题目
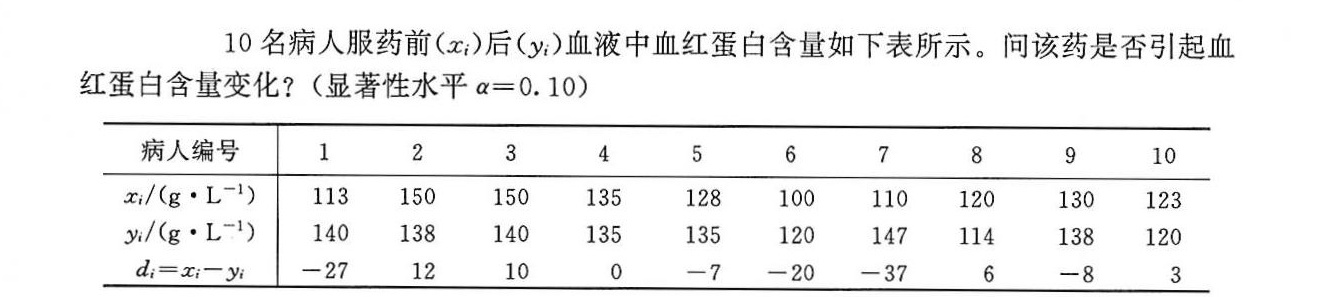
10名病人服药前(x;)后(y1)血液中血红蛋白含量如下表所示。问该药是否引起血-|||-红蛋白含量变化?(显著性水平 alpha =0.10-|||-病人编号 1 2 3 4 5 6 7 8 9 10-|||-;/(gcdot (L)^-1) 113 150 150 135 128 100 110 120 130 123-|||-:/(gcdot (L)^-1) 140 138 140 135 135 120 147 114 138 120-|||-_(i)=(x)_(i)-(y)_(i) -27 12 10 o -7 -20 -37 6 -8 3
题目解答
答案

解析
步骤 1:计算样本均值和标准差
首先,我们需要计算服药前和服药后血红蛋白含量的样本均值和标准差。根据题目给出的数据,我们有:
服药前:${x}_{i} = \{113, 150, 150, 135, 128, 100, 110, 120, 130, 123\}$
服药后:${y}_{i} = \{140, 138, 140, 135, 135, 120, 147, 114, 138, 120\}$
计算均值和标准差:
$\overline{x} = \frac{1}{10} \sum_{i=1}^{10} x_i = 126$
$\overline{y} = \frac{1}{10} \sum_{i=1}^{10} y_i = 133$
${s}_{x} = \sqrt{\frac{1}{9} \sum_{i=1}^{10} (x_i - \overline{x})^2} = 16.3$
${s}_{y} = \sqrt{\frac{1}{9} \sum_{i=1}^{10} (y_i - \overline{y})^2} = 10.8$
步骤 2:F检验
使用F检验法检验服药前和服药后血红蛋白含量的方差是否相等。计算F值:
${F}_{0} = \frac{{s}_{x}^2}{{s}_{y}^2} = \frac{16.3^2}{10.8^2} = 2.28$
设显著性水平 $\alpha = 0.10$,查F分布表,得到临界值 ${F}_{0.05}(9,9) = 3.18$。
因为 ${F}_{0} < {F}_{0.05}(9,9)$,所以服药前和服药后血红蛋白含量的方差无显著差异。
步骤 3:t检验
使用t检验法检验服药前和服药后血红蛋白含量的均值是否相等。计算t值:
${t}_{0} = \frac{\overline{x} - \overline{y}}{\sqrt{\frac{{s}_{x}^2}{n_x} + \frac{{s}_{y}^2}{n_y}}} = \frac{126 - 133}{\sqrt{\frac{16.3^2}{10} + \frac{10.8^2}{10}}} = -1.13$
查t分布表,得到临界值 ${t}_{0.10}(18) = 1.73$。
因为 $|{t}_{0}| < {t}_{0.10}(18)$,所以服药前和服药后血红蛋白含量的均值无显著差异。
首先,我们需要计算服药前和服药后血红蛋白含量的样本均值和标准差。根据题目给出的数据,我们有:
服药前:${x}_{i} = \{113, 150, 150, 135, 128, 100, 110, 120, 130, 123\}$
服药后:${y}_{i} = \{140, 138, 140, 135, 135, 120, 147, 114, 138, 120\}$
计算均值和标准差:
$\overline{x} = \frac{1}{10} \sum_{i=1}^{10} x_i = 126$
$\overline{y} = \frac{1}{10} \sum_{i=1}^{10} y_i = 133$
${s}_{x} = \sqrt{\frac{1}{9} \sum_{i=1}^{10} (x_i - \overline{x})^2} = 16.3$
${s}_{y} = \sqrt{\frac{1}{9} \sum_{i=1}^{10} (y_i - \overline{y})^2} = 10.8$
步骤 2:F检验
使用F检验法检验服药前和服药后血红蛋白含量的方差是否相等。计算F值:
${F}_{0} = \frac{{s}_{x}^2}{{s}_{y}^2} = \frac{16.3^2}{10.8^2} = 2.28$
设显著性水平 $\alpha = 0.10$,查F分布表,得到临界值 ${F}_{0.05}(9,9) = 3.18$。
因为 ${F}_{0} < {F}_{0.05}(9,9)$,所以服药前和服药后血红蛋白含量的方差无显著差异。
步骤 3:t检验
使用t检验法检验服药前和服药后血红蛋白含量的均值是否相等。计算t值:
${t}_{0} = \frac{\overline{x} - \overline{y}}{\sqrt{\frac{{s}_{x}^2}{n_x} + \frac{{s}_{y}^2}{n_y}}} = \frac{126 - 133}{\sqrt{\frac{16.3^2}{10} + \frac{10.8^2}{10}}} = -1.13$
查t分布表,得到临界值 ${t}_{0.10}(18) = 1.73$。
因为 $|{t}_{0}| < {t}_{0.10}(18)$,所以服药前和服药后血红蛋白含量的均值无显著差异。