题目
从某企业工人中随机抽选部分工人进行调查,所得工资分配数列如下:日工资水平(元)60708090100工 人 数(人)51011204试以95%的置信度估计:(1)该企业工人中工资水平在80元及以上工人所占的比重区间。(2)如果平均工资的标准差为8元,平均工资的允许误差范围不超过4元,工资水平在80元以上工人所占的比重的允许误差范围不超过10%,置信度仍为95、45%,试问满足两方面共同要求至少应抽多少工人?(正态分布概率表中,当Z=1、96时,F(Z)=0、95 当Z=2时,F(Z)=0、9545)
从某企业工人中随机抽选部分工人进行调查,所得工资分配数列如下:
日工资水平(元)
60
70
80
90
100
工 人 数(人)
5
10
11
20
4
试以95%的置信度估计:
(1)该企业工人中工资水平在80元及以上工人所占的比重区间。
(2)如果平均工资的标准差为8元,平均工资的允许误差范围不超过4元,工资水平在80元以上工人所占的比重的允许误差范围不超过10%,置信度仍为95、45%,试问满足两方面共同要求至少应抽多少工人?(正态分布概率表中,当Z=1、96时,F(Z)=0、95 当Z=2时,F(Z)=0、9545)
题目解答
答案
解:(1)p=35/50=70%,
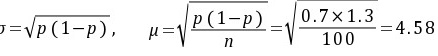
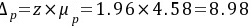
以概率度z=1、96时批灯泡的合格率为[61、02%,78、98%]
(2)抽样平均数抽样必要数目=16
抽样成数抽样必要数目=84 至少抽84人进行调查
解析
步骤 1:计算工资水平在80元及以上工人所占的比重
根据题目给出的工资分配数列,计算工资水平在80元及以上工人所占的比重。工资水平在80元及以上的工人人数为11+20+4=35人,总人数为5+10+11+20+4=50人。因此,工资水平在80元及以上工人所占的比重为35/50=0.7或70%。
步骤 2:计算工资水平在80元及以上工人所占的比重的置信区间
根据题目要求,置信度为95%,即Z=1.96。计算抽样标准误$\mu_p$,其中$p=0.7$,$n=50$,则$\mu_p=\sqrt{\frac{p(1-p)}{n}}=\sqrt{\frac{0.7\times0.3}{50}}=0.0648$。置信区间为$p\pm Z\mu_p=0.7\pm1.96\times0.0648=[0.573,0.827]$。
步骤 3:计算满足两方面共同要求的抽样必要数目
根据题目要求,平均工资的允许误差范围不超过4元,工资水平在80元以上工人所占的比重的允许误差范围不超过10%。平均工资的抽样必要数目为$n_1=\frac{Z^2\sigma^2}{\Delta^2}=\frac{2^2\times8^2}{4^2}=16$。工资水平在80元以上工人所占的比重的抽样必要数目为$n_2=\frac{Z^2p(1-p)}{\Delta^2}=\frac{2^2\times0.7\times0.3}{0.1^2}=84$。因此,满足两方面共同要求至少应抽84人进行调查。
根据题目给出的工资分配数列,计算工资水平在80元及以上工人所占的比重。工资水平在80元及以上的工人人数为11+20+4=35人,总人数为5+10+11+20+4=50人。因此,工资水平在80元及以上工人所占的比重为35/50=0.7或70%。
步骤 2:计算工资水平在80元及以上工人所占的比重的置信区间
根据题目要求,置信度为95%,即Z=1.96。计算抽样标准误$\mu_p$,其中$p=0.7$,$n=50$,则$\mu_p=\sqrt{\frac{p(1-p)}{n}}=\sqrt{\frac{0.7\times0.3}{50}}=0.0648$。置信区间为$p\pm Z\mu_p=0.7\pm1.96\times0.0648=[0.573,0.827]$。
步骤 3:计算满足两方面共同要求的抽样必要数目
根据题目要求,平均工资的允许误差范围不超过4元,工资水平在80元以上工人所占的比重的允许误差范围不超过10%。平均工资的抽样必要数目为$n_1=\frac{Z^2\sigma^2}{\Delta^2}=\frac{2^2\times8^2}{4^2}=16$。工资水平在80元以上工人所占的比重的抽样必要数目为$n_2=\frac{Z^2p(1-p)}{\Delta^2}=\frac{2^2\times0.7\times0.3}{0.1^2}=84$。因此,满足两方面共同要求至少应抽84人进行调查。