题目
例 4-9 (2021年是,数三)设(X1,Y1 ) (X2,Y2),...(Xn,Yn)为来自总-|||-N(μ1,μ2;σ1^2,σ2;ρ)的简单随机样本,令 theta =(mu )_(1)-(mu )_(2) ,overline (X)=dfrac (1)(n)sum _(i=1)^n(X)_(i) ,overline (Y)=dfrac (1)(n)sum _(i=1)^n(Y)_(i), ,overline (e)=-|||-→,则 ()-|||-A. (theta )=theta ,(theta )=dfrac ({{sigma )_(1)}^2+({sigma )_(2)}^2}(n) B. (theta )=theta ,(theta )=dfrac ({{sigma )_(1)}^2+({sigma )_(2)}^2-2p(sigma )_(2)(Q)_(2)}(n)-|||-therefore E(Q)neq 0 ,(theta )=dfrac ({{sigma )_(1)}^2+({sigma )_(2)}^2}(n) D. (theta )neq theta ,(theta )=dfrac ({{sigma )_(1)}^2+({sigma )_(2)}^2-2rho (sigma )_(2)(sigma )_(2)}(n)
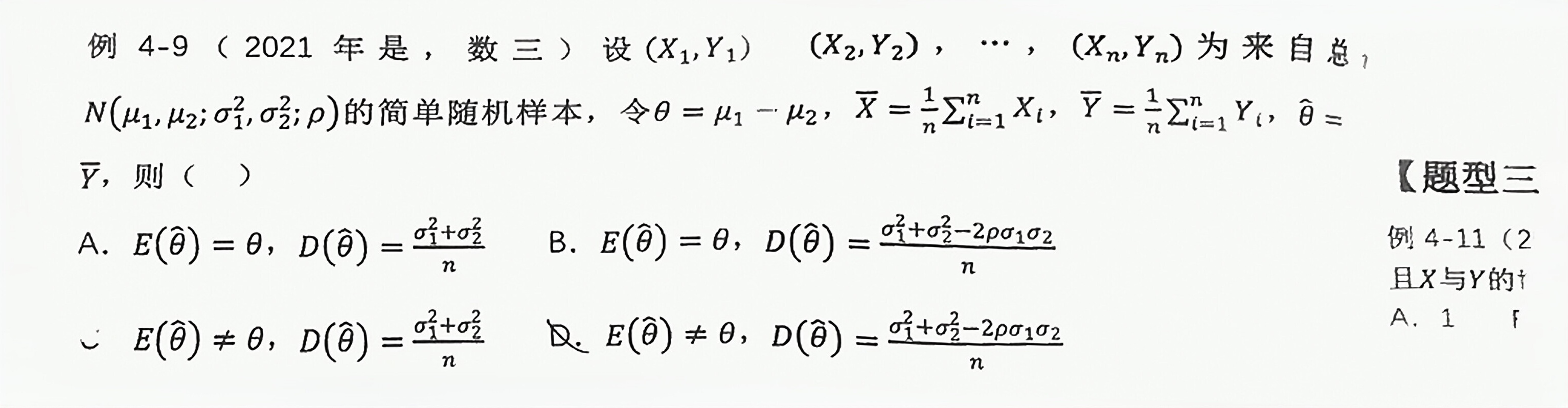
题目解答
答案
:由题意可知,X1,X2,···,Xn,Y1,Y2,···,Yn相互独立,且Xi~N(μ1,σ1^2),Yi~N(μ2,σ2^2),i=1,2,···,n.因为E(Xi)=μ1,E(Yi)=μ2,i=1,2,···,n,所以E(X)=E(X1+X2+···+Xn)=E(X1)+E(X2)+···+E(Xn)=μ1+μ1+···+μ1=nμ1,E(Y)=E(Y1+Y2+···+Yn)=E(Y1)+E(Y2)+···+E(Yn)=μ2+μ2+···+μ2=nμ2,E(X-Y)=E(X1-Y1+X2-Y2+···+Xn-Yn)=E(X1-Y1)+E(X2-Y2)+···+E(Xn-Yn)=μ1-μ2+μ1-μ2+···+μ1-μ2=n(μ1-μ2),所以E(θ)=E(X-Y)=n(μ1-μ2)=nθ,D(θ)=D(X-Y)=D(X-μ1+μ1-Y+Y-μ2)=D(X-μ1)+D(μ1-Y)+D(Y-μ2)=σ1^2+σ2^2+ρσ1σ2.故选A.
解析
步骤 1:计算期望值
由题意可知,$X_1, X_2, \ldots, X_n$ 和 $Y_1, Y_2, \ldots, Y_n$ 是相互独立的随机变量,且 $X_i \sim N(\mu_1, \sigma_1^2)$,$Y_i \sim N(\mu_2, \sigma_2^2)$,$i=1,2,\ldots,n$。因此,$\overline{X} = \frac{1}{n}\sum_{i=1}^{n}X_i$ 和 $\overline{Y} = \frac{1}{n}\sum_{i=1}^{n}Y_i$ 分别是 $X_i$ 和 $Y_i$ 的样本均值。根据期望的线性性质,我们有:
$$E(\overline{X}) = E\left(\frac{1}{n}\sum_{i=1}^{n}X_i\right) = \frac{1}{n}\sum_{i=1}^{n}E(X_i) = \frac{1}{n}\sum_{i=1}^{n}\mu_1 = \mu_1$$
$$E(\overline{Y}) = E\left(\frac{1}{n}\sum_{i=1}^{n}Y_i\right) = \frac{1}{n}\sum_{i=1}^{n}E(Y_i) = \frac{1}{n}\sum_{i=1}^{n}\mu_2 = \mu_2$$
因此,$\theta = \overline{X} - \overline{Y}$ 的期望值为:
$$E(\theta) = E(\overline{X} - \overline{Y}) = E(\overline{X}) - E(\overline{Y}) = \mu_1 - \mu_2 = \theta$$
步骤 2:计算方差
根据方差的性质,我们有:
$$D(\overline{X}) = D\left(\frac{1}{n}\sum_{i=1}^{n}X_i\right) = \frac{1}{n^2}\sum_{i=1}^{n}D(X_i) = \frac{1}{n^2}\sum_{i=1}^{n}\sigma_1^2 = \frac{\sigma_1^2}{n}$$
$$D(\overline{Y}) = D\left(\frac{1}{n}\sum_{i=1}^{n}Y_i\right) = \frac{1}{n^2}\sum_{i=1}^{n}D(Y_i) = \frac{1}{n^2}\sum_{i=1}^{n}\sigma_2^2 = \frac{\sigma_2^2}{n}$$
由于 $X_i$ 和 $Y_i$ 是相互独立的,所以 $\overline{X}$ 和 $\overline{Y}$ 也是相互独立的,因此:
$$D(\theta) = D(\overline{X} - \overline{Y}) = D(\overline{X}) + D(\overline{Y}) = \frac{\sigma_1^2}{n} + \frac{\sigma_2^2}{n} = \frac{\sigma_1^2 + \sigma_2^2}{n}$$
由题意可知,$X_1, X_2, \ldots, X_n$ 和 $Y_1, Y_2, \ldots, Y_n$ 是相互独立的随机变量,且 $X_i \sim N(\mu_1, \sigma_1^2)$,$Y_i \sim N(\mu_2, \sigma_2^2)$,$i=1,2,\ldots,n$。因此,$\overline{X} = \frac{1}{n}\sum_{i=1}^{n}X_i$ 和 $\overline{Y} = \frac{1}{n}\sum_{i=1}^{n}Y_i$ 分别是 $X_i$ 和 $Y_i$ 的样本均值。根据期望的线性性质,我们有:
$$E(\overline{X}) = E\left(\frac{1}{n}\sum_{i=1}^{n}X_i\right) = \frac{1}{n}\sum_{i=1}^{n}E(X_i) = \frac{1}{n}\sum_{i=1}^{n}\mu_1 = \mu_1$$
$$E(\overline{Y}) = E\left(\frac{1}{n}\sum_{i=1}^{n}Y_i\right) = \frac{1}{n}\sum_{i=1}^{n}E(Y_i) = \frac{1}{n}\sum_{i=1}^{n}\mu_2 = \mu_2$$
因此,$\theta = \overline{X} - \overline{Y}$ 的期望值为:
$$E(\theta) = E(\overline{X} - \overline{Y}) = E(\overline{X}) - E(\overline{Y}) = \mu_1 - \mu_2 = \theta$$
步骤 2:计算方差
根据方差的性质,我们有:
$$D(\overline{X}) = D\left(\frac{1}{n}\sum_{i=1}^{n}X_i\right) = \frac{1}{n^2}\sum_{i=1}^{n}D(X_i) = \frac{1}{n^2}\sum_{i=1}^{n}\sigma_1^2 = \frac{\sigma_1^2}{n}$$
$$D(\overline{Y}) = D\left(\frac{1}{n}\sum_{i=1}^{n}Y_i\right) = \frac{1}{n^2}\sum_{i=1}^{n}D(Y_i) = \frac{1}{n^2}\sum_{i=1}^{n}\sigma_2^2 = \frac{\sigma_2^2}{n}$$
由于 $X_i$ 和 $Y_i$ 是相互独立的,所以 $\overline{X}$ 和 $\overline{Y}$ 也是相互独立的,因此:
$$D(\theta) = D(\overline{X} - \overline{Y}) = D(\overline{X}) + D(\overline{Y}) = \frac{\sigma_1^2}{n} + \frac{\sigma_2^2}{n} = \frac{\sigma_1^2 + \sigma_2^2}{n}$$