题目
设某次考试的考生成绩服从正态分布,从中随机地抽取36位考生的成绩,算得平均成绩为66.5分,标准差为15分,问在显著性水平0.05下,是否可认为这次考试全体考生的平均成绩为70分?并给出检验过程。.05(36)=1.6883,-|||-_(0.025)(36)=2.0281.05(35)=1.6896,-|||-_(0.025)(35)=2.0301; .05(36)=1.6883,-|||-_(0.025)(36)=2.0281.05(35)=1.6896,-|||-_(0.025)(35)=2.0301
设某次考试的考生成绩服从正态分布,从中随机地抽取36位考生的成绩,算得平均成绩为66.5分,标准差为15分,问在显著性水平0.05下,是否可认为这次考试全体考生的平均成绩为70分?并给出检验过程。
 ;
; 
题目解答
答案
解:已知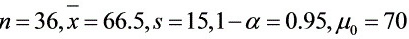
假设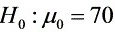 ;
;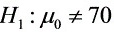 统计量:
统计量: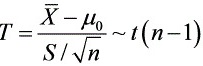
所以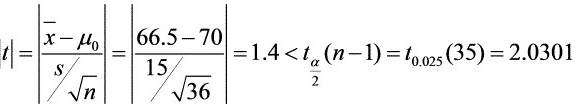 ,
,
所以接受假设,即认为在显著性水平下全体考生平均成绩为70分。
解析
考查要点:本题主要考查单样本t检验的应用,涉及假设检验的基本步骤、检验统计量的计算及临界值法的决策过程。
解题核心思路:
- 确定检验类型:由于总体方差未知且样本容量较小(n=36),选择t检验。
- 构建假设:原假设$H_0: \mu = 70$,备择假设$H_1: \mu \neq 70$(双侧检验)。
- 计算检验统计量:利用公式$T = \dfrac{\overline{X} - \mu_0}{S/\sqrt{n}}$,代入数据求值。
- 确定临界值:根据显著性水平$\alpha=0.05$和自由度$n-1=35$,查表得临界值$t_{0.025}(35)=2.0301$。
- 比较与决策:若统计量绝对值小于临界值,则接受原假设。
破题关键:
- 正确选择检验方法(t检验而非z检验)。
- 准确计算自由度(n-1=35)。
- 区分单双侧检验(本题为双侧,需注意临界值的双尾分布)。
建立假设
- 原假设:$H_0: \mu = 70$(全体考生平均成绩为70分)。
- 备择假设:$H_1: \mu \neq 70$(全体考生平均成绩不等于70分)。
计算检验统计量
$T = \dfrac{\overline{X} - \mu_0}{S/\sqrt{n}} = \dfrac{66.5 - 70}{15/\sqrt{36}} = \dfrac{-3.5}{2.5} = -1.4$
确定临界值
- 显著性水平$\alpha=0.05$,双侧检验对应分位数为$t_{0.025}(35)=2.0301$。
- 临界值范围为$[-2.0301, 2.0301]$。
比较与决策
- 统计量绝对值$|T|=1.4 < 2.0301$,落在接受域内。
- 结论:无法拒绝原假设,认为全体考生平均成绩为70分。