$$s = \sqrt{\frac{\sum_{i=1}^{n} f_i (x_i - \bar{x})^2}{n-1}}$$
步骤 3:计算平均值的标准误
平均值的标准误的计算公式为:
$$SE = \frac{s}{\sqrt{n}}$$
步骤 4:计算平均直径的置信区间
平均直径的置信区间的计算公式为:
$$\bar{x} \pm t \times SE$$
其中,$$t$$为置信水平对应的t值,题目中给出$$t=2$$。
步骤 5:计算合格率的置信区间
合格率的置信区间的计算公式为:
$$\hat{p} \pm t \times SE_{\hat{p}}$$
其中,$$\hat{p}$$为样本合格率,$$SE_{\hat{p}}$$为合格率的标准误,计算公式为:
$$SE_{\hat{p}} = \sqrt{\frac{\hat{p} (1-\hat{p})}{n}}$$