题目
设在 N 件产品中有 M 件次品,现进行 n 次有放回的检查抽样,试 求抽得 k 件次品的概率.
设在 N 件产品中有 M 件次品,现进行 n 次有放回的检查抽样,试 求抽得 k 件次品的概
率.
题目解答
答案
解 由条件,这是有放回抽样, 可知每次试验是在相同条件下重复进 行,故本题符合 n 重贝努里试验的条件,令 A表示“抽到一件次品”⏺
P(A)=p=M/N,
以 Pn(k)表示 n 次有放回抽样中,有 k 次出现次品的概率,由贝努里
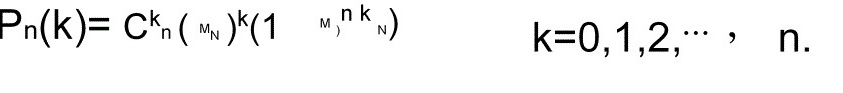 概型计算公式,可知
概型计算公式,可知
解析
考查要点:本题主要考查有放回抽样下的概率计算,核心是理解独立重复试验(贝努利试验)的应用条件,并掌握二项分布的概率公式。
解题思路:
- 明确试验性质:有放回抽样保证每次试验条件相同,且各次试验相互独立。
- 确定单次成功概率:抽到次品的概率为$\frac{M}{N}$。
- 应用二项分布公式:计算$n$次独立试验中恰好成功$k$次的概率。
破题关键:
- 有放回抽样确保独立性和相同概率,直接对应二项分布的条件。
- 正确识别“成功”(抽到次品)的概率$p = \frac{M}{N}$。
步骤1:定义事件与概率
设每次抽样“抽到次品”为事件$A$,则单次试验的成功概率为:
$p = P(A) = \frac{M}{N}$
步骤2:分析试验性质
由于是有放回抽样,每次抽样的结果相互独立,且每次抽到次品的概率均为$p$,因此属于$n$重贝努利试验。
步骤3:应用二项分布公式
在$n$次独立试验中,恰好有$k$次成功(抽到次品)的概率为:
$P_n(k) = C_n^k \cdot p^k \cdot (1-p)^{n-k}$
其中:
- $C_n^k$为组合数,表示从$n$次中选$k$次成功;
- $p^k$为$k$次成功概率;
- $(1-p)^{n-k}$为$n-k$次失败概率。
步骤4:代入具体参数
将$p = \frac{M}{N}$代入公式,得:
$P_n(k) = C_n^k \cdot \left( \frac{M}{N} \right)^k \cdot \left( 1 - \frac{M}{N} \right)^{n-k}$