题目
随机测得某市144名新生女婴的平均出生体重位3.10 kg,标准差0.50kg,则总体均数的95%置信区间为( )。A..10pm 1.96times 0.50/2B..10pm 1.96times 0.50/2C..10pm 1.96times 0.50/2D..10pm 1.96times 0.50/2
随机测得某市144名新生女婴的平均出生体重位3.10 kg,标准差0.50kg,则总体均数的95%置信区间为( )。
A.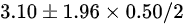
B.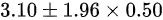
C.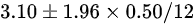
D.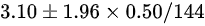
题目解答
答案
由于总体标准差未知,且样本量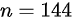 较大(
较大(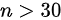 30" data-width="61" data-height="20" data-size="1018" data-format="png" style="max-width:100%">),可以用样本标准差
30" data-width="61" data-height="20" data-size="1018" data-format="png" style="max-width:100%">),可以用样本标准差 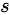 近似代替总体标准差
近似代替总体标准差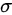 ,此时总体均数的
,此时总体均数的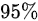 置信区间为:
置信区间为:
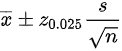 ,已知
,已知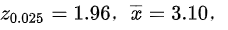
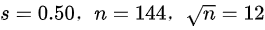 .
.
所以置信区间为: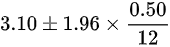
故答案为C选项.
解析
考查要点:本题主要考查大样本情况下总体均数的置信区间计算,涉及标准误和z值的应用。
解题核心思路:
- 判断样本量:题目中样本量$n=144$,属于大样本($n>30$),可用正态分布(z值)近似计算。
- 确定公式:总体均数的置信区间公式为$\overline{x} \pm z_{\alpha/2} \cdot \frac{s}{\sqrt{n}}$,其中$s$为样本标准差,$\sqrt{n}$为标准误的分母。
- 代入数据:将$\overline{x}=3.10$,$s=0.50$,$n=144$代入公式,计算临界值$z_{0.025}=1.96$。
破题关键点:
- 区分标准差与标准误:标准误需将样本标准差除以$\sqrt{n}$,而非直接使用标准差。
- 排除干扰项:注意选项中是否包含$\sqrt{n}$,避免混淆除以$n$或$2$的情况。
公式推导
总体均数的95%置信区间公式为:
$\overline{x} \pm z_{\alpha/2} \cdot \frac{s}{\sqrt{n}}$
其中:
- $\overline{x}=3.10$(样本均值)
- $s=0.50$(样本标准差)
- $n=144$(样本量)
- $z_{0.025}=1.96$(95%置信水平对应的临界值)
代入计算
- 计算标准误:
$\frac{s}{\sqrt{n}} = \frac{0.50}{\sqrt{144}} = \frac{0.50}{12} \approx 0.0417$ - 计算置信区间:
$3.10 \pm 1.96 \times 0.0417 \approx 3.10 \pm 0.0816$
选项分析
- 选项C正确体现了公式$\overline{x} \pm 1.96 \times \frac{0.50}{12}$。
- 其他选项错误原因:
- A:误将分母写为$2$(应为$\sqrt{144}=12$)。
- B:未除以$\sqrt{n}$,直接使用标准差。
- D:误将分母写为$n=144$(应为$\sqrt{n}=12$)。