题目
如果研究对象分组数为2,同一组资料进行两样本均数比较时,用方差分析和检验关系是( ) A. B. C. D. E. F" data-width="51" data-height="20" data-size="789" data-format="png" style="max-width:100%">
如果研究对象分组数为2,同一组资料进行两样本均数比较时,用方差分析和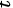 检验关系是( )
检验关系是( )
A. 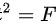
B. 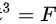
C.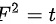
D. 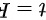
E. 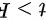 F" data-width="51" data-height="20" data-size="789" data-format="png" style="max-width:100%">
F" data-width="51" data-height="20" data-size="789" data-format="png" style="max-width:100%">
题目解答
答案
解:
(1)分布定义
设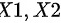 独立,
独立,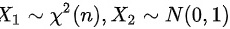 则:
则: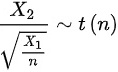 (2)
(2)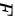 分布定义
分布定义
设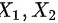 独立,
独立,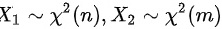 ,则定义
,则定义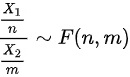
(3)联系
对分布而言,当其分子的卡方分布的自由度为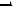 时,则有
时,则有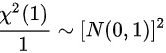 综上,可得:
综上,可得: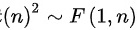
即,故本题选A.
解析
步骤 1:理解方差分析和t检验的关系
方差分析(ANOVA)和t检验都是用于比较均值的统计方法。当研究对象分组数为2时,方差分析和t检验在统计上是等价的。具体来说,当进行两样本均数比较时,方差分析的F统计量和t检验的t统计量之间存在一定的关系。
步骤 2:方差分析的F统计量
方差分析的F统计量是通过比较组间方差和组内方差来计算的。当分组数为2时,F统计量可以表示为:$F = \frac{MS_{between}}{MS_{within}}$,其中$MS_{between}$是组间均方,$MS_{within}$是组内均方。
步骤 3:t检验的t统计量
t检验的t统计量是通过比较两组样本均数的差异来计算的。t统计量可以表示为:$t = \frac{\bar{X}_1 - \bar{X}_2}{\sqrt{\frac{s^2}{n_1} + \frac{s^2}{n_2}}}$,其中$\bar{X}_1$和$\bar{X}_2$是两组样本的均数,$s^2$是合并方差,$n_1$和$n_2$是两组样本的样本量。
步骤 4:F统计量和t统计量的关系
当分组数为2时,方差分析的F统计量和t检验的t统计量之间存在以下关系:$F = t^2$。这是因为当分组数为2时,组间方差和组内方差的比值可以表示为t统计量的平方。
方差分析(ANOVA)和t检验都是用于比较均值的统计方法。当研究对象分组数为2时,方差分析和t检验在统计上是等价的。具体来说,当进行两样本均数比较时,方差分析的F统计量和t检验的t统计量之间存在一定的关系。
步骤 2:方差分析的F统计量
方差分析的F统计量是通过比较组间方差和组内方差来计算的。当分组数为2时,F统计量可以表示为:$F = \frac{MS_{between}}{MS_{within}}$,其中$MS_{between}$是组间均方,$MS_{within}$是组内均方。
步骤 3:t检验的t统计量
t检验的t统计量是通过比较两组样本均数的差异来计算的。t统计量可以表示为:$t = \frac{\bar{X}_1 - \bar{X}_2}{\sqrt{\frac{s^2}{n_1} + \frac{s^2}{n_2}}}$,其中$\bar{X}_1$和$\bar{X}_2$是两组样本的均数,$s^2$是合并方差,$n_1$和$n_2$是两组样本的样本量。
步骤 4:F统计量和t统计量的关系
当分组数为2时,方差分析的F统计量和t检验的t统计量之间存在以下关系:$F = t^2$。这是因为当分组数为2时,组间方差和组内方差的比值可以表示为t统计量的平方。