题目
[1.15]设随机变量x1,x2,···,xn,···相互独立,且X1都服从参数为 dfrac (1)(2) 的指数分布,则当n-|||-充分大时,随机变量 _(n)=dfrac (1)(n)sum _(i=1)^n(X)_(i) 的概率分布近似服从 ()-|||-(A)N(2,4) (B) (2,dfrac (4)(n)) (C) (dfrac (1)(2),dfrac (1)(4n)) (D)N(2n,4 n)

题目解答
答案
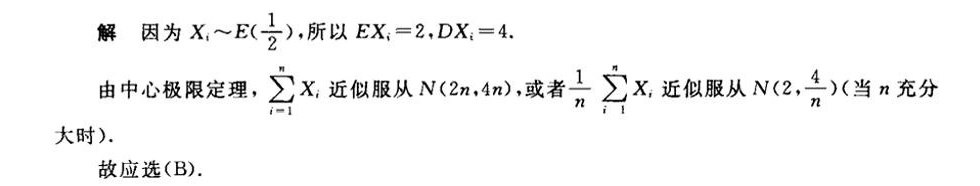
解析
步骤 1:确定随机变量的期望和方差
由于 ${X}_{i}$ 都服从参数为 $\dfrac {1}{2}$ 的指数分布,我们知道指数分布的期望和方差分别为 $\dfrac {1}{\lambda}$ 和 $\dfrac {1}{{\lambda}^{2}}$。因此,对于 ${X}_{i}$,我们有:
$$E{X}_{i} = \dfrac {1}{\dfrac {1}{2}} = 2$$
$$DX_{i} = \dfrac {1}{{\left(\dfrac {1}{2}\right)}^{2}} = 4$$
步骤 2:应用中心极限定理
根据中心极限定理,当n充分大时,随机变量的和 $\sum _{i=1}^{n}{X}_{i}$ 近似服从正态分布。因此,$\sum _{i=1}^{n}{X}_{i}$ 近似服从 $N(nE{X}_{i}, nDX_{i})$,即 $N(2n, 4n)$。
步骤 3:计算标准化后的随机变量
由于 ${Z}_{n}=\dfrac {1}{n}\sum _{i=1}^{n}{X}_{i}$,我们可以通过标准化得到 ${Z}_{n}$ 的分布。根据步骤2,$\sum _{i=1}^{n}{X}_{i}$ 近似服从 $N(2n, 4n)$,因此 ${Z}_{n}$ 近似服从 $N(\dfrac {2n}{n}, \dfrac {4n}{n^{2}})$,即 $N(2, \dfrac {4}{n})$。
由于 ${X}_{i}$ 都服从参数为 $\dfrac {1}{2}$ 的指数分布,我们知道指数分布的期望和方差分别为 $\dfrac {1}{\lambda}$ 和 $\dfrac {1}{{\lambda}^{2}}$。因此,对于 ${X}_{i}$,我们有:
$$E{X}_{i} = \dfrac {1}{\dfrac {1}{2}} = 2$$
$$DX_{i} = \dfrac {1}{{\left(\dfrac {1}{2}\right)}^{2}} = 4$$
步骤 2:应用中心极限定理
根据中心极限定理,当n充分大时,随机变量的和 $\sum _{i=1}^{n}{X}_{i}$ 近似服从正态分布。因此,$\sum _{i=1}^{n}{X}_{i}$ 近似服从 $N(nE{X}_{i}, nDX_{i})$,即 $N(2n, 4n)$。
步骤 3:计算标准化后的随机变量
由于 ${Z}_{n}=\dfrac {1}{n}\sum _{i=1}^{n}{X}_{i}$,我们可以通过标准化得到 ${Z}_{n}$ 的分布。根据步骤2,$\sum _{i=1}^{n}{X}_{i}$ 近似服从 $N(2n, 4n)$,因此 ${Z}_{n}$ 近似服从 $N(\dfrac {2n}{n}, \dfrac {4n}{n^{2}})$,即 $N(2, \dfrac {4}{n})$。