题目
某批矿砂的5个样品中的镍含量( % ),经测定得overline (x)=3.252,overline (x)=3.252,设测定值总体overline (x)=3.252服从overline (x)=3.252,但overline (x)=3.252未知,问在显著性水平overline (x)=3.252下,能否接受假设:这批矿砂的镍含量的均值为3.25? (overline (x)=3.252,overline (x)=3.252, overline (x)=3.252)
某批矿砂的5个样品中的镍含量( % ),经测定得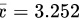 ,
,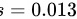 ,设测定值总体
,设测定值总体 服从
服从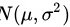 ,但
,但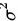 未知,问在显著性水平
未知,问在显著性水平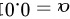 下,能否接受假设:这批矿砂的镍含量的均值为3.25? (
下,能否接受假设:这批矿砂的镍含量的均值为3.25? (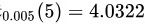 ,
,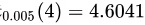 ,
, 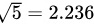 )
)
题目解答
答案
设原假设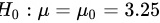
单个正态总体下的关于均值的检验,当方差未知时,应用样本标准差 代替
代替 .
.
当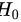 成立时,选取统计量:
成立时,选取统计量: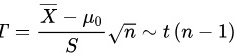 .
.
对于给定的显著水平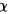 ,
,
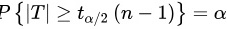
∴拒绝域是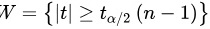 ,其中
,其中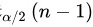 是自由度为
是自由度为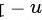 的t分布的
的t分布的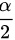 上侧分位数.
上侧分位数.
代入数据可得: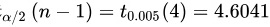
∴拒绝域是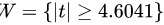 ;
;
统计量的观测值:
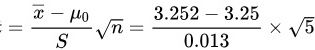
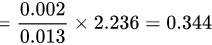 ;
;
∴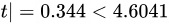 ,落在拒绝域以外,即接受域以内
,落在拒绝域以外,即接受域以内
∴接受原假设
即在显著性水平下,接受假设:这批矿砂的镍含量的均值为3.25.
解析
步骤 1:确定假设
设原假设${H}_{0}:\mu =\mu 0=3.25$,即这批矿砂的镍含量的均值为3.25%。
步骤 2:选择检验统计量
由于总体方差未知,且样本量较小,我们使用t检验。检验统计量为$T=\dfrac {\overline {X}-\mu 0}{S}\sqrt {n}\sim t(n-1)$,其中$\overline {X}$是样本均值,$S$是样本标准差,$n$是样本量。
步骤 3:计算检验统计量的值
代入数据,我们得到$T=\dfrac {3.252-3.25}{0.013}\times \sqrt {5}=\dfrac {0.002}{0.013}\times 2.236=0.344$。
步骤 4:确定拒绝域
对于给定的显著性水平$\alpha =0.01$,自由度为$n-1=4$,查t分布表得到${t}_{\alpha /2}(n-1)={t}_{0.005}(4)=4.6041$。因此,拒绝域是$N=\{ |t|\geqslant 4.6041\}$。
步骤 5:做出决策
由于$|t|=0.344\lt 4.6041$,落在拒绝域以外,即接受域以内,因此我们接受原假设${H}_{0}:\mu =\mu 0=3.25$。
设原假设${H}_{0}:\mu =\mu 0=3.25$,即这批矿砂的镍含量的均值为3.25%。
步骤 2:选择检验统计量
由于总体方差未知,且样本量较小,我们使用t检验。检验统计量为$T=\dfrac {\overline {X}-\mu 0}{S}\sqrt {n}\sim t(n-1)$,其中$\overline {X}$是样本均值,$S$是样本标准差,$n$是样本量。
步骤 3:计算检验统计量的值
代入数据,我们得到$T=\dfrac {3.252-3.25}{0.013}\times \sqrt {5}=\dfrac {0.002}{0.013}\times 2.236=0.344$。
步骤 4:确定拒绝域
对于给定的显著性水平$\alpha =0.01$,自由度为$n-1=4$,查t分布表得到${t}_{\alpha /2}(n-1)={t}_{0.005}(4)=4.6041$。因此,拒绝域是$N=\{ |t|\geqslant 4.6041\}$。
步骤 5:做出决策
由于$|t|=0.344\lt 4.6041$,落在拒绝域以外,即接受域以内,因此我们接受原假设${H}_{0}:\mu =\mu 0=3.25$。