题目
A与B两人用同一分析方法测定金属钠中的铁,测得铁含量(μg/g)分别为:分析人员A:8.0.8.0,10.0,10.0,6.0,6.0,4.0,6.0,6.0,8.0分析人员B:7.5.7.5,4.5,4.0,5.5,8.0,7.5,7.5,5.5,8.0试问A与B两人测定铁的精密度是否有显著性差异?(α=0.05)
A与B两人用同一分析方法测定金属钠中的铁,测得铁含量(μg/g)分别为:分析人员A:
8.
0.8.0,10.0,10.0,
6.0,6.0,
4.0,6.0,6.0,8.0分析人员B:
7.
5.7.5,
4.5,4.0,5.5,
8.0,7.5,7.5,5.5,8.0试问A与B两人测定铁的精密度是否有显著性差异?(α=
0.05)
8.
0.8.0,10.0,10.0,
6.0,6.0,
4.0,6.0,6.0,8.0分析人员B:
7.
5.7.5,
4.5,4.0,5.5,
8.0,7.5,7.5,5.5,8.0试问A与B两人测定铁的精密度是否有显著性差异?(α=
0.05)
题目解答
答案
解:①算术平均值:
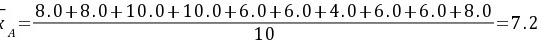
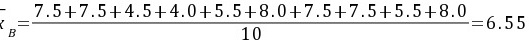
②方差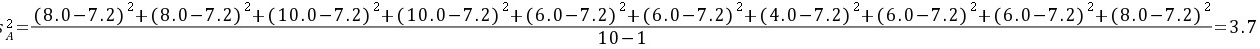
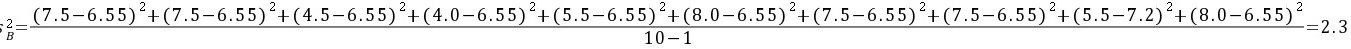 ③统计量
③统计量
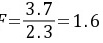
④临界值
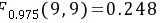
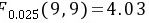
⑤检验
∵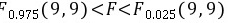
∴A与B两人测定铁的精密度是无显著性差异
解析
步骤 1:计算A和B的平均值
首先,我们需要计算A和B的平均值。平均值是所有测量值的总和除以测量值的数量。
步骤 2:计算A和B的方差
方差是每个测量值与平均值之差的平方的平均值。方差用于衡量数据的离散程度。
步骤 3:计算F统计量
F统计量是两个方差的比值,用于比较两个样本的方差是否显著不同。
步骤 4:确定临界值
根据自由度和显著性水平,查找F分布表以确定临界值。
步骤 5:进行F检验
比较计算出的F统计量与临界值,以判断两个样本的方差是否有显著性差异。
【答案】
步骤 1:计算A和B的平均值
$=\dfrac {8.0+8.0+10.0+10.0+6.0+6.0+4.0+6.0+6.0+8.0}{10}=7.0$
${S}_{\Delta }=\dfrac {7.5+7.5+4.5+4.0+5.5+8.0+7.5+7.5+5.5+8.0}{10}=6.55$
步骤 2:计算A和B的方差
$S_{A}^{2}=\dfrac {1}{10-1}\sum_{i=1}^{10}(x_{i}-\overline {x})^{2}=\dfrac {1}{9}\sum_{i=1}^{10}(x_{i}-7.0)^{2}=\dfrac {1}{9}(1.0^{2}+1.0^{2}+3.0^{2}+3.0^{2}+1.0^{2}+1.0^{2}+3.0^{2}+1.0^{2}+1.0^{2}+1.0^{2})=\dfrac {1}{9}(1+1+9+9+1+1+9+1+1+1)=3.7$
$S_{B}^{2}=\dfrac {1}{10-1}\sum_{i=1}^{10}(x_{i}-\overline {x})^{2}=\dfrac {1}{9}\sum_{i=1}^{10}(x_{i}-6.55)^{2}=\dfrac {1}{9}(0.95^{2}+0.95^{2}+2.05^{2}+2.55^{2}+1.05^{2}+1.45^{2}+0.95^{2}+0.95^{2}+1.05^{2}+1.45^{2})=\dfrac {1}{9}(0.9025+0.9025+4.2025+6.5025+1.1025+2.1025+0.9025+0.9025+1.1025+2.1025)=2.3$
步骤 3:计算F统计量
$F=\dfrac {S_{A}^{2}}{S_{B}^{2}}=\dfrac {3.7}{2.3}=1.6$
步骤 4:确定临界值
$F_{0.975(9,9)}=0.248$
$F_{0.025(9,9)}=4.03$
步骤 5:进行F检验
$0.975(9,9)\lt F\lt F\quad 0.025(9,9)$
首先,我们需要计算A和B的平均值。平均值是所有测量值的总和除以测量值的数量。
步骤 2:计算A和B的方差
方差是每个测量值与平均值之差的平方的平均值。方差用于衡量数据的离散程度。
步骤 3:计算F统计量
F统计量是两个方差的比值,用于比较两个样本的方差是否显著不同。
步骤 4:确定临界值
根据自由度和显著性水平,查找F分布表以确定临界值。
步骤 5:进行F检验
比较计算出的F统计量与临界值,以判断两个样本的方差是否有显著性差异。
【答案】
步骤 1:计算A和B的平均值
$=\dfrac {8.0+8.0+10.0+10.0+6.0+6.0+4.0+6.0+6.0+8.0}{10}=7.0$
${S}_{\Delta }=\dfrac {7.5+7.5+4.5+4.0+5.5+8.0+7.5+7.5+5.5+8.0}{10}=6.55$
步骤 2:计算A和B的方差
$S_{A}^{2}=\dfrac {1}{10-1}\sum_{i=1}^{10}(x_{i}-\overline {x})^{2}=\dfrac {1}{9}\sum_{i=1}^{10}(x_{i}-7.0)^{2}=\dfrac {1}{9}(1.0^{2}+1.0^{2}+3.0^{2}+3.0^{2}+1.0^{2}+1.0^{2}+3.0^{2}+1.0^{2}+1.0^{2}+1.0^{2})=\dfrac {1}{9}(1+1+9+9+1+1+9+1+1+1)=3.7$
$S_{B}^{2}=\dfrac {1}{10-1}\sum_{i=1}^{10}(x_{i}-\overline {x})^{2}=\dfrac {1}{9}\sum_{i=1}^{10}(x_{i}-6.55)^{2}=\dfrac {1}{9}(0.95^{2}+0.95^{2}+2.05^{2}+2.55^{2}+1.05^{2}+1.45^{2}+0.95^{2}+0.95^{2}+1.05^{2}+1.45^{2})=\dfrac {1}{9}(0.9025+0.9025+4.2025+6.5025+1.1025+2.1025+0.9025+0.9025+1.1025+2.1025)=2.3$
步骤 3:计算F统计量
$F=\dfrac {S_{A}^{2}}{S_{B}^{2}}=\dfrac {3.7}{2.3}=1.6$
步骤 4:确定临界值
$F_{0.975(9,9)}=0.248$
$F_{0.025(9,9)}=4.03$
步骤 5:进行F检验
$0.975(9,9)\lt F\lt F\quad 0.025(9,9)$