题目
设_(1),(X)_(2),... ,(X)_(8)和 _(1),(X)_(2),... ,(X)_(8) 分别是来自独立总体 X 和 Y 的简单随机样本其中_(1),(X)_(2),... ,(X)_(8)则_(1),(X)_(2),... ,(X)_(8)
设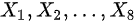 和
和 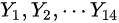 分别是来自独立总体 X 和 Y 的简单随机样本其中
分别是来自独立总体 X 和 Y 的简单随机样本其中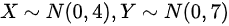 则
则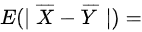
题目解答
答案
由题意得
和
分别是来自独立总体 X 和 Y 的简单随机样本其中
可以得到
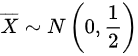
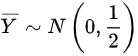
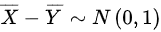
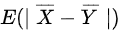
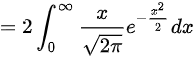
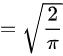
解析
考查要点:本题主要考查样本均值的分布、独立正态变量的线性组合以及标准正态分布绝对值的期望的计算。
解题核心思路:
- 确定样本均值的分布:根据正态总体的性质,样本均值$\overline{X}$和$\overline{Y}$分别服从正态分布,计算其均值和方差。
- 求差的分布:利用独立正态变量的性质,确定$\overline{X} - \overline{Y}$的分布。
- 计算绝对值期望:将问题转化为标准正态分布下$E(|Z|)$的计算,利用积分公式或已知结果求解。
破题关键点:
- 样本均值的方差计算:注意样本容量对总体方差的影响。
- 独立变量差的方差叠加:独立变量的方差可直接相加。
- 标准正态分布绝对值的期望公式:直接应用已知结果$E(|Z|) = \sqrt{\dfrac{2}{\pi}}$。
步骤1:确定样本均值的分布
- $X \sim N(0,4)$,样本容量$n=8$,则$\overline{X} \sim N\left(0, \dfrac{4}{8}\right) = N\left(0, \dfrac{1}{2}\right)$。
- $Y \sim N(0,7)$,样本容量$m=14$,则$\overline{Y} \sim N\left(0, \dfrac{7}{14}\right) = N\left(0, \dfrac{1}{2}\right)$。
步骤2:求$\overline{X} - \overline{Y}$的分布
- $\overline{X}$与$\overline{Y}$独立,故$\overline{X} - \overline{Y} \sim N\left(0 - 0, \dfrac{1}{2} + \dfrac{1}{2}\right) = N(0,1)$。
步骤3:计算$E(|\overline{X} - \overline{Y}|)$
- 设$Z = \overline{X} - \overline{Y} \sim N(0,1)$,则$E(|Z|) = \dfrac{2}{\sqrt{2\pi}} \int_{0}^{\infty} x e^{-x^2/2} dx = \sqrt{\dfrac{2}{\pi}}$。