两组样本率比较若不拒绝0H则认为两组样本率的差异由( )所致 A.样本例数太少 B.不能确定 C. 第 1 类错误 D.抽样误差 E.两者来自不同总体
两组样本率比较若不拒绝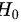 则认为两组样本率的差异由( )所致
则认为两组样本率的差异由( )所致
A.样本例数太少
B.不能确定
C. 第 1 类错误
D.抽样误差
E.两者来自不同总体
题目解答
答案
根据题目描述,当两组样本率的差异较小,不拒绝 (零假设)时,会认为两组样本率的差异由抽样误差引起。
A. 样本例数太少:样本例数较少可能导致统计推断的不准确性,但与拒绝或不拒绝 并无直接关系。
B. 不能确定:题目描述中指出两组样本率的差异较小,因此可以确定样本率之间的差异较小,而不是不能确定。
C. 第 1 类错误:第 1 类错误是指在零假设为真时拒绝 的错误。题目中并没有涉及拒绝的情况,因此与第 1 类错误无关。
D. 抽样误差:抽样误差是指由于样本选择方式引起的统计推断的误差。当样本率之间的差异较小时,由于抽样误差的影响,我们可能无法显著地检测到这些差异,导致不拒绝 。因此,抽样误差是导致题目中所描述情况的最合适解释。
E. 两者来自不同总体:题目并没有提及两组样本来自不同的总体,因此与该情况无关。
因此,正确答案是 D.抽样误差。
解析
考查要点:本题主要考查假设检验中不拒绝零假设(H₀)时对结果的合理解释,重点理解抽样误差与统计推断的关系。
核心思路:
当统计检验结果不拒绝H₀时,说明现有数据不足以支持两组样本来自不同总体的结论。此时,样本率的差异更可能由抽样误差引起,而非实际总体存在差异。需注意区分抽样误差与样本量不足、第一类错误等概念。
破题关键:
- H₀不拒绝 ≠ H₀一定正确,仅说明差异未达到统计学显著性。
- 抽样误差是随机波动导致的样本与总体之间的差异,是统计推断中必然存在的因素。
- 第一类错误(C选项)是拒绝正确H₀的错误,与本题“不拒绝H₀”无关。
选项逐一分析:
-
A. 样本例数太少
样本量不足可能导致检验效能降低(即无法检测到真实存在的差异),但题目未提及样本量是否足够,且“不拒绝H₀”本身无法直接推断样本量问题。 -
B. 不能确定
题目明确指出“不拒绝H₀”,说明已有数据支持差异可能由随机误差解释,而非“不能确定”。 -
C. 第1类错误
第1类错误是错误拒绝H₀,而本题是“不拒绝H₀”,二者无关。 -
D. 抽样误差
正确选项。不拒绝H₀时,差异更可能由抽样误差导致,即两组样本来自同一总体,随机波动引起观察差异。 -
E. 两者来自不同总体
若两组来自不同总体,差异应显著,导致拒绝H₀。本题未拒绝H₀,故排除此选项。