θ1,θ2是常数θ的两个无偏估计量,若θ1,θ2是常数θ,则称θ1,θ2是常数θ比θ1,θ2是常数θ有效。1、设A、B为随机事件,且P(A)=0.4,P(B)=0.3,P(A∪B)=0.6,则P(θ1,θ2是常数θ)=_0.3__。2、设XB(2,p),YB(3,p),且P(X≥1)=θ1,θ2是常数θ,则P(Y≥1)=θ1,θ2是常数θ。3、设随机变量X服从参数为2的泊松分布,且Y=3X-2,则E(Y)=4 。4、设随机变量X服从[0,2]上的均匀分布,Y=2X+1,则D(Y)=4/3。5、设随机变量X的概率密度是:θ1,θ2是常数θ,且θ1,θ2是常数θ,则θ1,θ2是常数θ=0.6。6、利用正态分布的结论,有θ1,θ2是常数θ1。7、已知随机向量(X,Y)的联合密度函数θ1,θ2是常数θ,则E(Y)=3/4。8、设(X,Y)为二维随机向量,D(X)、D(Y)均不为零。若有常数a>0与b使θ1,θ2是常数θ,则X与Y的相关系数θ1,θ2是常数θ-1。9、若随机变量X~N(1,4),Y~N(2,9),且X与Y相互独立。设Z=X-Y+3,则Z~N(2,13)。10、设随机变量X~N(1/2,2),以Y表示对X的三次独立重复观察中“θ1,θ2是常数θ”出现的次数,则θ1,θ2是常数θ=3/8。1、设A,B为随机事件,且P(A)=0.7,P(A-B)=0.3,则θ1,θ2是常数θ0.6。四(3)、已知连续型随机变量X的概率密度为求(1)a;(2)X的分布函数F(x);(3)P(X>0.25)。
 的两个无偏估计量,若
的两个无偏估计量,若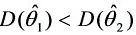 ,则称
,则称 比
比 有效。
有效。
1、设A、B为随机事件,且P(A)=0.4,P(B)=0.3,P(A∪B)=0.6,则P( )=_0.3__。
)=_0.3__。
2、设XB(2,p),YB(3,p),且P{X≥1}=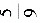 ,则P{Y≥1}=
,则P{Y≥1}=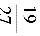 。
。
3、设随机变量X服从参数为2的泊松分布,且Y=3X-2,则E(Y)=4 。
4、设随机变量X服从[0,2]上的均匀分布,Y=2X+1,则D(Y)=4/3。
5、设随机变量X的概率密度是:
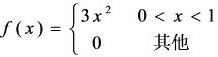 ,且
,且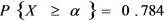 ,则
,则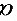 =0.6。
=0.6。
6、利用正态分布的结论,有
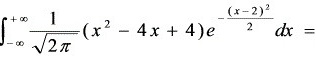 1。
1。
7、已知随机向量(X,Y)的联合密度函数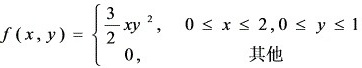 ,则E(Y)=3/4。
,则E(Y)=3/4。
8、设(X,Y)为二维随机向量,D(X)、D(Y)均不为零。若有常数a>0与b使
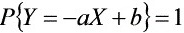 ,则X与Y的相关系数
,则X与Y的相关系数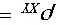 -1。
-1。
9、若随机变量X~N(1,4),Y~N(2,9),且X与Y相互独立。设Z=X-Y+3,则Z~N(2,13)。
10、设随机变量X~N(1/2,2),以Y表示对X的三次独立重复观察中“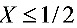 ”出现的次数,则
”出现的次数,则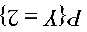 =3/8。
=3/8。
1、设A,B为随机事件,且P(A)=0.7,P(A-B)=0.3,则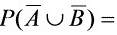 0.6。
0.6。
四(3)、已知连续型随机变量X的概率密度为
求(1)a;(2)X的分布函数F(x);(3)P(X>0.25)。
题目解答
答案
解:
(3)P(X>1/4)=1—F(1/4)=7/8
四(4)、已知连续型随机变量X的概率密度为
求(1)A;(2)分布函数F(x);(3)P(-0.5
解:
(3)P(-0.5
四(5)、已知连续型随即变量X的概率密度为
求(1)c;(2)分布函数F(x);(3)P(-0.5
解:
(3)P(-0.5
四(6)、已知连续型随机变量X的分布函数为
求(1)A,B;(2)密度函数f(x);(3)P(1
解:
(3)P(1
四(7)、已知连续型随机变量X的分布函数为
求(1)A,B;(2)密度函数f(x);(3)P(1
解:
(3)P(0
四(8)、已知连续型随机变量X的分布函数为
求(1)A;(2)密度函数f(x);(3)P(0
解:
(3)P(0
四(9)、已知连续型随机变量X的分布函数为
求(1)A;(2)密度函数f(x);(3)P(0≤X≤4)。
、解:
(3)P(0
四(10)、已知连续型随机变量X的密度函数为
求(1)a;(2)分布函数F(x);(3)P(-0.5
解:
(3)P(-0.5
五(1)、设系统L由两个相互独立的子系统L1,L2并联而成,且L1、L2的寿命分别服从参数为的指数分布。求系统L的寿命Z的密度函数。
解:令X、Y分别为子系统L1、L2的寿命,则系统L的寿命Z=max(X,Y)。
显然,当z≤0时,FZ(z)=P(Z≤z)=P(max(X,Y)≤z)=0;
当z>0时,FZ(z)=P(Z≤z)=P(max(X,Y)≤z)
=P(X≤z,Y≤z)=P(X≤z)P(Y≤z)==。
因此,系统L的寿命Z的密度函数为
fZ(z)=
五(2)、已知随机变量X~N(0,1),求随机变量Y=X2的密度函数。
解:当y≤0时,FY(y)=P(Y≤y)=P(X2≤y)=0;
当y>0时,FY(y)=P(Y≤y)=P(X2≤y)=
=
因此,fY(y)=
五(3)、设系统L由两个相互独立的子系统L1、L2串联而成,且L1、L2的寿命分别服从参数为的指数分布。求系统L的寿命Z的密度函数。
解:令X、Y分别为子系统L1、L2的寿命,则系统L的寿命Z=min(X,Y)。
显然,当z≤0时,FZ(z)=P(Z≤z)=P(min(X,Y)≤z)=0;
当z>0时,FZ(z)=P(Z≤z)=P(min(X,Y)≤z)=1-P(min(X,Y)>z)
=1-P(X>z,Y>z)=1-P(X>z)P(Y>z)==。
因此,系统L的寿命Z的密度函数为
fZ(z)=
五(4)、已知随机变量X~N(0,1),求Y=|X|的密度函数。
解:当y≤0时,FY(y)=P(Y≤y)=P(|X|≤y)=0;
当y>0时,FY(y)=P(Y≤y)=P(|X|≤y)=
=
因此,fY(y)=
五(5)、设随机向量(X,Y)联合密度为
f(x,y)=
(1)求系数A;
(2)判断X,Y是否独立,并说明理由;
(3)求P{0≤X≤2,0≤Y≤1}。
解:(1)由1==
可得A=6。
(2)因(X,Y)关于X和Y的边缘概率密度分别为
fX(x)=和fY(y)=,
则对于任意的均成立f(x,y)=fX(x)*fY(y),所以X与Y独立。
(3)P{0≤X≤2,0≤Y≤1}=
=
五(6)、设随机向量(X,Y)联合密度为
f(x,y)=
(1)求系数A;
(2)判断X,Y是否独立,并说明理由;
(3)求P{0≤X≤1,0≤Y≤1}。
解:(1)由1=
=可得A=12。
(2)因(X,Y)关于X和Y的边缘概率密度分别为
fX(x)=和fY(y)=,
则对于任意的均成立f(x,y)=fX(x)*fY(y),所以X与Y独立。
(3)P{0≤X≤1,0≤Y≤1}=
=
五(7)、设随机向量(X,Y)联合密度为
f(x,y)=
(1)求(X,Y)分别关于X和Y的边缘概率密度fX(x),fY(y);
(2)判断X,Y是否独立,并说明理由。
解:(1)当x<0或x>1时,fX(x)=0;
当0≤x≤1时,fX(x)=
因此,(X,Y)关于X的边缘概率密度fX(x)=
当y<0或y>1时,fY(y)=0;
当0≤y≤1时,fY(y)=
因此,(X,Y)关于Y的边缘概率密度fY(y)=
(2)因为f(1/2,1/2)=3/2,而fX(1/2)fY(1/2)=(3/2)*(3/4)=9/8≠f(1/2,1/2),
所以,X与Y不独立。
五(8)、设二维随机向量(X,Y)的联合概率密度为
f(x,y)=
(1)求(X,Y)分别关于X和Y的边缘概率密度fX(x),fY(y);
(2)判断X与Y是否相互独立,并说明理由。
解:(1)当x≤0时,fX(x)=0;
当x>0时,fX(x)=
因此,(X,Y)关于X的边缘概率密度fX(x)=
当y≤0时,fY(y)=0;
当y>0时,fY(y)=
因此,(X,Y)关于Y的边缘概率密度fY(y)=
(2)因为f(1,2)=e-2,而fX(1)fY(2)=e1、*2e2、=2e3、≠f(1,2),
所以,X与Y不独立。
五(9)、设随机变量X的概率密度为
设F(x)是X的分布函数,求随机变量Y=F(X)的密度函数。
解:当y<0时,FY(y)=P(Y≤y)=P(F(X)≤y)=0;
当y>1时,FY(y)=P(Y≤y)=P(F(X)≤y)=1;
当0≤y≤1时,FY(y)=P(Y≤y)=P((F(X)≤y)=
=
因此,fY(y)=
五(10)、设随机向量(X,Y)联合密度为
f(x,y)=
(1)求(X,Y)分别关于X和Y的边缘概率密度fX(x),fY(y);
(2)判断X,Y是否独立,并说明理由。
解:(1)当x<0或x>1时,fX(x)=0;
当0≤x≤1时,fX(x)=
因此,(X,Y)关于X的边缘概率密度fX(x)=
当y<0或y>1时,fY(y)=0;
当0≤y≤1时,fY(y)=
因此,(X,Y)关于Y的边缘概率密度fY(y)=
(2)因为f(1/2,1/2)=2,而fX(1/2)fY(1/2)=(3/2)*(1/2)=3/4≠f(1/2,1/2),
所以,X与Y不独立。
六(1)、已知随机向量(X,Y)的协方差矩阵V为
求随机向量(X+Y,X—Y)的协方差矩阵与相关系数矩阵。
解:D(X+Y)=DX+DY+2Cov(X,Y)=7+9+2*6=28
D(X-Y)=DX+DY2、Cov(X,Y)=7+92、*6=4
Cov(X+Y,X-Y)=DX-DY=7-9=2、
所以,(X+Y,X—Y)的协方差矩阵与相关系数矩阵分别为和
六(2)、已知随机向量(X,Y)的协方差矩阵V为
求随机向量(X+Y,X—Y)的协方差矩阵与相关系数矩阵。
解:D(X+Y)=DX+DY+2Cov(X,Y)=9+1+2*2=14
D(X-Y)=DX+DY2、Cov(X,Y)=9+12、*2=6
Cov(X+Y,X-Y)=DX-DY=91、=8
所以,(X+Y,X—Y)的协方差矩阵与相关系数矩阵分别为和
六(3)、已知随机向量(X,Y)的协方差矩阵V为
求随机向量(X—Y,X+Y)的协方差矩阵与相关系数矩阵。
解:D(X-Y)=DX+DY2、Cov(X,Y)=9+62、*(-6)=27
D(X+Y)=DX+DY+2Cov(X,Y)=9+6+2*(-6)=3
Cov(X-Y,X+Y)=DX-DY=9-6=3
所以,(X—Y,X+Y)的协方差矩阵与相关系数矩阵分别为和
六(4)、已知随机向量(X,Y)的协方差矩阵V为
求随机向量(X—Y,X+Y)的协方差矩阵与相关系数矩阵。
解:D(X-Y)=DX+DY2、Cov(X,Y)=4+92、*(-5)=23
D(X+Y)=DX+DY+2Cov(X,Y)=4+9+2*(-5)=3
Cov(X-Y,X+Y)=DX-DY=4-9=-5
所以,(X—Y,X+Y)的协方差矩阵与相关系数矩阵分别为和
六(5)、已知随机向量(X,Y)的协方差矩阵V为
求随机向量(X—Y,X+Y)的协方差矩阵与相关系数矩阵。
解:D(X-Y)=DX+DY2、Cov(X,Y)=1+42、*(1、)=7
D(X+Y)=DX+DY+2Cov(X,Y)=1+4+2*(1、)=3
Cov(X-Y,X+Y)=DX-DY=1-4=3、
所以,(X—Y,X+Y)的协方差矩阵与相关系数矩阵分别为和
求随机向量(X+Y,X—Y)的协方差矩阵与相关系数矩阵。
解:D(X+Y)=DX+DY+2Cov(X,Y)=5+4+2*2=13
D(X-Y)=DX+DY2、Cov(X,Y)=5+42、*2=5
Cov(X+Y,X-Y)=DX-DY=5-4=1
七(1)、设总体X的概率密度函数是
其中为未知参数。是一组样本值,求参数的最大似然估计。
解:似然函数
七(3)、设总体X的概率密度函数是
>0为未知参数,是一组样本值,求参数的最大似然估计。
解:似然函数
七(4)、设总体的概率密度函数是
其中>0是未知参数,是一组样本值,求参数的最大似然估计。
解:似然函数
七(5)、设总体X服从参数为的泊松分布(=0,1,),其中为未知参数,是一组样本值,求参数的最大似然估计。
解:似然函数
七(6)、设总体X的概率分布为。设为总体X的一组简单随机样本,试用最大似然估计法求p的估计值。
解:
七(7)、设总体X服从参数为的指数分布,是一组样本值,求参数的最大似然估计。
解:
七(8)、设总体X服从参数为的指数分布,是一组样本值,求参数的最大似然估计。
解:似然函数
七(9)、设总体X的概率密度函数是
是一组样本值,求参数的最大似然估计?
解:似然函数
七(10)、设总体X的概率密度函数是
是一组样本值,求参数的最大似然估计?
解:似然函数
八(1)、从某同类零件中抽取9件,测得其长度为(单位:mm):
6.05.75.86.57.06.35.66.15.0
设零件长度X服从正态分布N(μ,1)。求μ的置信度为0.95的置信区间。
、解:由于零件的长度服从正态分布,所以
所以的置信区间为经计算
的置信度为0.95的置信区间为即(5.347,6.653)
八(2)、某车间生产滚珠,其直径X~N(,0.05),从某天的产品里随机抽出9个量得直径如下(单位:毫米):
14.615.114.914.815.215.114.815.014.7
若已知该天产品直径的方差不变,试找出平均直径的置信度为0.95的置信区间。
解:由于滚珠的直径X服从正态分布,所以
所以的置信区间为:经计算
的置信度为0.95的置信区间为
即(14.765,15.057)
八(3)、工厂生产一种零件,其口径X(单位:毫米)服从正态分布,现从某日生产的零件中随机抽出9个,分别测得其口径如下:
14.614.715.114.914.815.015.115.214.7
已知零件口径X的标准差,求的置信度为0.95的置信区间。
解:由于零件的口径服从正态分布,所以
所以的置信区间为:经计算
的置信度为0.95的置信区间为即(14.802,14.998)
八(4)、随机抽取某种炮弹9发做实验,测得炮口速度的样本标准差S=3(m/s),设炮口速度服从正态分布,求这种炮弹的炮口速度的方差的置信度为0.95的置信区间。
因为炮口速度服从正态分布,所以
的置信区间为:
的置信度0.95的置信区间为即
八(5)、设某校女生的身高服从正态分布,今从该校某班中随机抽取9名女生,测得数据经计算如下:。求该校女生身高方差的置信度为0.95的置信区间。
解:因为学生身高服从正态分布,所以
的置信区间为: 的置信度0.95的置信区间为即
八(6)、一批螺丝钉中,随机抽取9个,测得数据经计算如下:。设螺丝钉的长度服从正态分布,试求该批螺丝钉长度方差的置信度为0.95的置信区间。
解:因为螺丝钉的长度服从正态分布,所以
的置信区间为:
的置信度0.95的置信区间为即
八(7)、从水平锻造机的一大批产品随机地抽取20件,测得其尺寸的平均值,样本方差。假定该产品的尺寸X服从正态分布,其中与均未知。求的置信度为0.95的置信区间。
解:由于该产品的尺寸服从正态分布,所以
的置信区间为:
的置信度0.95的置信区间为即
八(8)、已知某批铜丝的抗拉强度X服从正态分布。从中随机抽取9根,经计算得其标准差为8.069。求的置信度为0.95的置信区间。
()
解:由于抗拉强度服从正态分布所以,
的置信区间为:
的置信度为0.95的置信区间为,即
八(9)、设总体X~,从中抽取容量为16的一个样本,样本方差,试求总体方差的置信度为0.95的置信区间。
解:由于X~,所以
的置信区间为:
的置信度0.95的置信区间为,即
八(10)、某岩石密度的测量误差X服从正态分布,取样本观测值16个,得样本方差,试求的置信度为95%的置信区间。
解:由于X~,所以
的置信区间为:
的置信度0.95的置信区间为:即
九(1)、某厂生产铜丝,生产一向稳定,现从其产品中随机抽取10段检查其折断力,测得。假定铜丝的折断力服从正态分布,问在显著水平下,是否可以相信该厂生产的铜丝折断力的方差为16?
解:待检验的假设是选择统计量在成立时
取拒绝域w={}
由样本数据知
接受,即可相信这批铜丝折断力的方差为16。
九(2)、已知某炼铁厂在生产正常的情况下,铁水含碳量X服从正态分布,其方差为0.03。在某段时间抽测了10炉铁水,测得铁水含碳量的样本方差为0.0375。试问在显著水平下,这段时间生产的铁水含碳量方差与正常情况下的方差有无显著差异?
解:待检验的假设是选择统计量在成立时
取拒绝域w={}
由样本数据知
接受,即可相信这批铁水的含碳量与正常情况下的方差无显著差异。
九(3)、某厂加工一种零件,已知在正常的情况其长度服从正态分布,现从一批产品中抽测20个样本,测得样本标准差S=1.2。问在显著水平下,该批产品的标准差是否有显著差异?
解:待检验的假设是选择统计量在成立时
取拒绝域w={}
由样本数据知
拒绝,即认为这批产品的标准差有显著差异。
九(4)、已知某炼铁厂在生产正常的情况下,铁水含碳量X服从正态分布。现抽测了9炉铁水,算得铁水含碳量的平均值,若总体方差没有显著差异,即,问在显著性水平下,总体均值有无显著差异?
解:待检验的假设是选择统计量在成立时
取拒绝域w={}
由样本数据知拒绝,即认为总体均值有显著差异。
九(5)、已知某味精厂袋装味精的重量X~,其中=15,,技术革新后,改用新机器包装。抽查9个样品,测定重量为(单位:克)
14.715.114.815.015.314.915.214.615.1
已知方差不变。问在显著性水平下,新机器包装的平均重量是否仍为15?
解:待检验的假设是选择统计量在成立时
取拒绝域w={}
经计算
接受,即可以认为袋装的平均重量仍为15克。
九(6)、某手表厂生产的男表表壳在正常情况下,其直径(单位:mm)服从正态分布N(20,1)。在某天的生产过程中,随机抽查4只表壳,测得直径分别为:19.519.820.020.5.
问在显著性水平下,这天生产的表壳的均值是否正常?
解:待检验的假设为选择统计量当成立时,U~
取拒绝域w={}经计算
接受,即认为表壳的均值正常。
九(7)、某切割机在正常工作时,切割得每段金属棒长服从正态分布,且其平均长度为10.5cm,标准差为0.15cm。今从一批产品中随机抽取16段进行测量,计算平均长度为=10.48cm。假设方差不变,问在显著性水平下,该切割机工作是否正常?
解:待检验的假设为选择统计量当成立时,U~ 取拒绝域w={}
由已知接受,即认为切割机工作正常。
九(8)、某厂生产某种零件,在正常生产的条件下,这种零件的周长服从正态分布,均值为0.13厘米。如果从某日生产的这种零件中任取9件测量后得=0.146厘米,S=0.016厘米。问该日生产的零件的平均轴长是否与往日一样?
()
解:待检验的假设为选择统计量当成立时,T~t(8)
取拒绝域w={}
由已知
拒绝,即认为该生产的零件的平均轴长与往日有显著差异。