题目
设sim N(mu ,1),Ysim (X)^2(4), 且X和Y相互独立, 令sim N(mu ,1),Ysim (X)^2(4) , 判断T服从何分后,给出判断过程。
设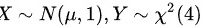 , 且X和Y相互独立, 令
, 且X和Y相互独立, 令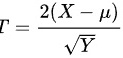 , 判断T服从何分后,给出判断过程。
, 判断T服从何分后,给出判断过程。
题目解答
答案
我们可以按照以下步骤来判断T服从何种分布:
第一步,由题目信息,我们知道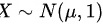 ,即X是均值为
,即X是均值为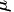 ,方差为1的正态分布。
,方差为1的正态分布。
第二步,根据题目,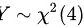 ,即Y是自由度为4的卡方分布。
,即Y是自由度为4的卡方分布。
第三步,由于X和Y相互独立,我们可以利用这一性质来推导T的分布。
第四步,根据T的表达式,我们可以发现它具有t分布的形式。在统计学中,t分布通常用于小样本情况下,当样本量足够大时,t分布趋近于正态分布。而在这里,由于Y是自由度为4的卡方分布,可以看作是4个标准正态随机变量的平方和,这与t分布的定义相符合。
第五步,根据t分布的定义,如果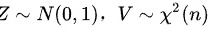 ,且Z和V相互独立,那么
,且Z和V相互独立,那么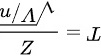 服从自由度为n的t分布。在本题中,我们可以将
服从自由度为n的t分布。在本题中,我们可以将 看作是标准正态随机变量(因为
看作是标准正态随机变量(因为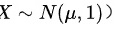 ,Y看作是自由度为4的卡方分布随机变量。因此,可以看作是
,Y看作是自由度为4的卡方分布随机变量。因此,可以看作是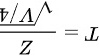 的形式,其中
的形式,其中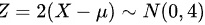 (因为线性变换不改变正态分布的形态,只会改变其均值和方差),
(因为线性变换不改变正态分布的形态,只会改变其均值和方差),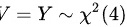 。
。
第六步,根据第五步的推导,我们可以得出T服从自由度为4的t分布,即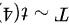 。
。
综上,我们可以判断T服从自由度为4的t分布。
解析
步骤 1:理解随机变量X和Y的分布
$X\sim N(\mu ,1)$,即X是均值为$\mu$,方差为1的正态分布。
$Y\sim {X}^{2}(4)$,即Y是自由度为4的卡方分布。
步骤 2:利用X和Y的独立性
由于X和Y相互独立,我们可以利用这一性质来推导T的分布。
步骤 3:分析T的表达式
$T=\dfrac {2(X-\mu )}{\sqrt {Y}}$,我们可以发现它具有t分布的形式。在统计学中,t分布通常用于小样本情况下,当样本量足够大时,t分布趋近于正态分布。而在这里,由于Y是自由度为4的卡方分布,可以看作是4个标准正态随机变量的平方和,这与t分布的定义相符合。
步骤 4:将T的表达式与t分布的定义进行对比
根据t分布的定义,如果$Z\sim N(0,1)$, $V\sim {x}^{2}(n)$,且Z和V相互独立,那么$\dfrac {Z}{\sqrt {V/n}}$服从自由度为n的t分布。在本题中,我们可以将$X-\mu$看作是标准正态随机变量(因为$X\sim N(\mu ,1)$),Y看作是自由度为4的卡方分布随机变量。因此,$T=\dfrac {2(X-\mu )}{\sqrt {Y}}$可以看作是$T=\dfrac {2Z}{\sqrt {V/4}}$的形式,其中$Z=X-\mu \sim N(0,1)$(因为线性变换不改变正态分布的形态,只会改变其均值和方差),$Y=Y\sim {X}^{2}(4)$。
步骤 5:得出结论
根据步骤4的推导,我们可以得出T服从自由度为4的t分布。
$X\sim N(\mu ,1)$,即X是均值为$\mu$,方差为1的正态分布。
$Y\sim {X}^{2}(4)$,即Y是自由度为4的卡方分布。
步骤 2:利用X和Y的独立性
由于X和Y相互独立,我们可以利用这一性质来推导T的分布。
步骤 3:分析T的表达式
$T=\dfrac {2(X-\mu )}{\sqrt {Y}}$,我们可以发现它具有t分布的形式。在统计学中,t分布通常用于小样本情况下,当样本量足够大时,t分布趋近于正态分布。而在这里,由于Y是自由度为4的卡方分布,可以看作是4个标准正态随机变量的平方和,这与t分布的定义相符合。
步骤 4:将T的表达式与t分布的定义进行对比
根据t分布的定义,如果$Z\sim N(0,1)$, $V\sim {x}^{2}(n)$,且Z和V相互独立,那么$\dfrac {Z}{\sqrt {V/n}}$服从自由度为n的t分布。在本题中,我们可以将$X-\mu$看作是标准正态随机变量(因为$X\sim N(\mu ,1)$),Y看作是自由度为4的卡方分布随机变量。因此,$T=\dfrac {2(X-\mu )}{\sqrt {Y}}$可以看作是$T=\dfrac {2Z}{\sqrt {V/4}}$的形式,其中$Z=X-\mu \sim N(0,1)$(因为线性变换不改变正态分布的形态,只会改变其均值和方差),$Y=Y\sim {X}^{2}(4)$。
步骤 5:得出结论
根据步骤4的推导,我们可以得出T服从自由度为4的t分布。