一、单项选择题(1) 一个算法应该是( )。A. 程序 B. 问题求步骤的描述 C. 要满足五个基本属性 D. A和C E. (2) 算法指的是( )。 F. 计算机程序 G. 决问题的计算方法[1]排序算法决问题的有限运算序列。(3) 与数据元素本身的形式、内容、相对位置、个数无关的是数据的( )。存储结构逻辑结构算法操作(4) 从逻辑上可以把数据结构分为( )两大类。动态结构、静态结构顺序结构、链式结构线性结构[2]、非线性结构[3]初等结构、构造型结构(5) 下列叙述中正确的是( )。一个逻辑数据结构只能有一种存储结构数据的逻辑结构属于线性结构,存储结构属于非线性结构一个逻辑数据结构可以有多种存储结构,且各种存储结构不影响数据处理[4]的效率一个逻辑数据结构可以有多种存储结构,且各种存储结构影响数据处理的效率(6) 数据的基本单位是( )数据项[5]数据类型[6]数据元素数据变量(7) 下列程序的时间复杂度为( )i=0;s=0;hile(s<n)( i++;s=s+i;)O()O()O(n)O(n2)(8) 下列程序段的渐进时间复杂度为( )。or( int i=1;i<=n;i++)or( int j=1;j<= m; j++)[i][j] = i*j ;O(m2)O(n2)O(m*n)(m+n)(9) 程序段如下:sum=0;or(i=1;i<=n;i++)or(j=1;j<=n;j++)sum++;=(V,E),其中:V=(a,b,c,d,e,f), E=((a,b),(a,e),(a,c),(b,e),(c,f), (f,d),(e,d)),对该进行深度优先遍历,得到的顶点序列正确的是( )。a,b,e,c,d,fa,c,f,e,b,da,e,b,c,f,da,e,d,f,c,b(77) 下面哪一方法可以判断出一个有向是否有环(回路)。求节点的度拓扑排序求最短路径求关键路径(78) 的广度优先搜索类似于树的( )次序遍历。先根中根后根层次Prim 算法的时间复杂度为( )。O(n)O(n+e)O(n2)O(n3)=(V,E),其中V=(V1,V2,V3,V4,V5,V6,V7),E=(<V1,V2>,<V1,V3>,<V1,V4>, <V2,V5>,<V3,V5>,<V3,V6>,<V4,V6>,<V5,V7>,<V6,V7>),G的拓扑序列是( )。V1,V3,V4,V6,V2,V5,V7V1,V3,V2,V6,V4,V5,V7V1,V3,V4,V5,V2,V6,V7V1,V2,V5,V3,V4,V6,V7(81) 关键路径是事件结点网络中( )。从源点到汇点的最长路径从源点到汇点的最短路径最长回路最短回路(82) 有n个结点的有向完全的弧数是( )。n22nn(n-1)2n(n+1)(83) 设的邻接链表如题12所示,则该的边的数目是( )。451020(84) 在一个中,所有顶点的度数之和等于的边数的( )倍。1/2124(85) 在一个有向中,所有顶点的入度之和等于所有顶点的出度之和的( )倍。1/2124(86) 有8个结点的无向最多有( )条边。142856112(87) 有8个结点的无向连通最少有( )条边。5678(88) 有8个结点的有向完全有( )条边。142856112(89) 用邻接表表示进行广度优先遍历时,通常是采用( )来实现算法的。栈队列树(90) 用邻接表表示进行深度优先遍历时,通常是采用( )来实现算法的。栈队列树(91) 已知的邻接矩阵,根据算法思想,则从顶点0出发按深度优先遍历的结点序列是( )。0 2 4 3 1 5 60 1 3 6 5 4 20 4 2 3 1 6 50 3 6 1 5 4 2建议:0 1 3 4 2 5 6(92) 已知的邻接矩阵同上题8,根据算法,则从顶点0出发,按深度优先遍历的结点序列是( )。0 2 4 3 1 5 60 1 3 5 6 4 20 4 2 3 1 6 50 1 3 4 2 5 6(93) 已知的邻接矩阵同上题8,根据算法,则从顶点0出发,按广度优先遍历的结点序列是( )。0 2 4 3 6 5 10 1 3 6 4 2 50 4 2 3 1 5 60 1 3 4 2 5 6(建议:0 1 2 3 4 5 6)(94) 已知的邻接矩阵同上题8,根据算法,则从顶点0出发,按广度优先遍历的结点序列是( )。0 2 4 3 1 6 50 1 3 5 6 4 20 1 2 3 4 6 50 1 2 3 4 5 6(95) 已知的邻接表如下所示,根据算法,则从顶点0出发按深度优先遍历的结点序列是( )。1 3 20 2 3 10 3 2 10 1 2 3(96) 已知的邻接表如下所示,根据算法,则从顶点0出发按广度优先遍历的结点序列是( )。0 3 2 10 1 2 30 1 3 20 3 1 2(97) 深度优先遍历类似于二叉树的( )。先序遍历中序遍历后序遍历层次遍历(98) 广度优先遍历类似于二叉树的( )。先序遍历中序遍历后序遍历层次遍历(99) 任何一个无向连通的最小生成树( )。只有一棵一棵或多棵一定有多棵可能不存在(注,生成树不唯一,但最小生成树唯一,即边权之和或树权最小的情况唯一)Li,那么查找失败到达失败点时所做的数据比较次数是( )。Li+1Li+2Li-1Li(101) 向一个有127个元素原顺序表中插入一个新元素并保存原来顺序不变,平均要移动( )个元素。863.5637(102) 由同一组关键字集合构造的各棵二叉排序树( )。其形态不一定相同,但平均查找长度相同其形态不一定相同,平均查找长度也不一定相同其形态均相同,但平均查找长度不一定相同其形态均相同,平均查找长度也都相同(103) 衡量查找算法效率的主要标准是( )。元素的个数所需的存储量平均查找长度算法难易程度(104) 适合对动态查找表进行高效率查找的组织结构是( )。有序表分块有序表二叉排序树快速排序(3) 能进行二分查找的线性表,必须以( )。顺序方式存储,且元素按关键字有序链式方式存储,且元素按关键字有序顺序方式存储,且元素按关键字分块有序链式方式存储,且元素按关键字分块有序(105) 为使平均查找长度达到最小,当由关键字集合(05,11,21,25,37,40,41,62,84)构建二叉排序树时,第一个插入的关键字应为( )5374162(106) 对关键字序列(56,23,78,92,88,67,19,34)进行增量为3的一趟希尔排序的结果为 ( )。(19,23,56,34,78,67,88,92)23,56,78,66,88,92,19,34)(19,23,34,56,67,78,88,92)(19,23,67,56,34,78,92,88)(107) 用某种排序方法对关键字序列(35,84,21,47,15,27,68,25,20)进行排序时,序列的变化情况如下:20,15,21,25,47,27,68,35,8415,20,21,25,35,27,47,68,8415,20,21,25,27,35,47,68,84则采用的方法是( )。直接选择排序希尔排序堆排序快速排序(108) 一组记录的排序码为(46,79,56,38,40,84),则利用快速排序的方法,以第一个记录为基准得到的第一次划分结果为( )。38,40,46,56,79,8440,38,46,79,56,8440,38,46,56,79,8440,38,46,84,56,79(109) 快速排序在最坏情况下的时间复杂度是( )O(n2log2n)O(n2)O(nlog2n)O(log2n)(110) 下列排序算法中不稳定的是( )。直接选择排序折半插入排序冒泡排序快速排序(111) 对待排序的元素序列进行划分,将其分为左、右两个子序列,再对两个子序列进行同样的排序操作,直到子序列为空或只剩下一个元素为止。这样的排序方法是( )。直接选择排序直接插入排序快速排序冒泡排序(112) 将5个不同的数据进行排序,至多需要比较( )次。891025(113) 排序算法中,第一趟排序后,任一元素都不能确定其最终位置的算法是( )。选择排序快速排序冒泡排序插入排序(114) 排序算法中,不稳定的排序是( )。直接插入排序冒泡排序堆排序选择排序(115) 排序方法中,从未排序序列中依次取出元素与已排序序列(初始时为空)中的元素进行比较,将其放入已排序序列的正确位置上的方法,称为( ).希尔排序冒泡排序插入排序选择排序(116) 从未排序序列中挑选元素,并将其依次插入已排序序列(初始时为空)的一端的方法,称为( )。希尔排序归并排序插入排序选择排序(117) 对n个不同的排序码进行冒泡排序,在下列哪种情况下比较的次数最多。( )从小到大排列好的从大到小排列好的元素无序元素基本有序(118) 对n个不同的排序码进行冒泡排序,在元素无序的情况下比较的次数为( )。n+1nn-1n(n-1)/2(119) 快速排序在下列哪种情况下最易发挥其长处。( )被排序的数据中含有多个相同排序码被排序的数据已基本有序被排序的数据完全无序被排序的数据中的最大值和最小值相差悬殊(120) 对有n个记录的表作快速排序,在最坏情况下,算法的时间复杂度是( )。O(n)O(n2)O(nlog2n)O(n3)(121) 若一组记录的排序码为(46, 79, 56, 38, 40, 84),则利用快速排序的方法,以第一个记录为基准得到的一次划分结果为( )。38, 40, 46, 56, 79, 8440, 38, 46 , 79, 56, 8440, 38,46, 56, 79, 8440, 38, 46, 84, 56, 79(122) 下列关键字序列中,( )是堆。16, 72, 31, 23, 94, 5394, 23, 31, 72, 16, 5316, 53, 23, 94,31, 7216, 23, 53, 31, 94, 72(123) 堆是一种( )排序。插入选择交换归并(124) 堆的形状是一棵( )。二叉排序树满二叉树完全二叉树平衡二叉树(125) 若一组记录的排序码为(46, 79, 56, 38, 40, 84),则利用堆排序的方法建立的初始堆为( )。79, 46, 56, 38, 40, 8484, 79, 56, 38, 40, 4684, 79, 56, 46, 40, 3884, 56, 79, 40, 46, 38(126) 下述几种排序方法中,要求内存最大的是( )。插入排序快速排序归并排序选择排序(127) 有一组数据(15,9,7,8,20,-1,7,4),用堆排序的筛选方法建立的初始堆为( )。-1,4,8,9,20,7,15,7-1,7,15,7,4,8,20,9A,B,C 均不对。(128) 51.下列四个序列中,哪一个是堆( )。75,65,30,15,25,45,20,1075,65,45,10,30,25,20,1575,45,65,30,15,25,20,1075,45,65,10,25,30,20,15(129) 以下序列不是堆的是( )。(100,85,98,77,80,60,82,40,20,10,66)(100,98,85,82,80,77,66,60,40,20,10)(10,20,40,60,66,77,80,82,85,98,100)(100,85,40,77,80,60,66,98,82,10,20)(130) 快速排序方法在( )情况下最不利于发挥其长处。要排序的数据量太大要排序的数据中含有多个相同值要排序的数据个数为奇数要排序的数据已基本有序(131) 对关键码序列28,16,32,12,60,2,5,72 快速排序,从小到大一次划分结果为( )。(2,5,12,16)26(60,32,72)(5,16,2,12)28(60,32,72)(2,16,12,5)28(60,32,72)(5,16,2,12)28(32,60,72)(132) 对下列关键字序列用快速排序法进行排序时,速度最快的情形是( )。(21,25,5,17,9,23,30)(25,23,30,17,21,5,9)(21,9,17,30,25,23,5)(5,9,17,21,23,25,30)
一、单项选择题
(1) 一个算法应该是( )。
A. 程序B. 问题求步骤的描述
C. 要满足五个基本属性
D. A和C
E. (2) 算法指的是( )。
F. 计算机程序
G. 决问题的计算方法[1]
排序算法
决问题的有限运算序列。
(3) 与数据元素本身的形式、内容、相对位置、个数无关的是数据的( )。
存储结构
逻辑结构
算法
操作
(4) 从逻辑上可以把数据结构分为( )两大类。
动态结构、静态结构
顺序结构、链式结构
线性结构[2]、非线性结构[3]
初等结构、构造型结构
(5) 下列叙述中正确的是( )。
一个逻辑数据结构只能有一种存储结构
数据的逻辑结构属于线性结构,存储结构属于非线性结构
一个逻辑数据结构可以有多种存储结构,且各种存储结构不影响数据处理[4]的效率
一个逻辑数据结构可以有多种存储结构,且各种存储结构影响数据处理的效率
(6) 数据的基本单位是( )
数据项[5]
数据类型[6]
数据元素
数据变量
(7) 下列程序的时间复杂度为( )
i=0;s=0;
hile(s<n)
{ i++;s=s+i;}
O(
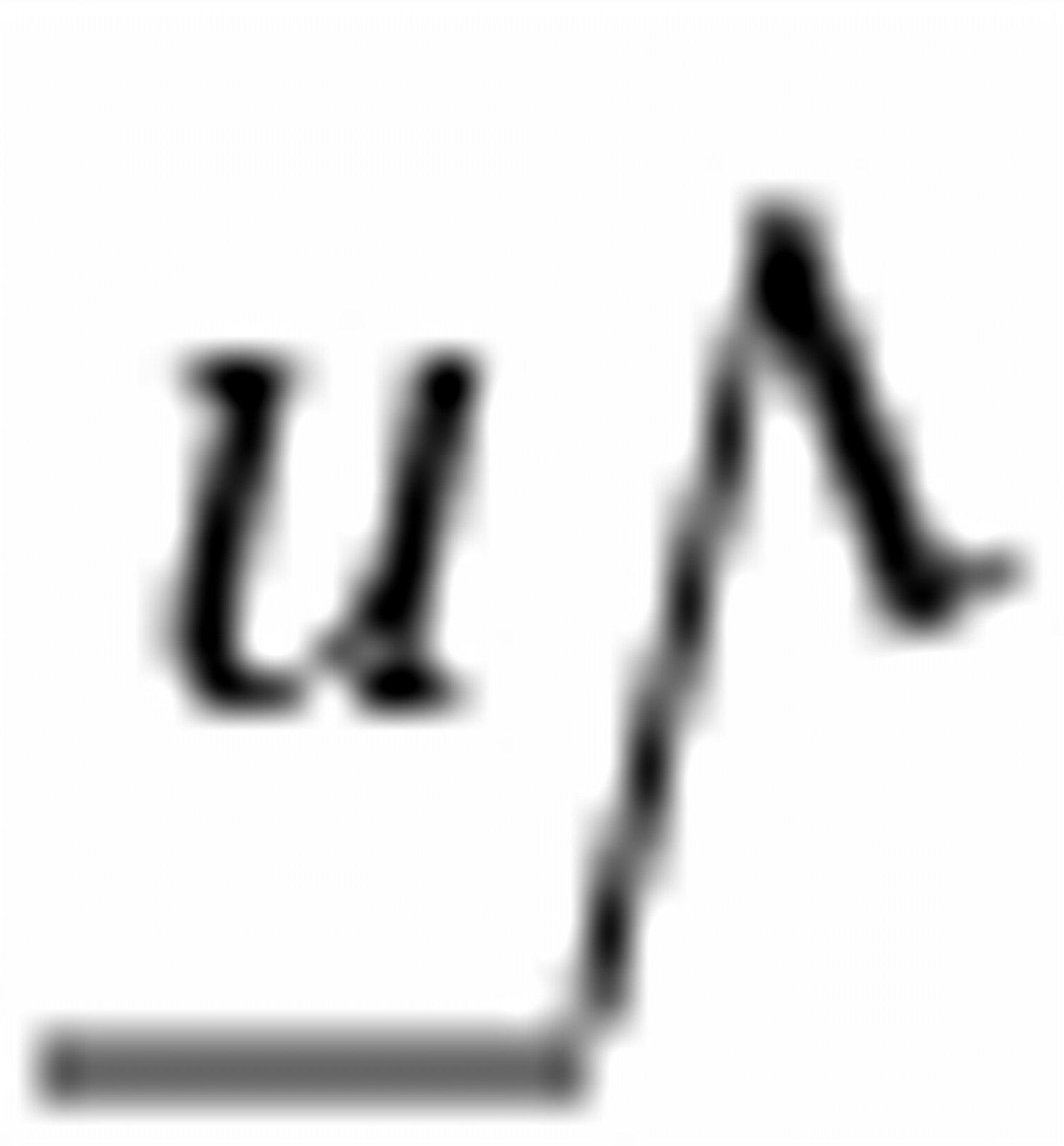 )
)O(
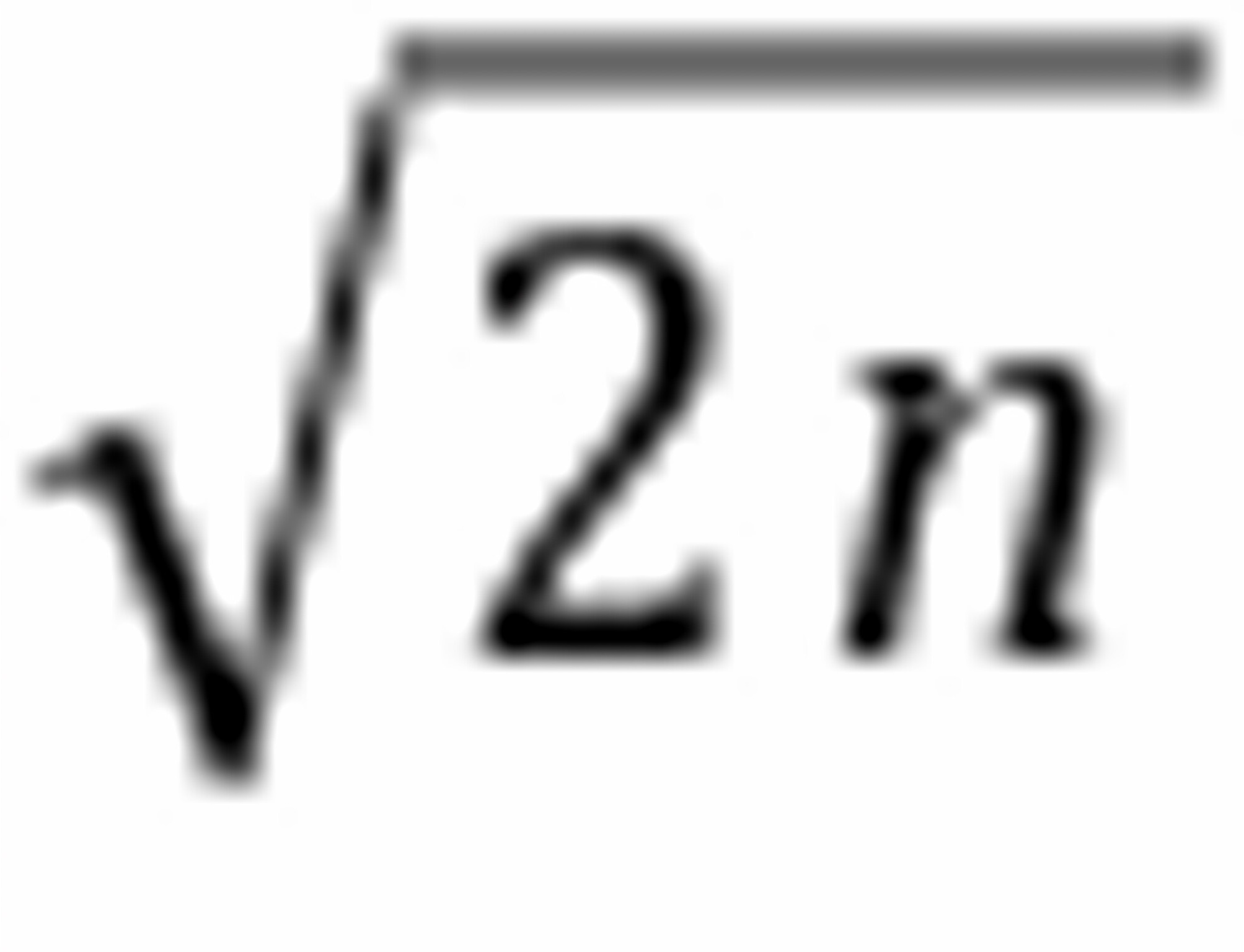 )
)O(n)
O(n2)
(8) 下列程序段的渐进时间复杂度为( )。
or( int i=1;i<=n;i++)
or( int j=1;j<= m; j++)
[i][j] = i*j ;
O(m2)
O(n2)
O(m*n)
(m+n)
(9) 程序段如下:
sum=0;
or(i=1;i<=n;i++)
or(j=1;j<=n;j++)
sum++;
=(V,E),其中:V={a,b,c,d,e,f}, E={(a,b),(a,e),(a,c),(b,e),(c,f), (f,d),(e,d)},对该进行深度优先遍历,得到的顶点序列正确的是( )。
a,b,e,c,d,f
a,c,f,e,b,d
a,e,b,c,f,d
a,e,d,f,c,b
(77) 下面哪一方法可以判断出一个有向是否有环(回路)。
求节点的度
拓扑排序
求最短路径
求关键路径
(78) 的广度优先搜索类似于树的( )次序遍历。
先根
中根
后根
层次
Prim 算法的时间复杂度为( )。
O(n)
O(n+e)
O(n2)
O(n3)
=(V,E),其中V={V1,V2,V3,V4,V5,V6,V7},E={<V1,V2>,<V1,V3>,<V1,V4>, <V2,V5>,<V3,V5>,<V3,V6>,<V4,V6>,<V5,V7>,<V6,V7>},G的拓扑序列是( )。
V1,V3,V4,V6,V2,V5,V7
V1,V3,V2,V6,V4,V5,V7
V1,V3,V4,V5,V2,V6,V7
V1,V2,V5,V3,V4,V6,V7
(81) 关键路径是事件结点网络中( )。
从源点到汇点的最长路径
从源点到汇点的最短路径
最长回路
最短回路
(82) 有n个结点的有向完全的弧数是( )。
n2
2n
n(n-1)
2n(n+1)
(83) 设的邻接链表如题12所示,则该的边的数目是( )。
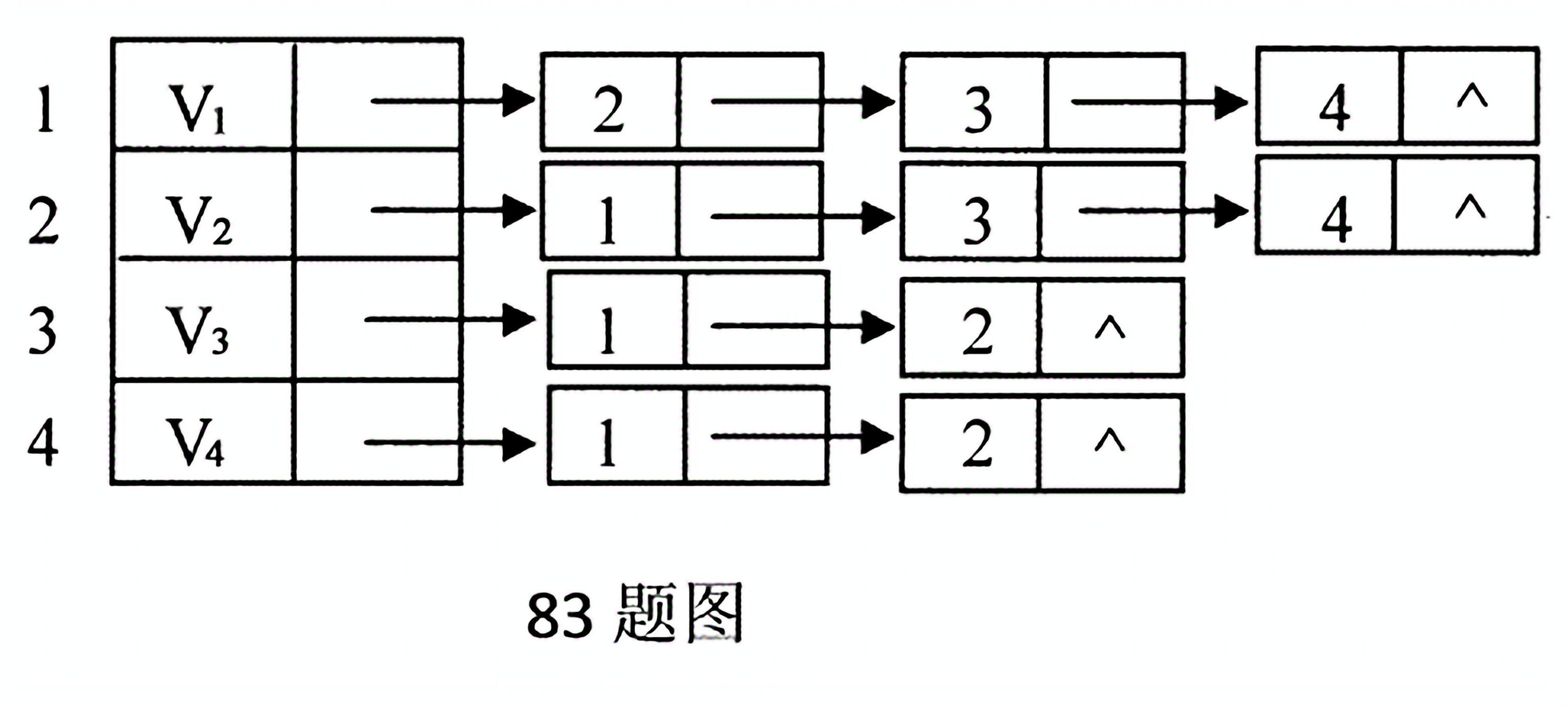
4
5
10
20
(84) 在一个中,所有顶点的度数之和等于的边数的( )倍。
1/2
1
2
4
(85) 在一个有向中,所有顶点的入度之和等于所有顶点的出度之和的( )倍。
1/2
1
2
4
(86) 有8个结点的无向最多有( )条边。
14
28
56
112
(87) 有8个结点的无向连通最少有( )条边。
5
6
7
8
(88) 有8个结点的有向完全有( )条边。
14
28
56
112
(89) 用邻接表表示进行广度优先遍历时,通常是采用( )来实现算法的。
栈
队列
树
(90) 用邻接表表示进行深度优先遍历时,通常是采用( )来实现算法的。
栈
队列
树
(91) 已知的邻接矩阵,根据算法思想,则从顶点0出发按深度优先遍历的结点序列是( )。

0 2 4 3 1 5 6
0 1 3 6 5 4 2
0 4 2 3 1 6 5
0 3 6 1 5 4 2
建议:0 1 3 4 2 5 6
(92) 已知的邻接矩阵同上题8,根据算法,则从顶点0出发,按深度优先遍历的结点序列是( )。
0 2 4 3 1 5 6
0 1 3 5 6 4 2
0 4 2 3 1 6 5
0 1 3 4 2 5 6
(93) 已知的邻接矩阵同上题8,根据算法,则从顶点0出发,按广度优先遍历的结点序列是( )。
0 2 4 3 6 5 1
0 1 3 6 4 2 5
0 4 2 3 1 5 6
0 1 3 4 2 5 6
(建议:0 1 2 3 4 5 6)
(94) 已知的邻接矩阵同上题8,根据算法,则从顶点0出发,按广度优先遍历的结点序列是( )。
0 2 4 3 1 6 5
0 1 3 5 6 4 2
0 1 2 3 4 6 5
0 1 2 3 4 5 6
(95) 已知的邻接表如下所示,根据算法,
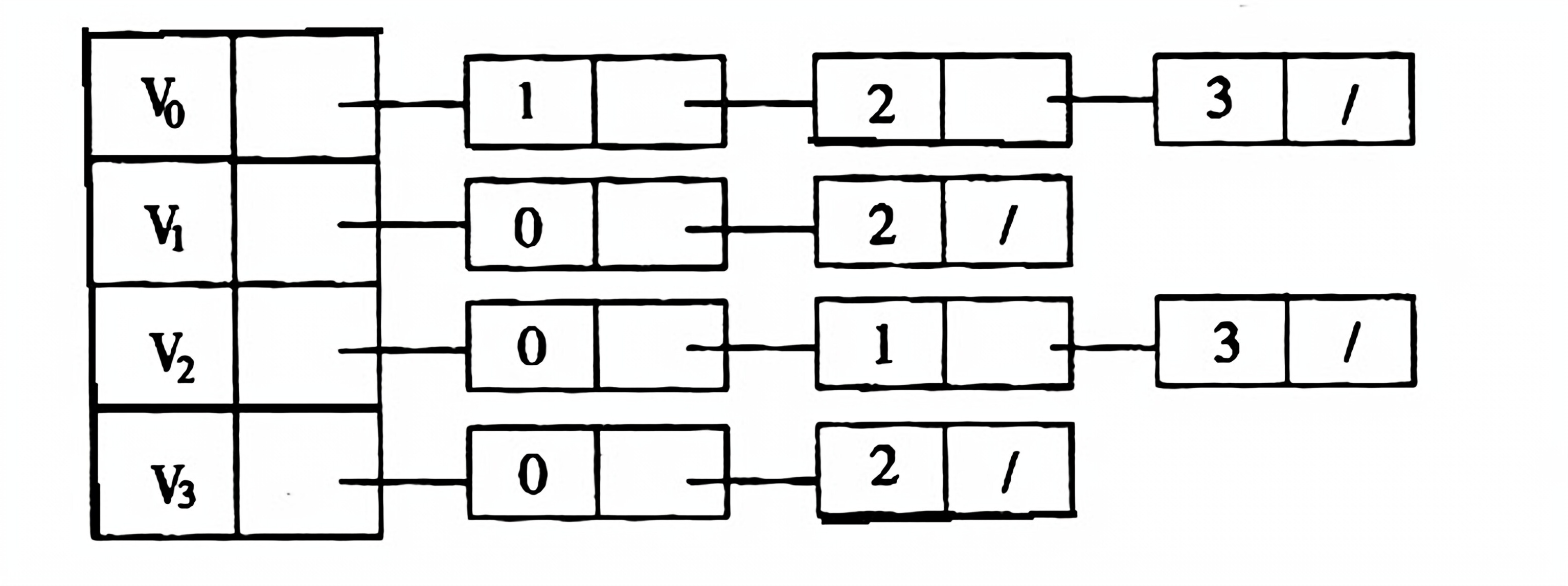 则从顶点0出发按深度优先遍历的结点序列是( )。
则从顶点0出发按深度优先遍历的结点序列是( )。1 3 2
0 2 3 1
0 3 2 1
0 1 2 3
(96) 已知的邻接表如下所示,根据算法,则从顶点0出发按广度优先遍历的结点序列是( )。
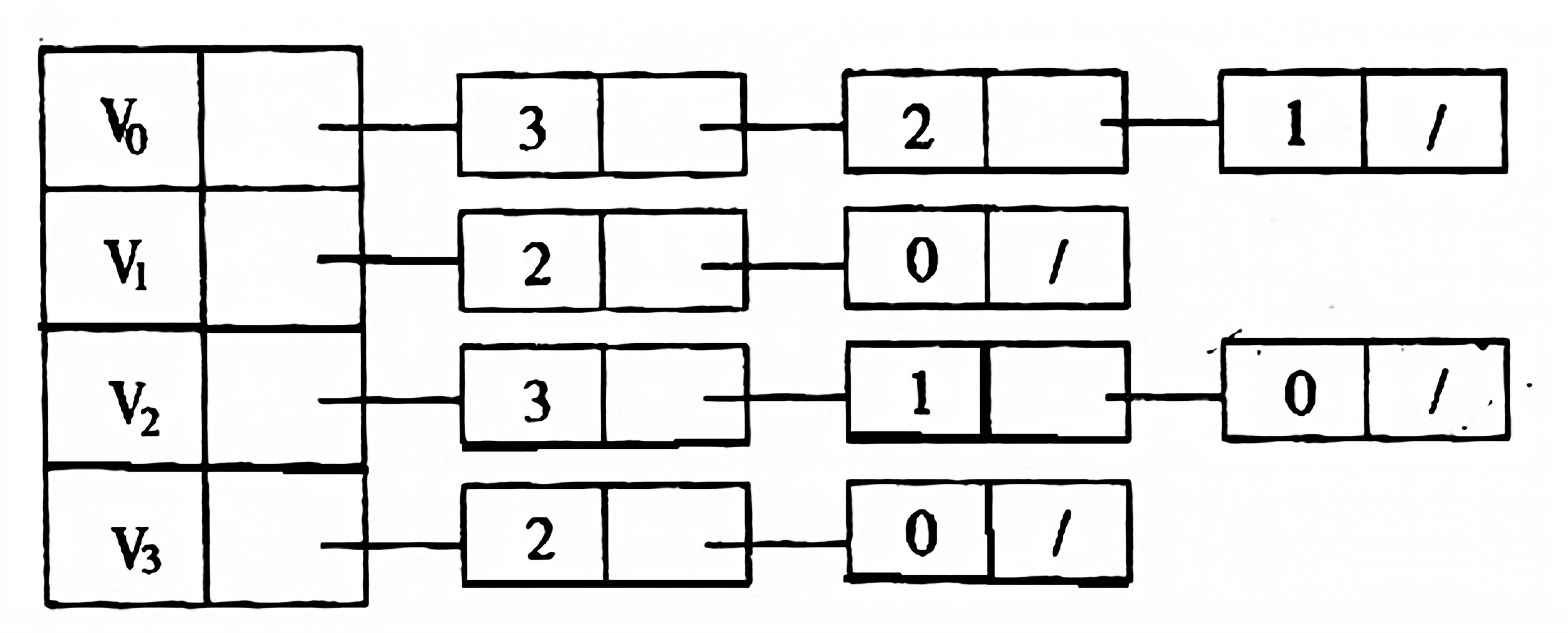
0 3 2 1
0 1 2 3
0 1 3 2
0 3 1 2
(97) 深度优先遍历类似于二叉树的( )。
先序遍历
中序遍历
后序遍历
层次遍历
(98) 广度优先遍历类似于二叉树的( )。
先序遍历
中序遍历
后序遍历
层次遍历
(99) 任何一个无向连通的最小生成树( )。
只有一棵
一棵或多棵
一定有多棵
可能不存在
(注,生成树不唯一,但最小生成树唯一,即边权之和或树权最小的情况唯一)
Li,那么查找失败到达失败点时所做的数据比较次数是( )。
Li+1
Li+2
Li-1
Li
(101) 向一个有127个元素原顺序表中插入一个新元素并保存原来顺序不变,平均要移动( )个元素。
8
63.5
63
7
(102) 由同一组关键字集合构造的各棵二叉排序树( )。
其形态不一定相同,但平均查找长度相同
其形态不一定相同,平均查找长度也不一定相同
其形态均相同,但平均查找长度不一定相同
其形态均相同,平均查找长度也都相同
(103) 衡量查找算法效率的主要标准是( )。
元素的个数
所需的存储量
平均查找长度
算法难易程度
(104) 适合对动态查找表进行高效率查找的组织结构是( )。
有序表
分块有序表
二叉排序树
快速排序
(3) 能进行二分查找的线性表,必须以( )。
顺序方式存储,且元素按关键字有序
链式方式存储,且元素按关键字有序
顺序方式存储,且元素按关键字分块有序
链式方式存储,且元素按关键字分块有序
(105) 为使平均查找长度达到最小,当由关键字集合{05,11,21,25,37,40,41,62,84}构建二叉排序树时,第一个插入的关键字应为( )
5
37
41
62
(106) 对关键字序列(56,23,78,92,88,67,19,34)进行增量为3的一趟希尔排序的结果为 ( )。
(19,23,56,34,78,67,88,92)
23,56,78,66,88,92,19,34)
(19,23,34,56,67,78,88,92)
(19,23,67,56,34,78,92,88)
(107) 用某种排序方法对关键字序列{35,84,21,47,15,27,68,25,20}进行排序时,序列的变化情况如下:
20,15,21,25,47,27,68,35,84
15,20,21,25,35,27,47,68,84
15,20,21,25,27,35,47,68,84
则采用的方法是( )。
直接选择排序
希尔排序
堆排序
快速排序
(108) 一组记录的排序码为(46,79,56,38,40,84),则利用快速排序的方法,以第一个记录为基准得到的第一次划分结果为( )。
38,40,46,56,79,84
40,38,46,79,56,84
40,38,46,56,79,84
40,38,46,84,56,79
(109) 快速排序在最坏情况下的时间复杂度是( )
O(n2log2n)
O(n2)
O(nlog2n)
O(log2n)
(110) 下列排序算法中不稳定的是( )。
直接选择排序
折半插入排序
冒泡排序
快速排序
(111) 对待排序的元素序列进行划分,将其分为左、右两个子序列,再对两个子序列进行同样的排序操作,直到子序列为空或只剩下一个元素为止。这样的排序方法是( )。
直接选择排序
直接插入排序
快速排序
冒泡排序
(112) 将5个不同的数据进行排序,至多需要比较( )次。
8
9
10
25
(113) 排序算法中,第一趟排序后,任一元素都不能确定其最终位置的算法是( )。
选择排序
快速排序
冒泡排序
插入排序
(114) 排序算法中,不稳定的排序是( )。
直接插入排序
冒泡排序
堆排序
选择排序
(115) 排序方法中,从未排序序列中依次取出元素与已排序序列(初始时为空)中的元素进行比较,将其放入已排序序列的正确位置上的方法,称为( ).
希尔排序
冒泡排序
插入排序
选择排序
(116) 从未排序序列中挑选元素,并将其依次插入已排序序列(初始时为空)的一端的方法,称为( )。
希尔排序
归并排序
插入排序
选择排序
(117) 对n个不同的排序码进行冒泡排序,在下列哪种情况下比较的次数最多。( )
从小到大排列好的
从大到小排列好的
元素无序
元素基本有序
(118) 对n个不同的排序码进行冒泡排序,在元素无序的情况下比较的次数为( )。
n+1
n
n-1
n(n-1)/2
(119) 快速排序在下列哪种情况下最易发挥其长处。( )
被排序的数据中含有多个相同排序码
被排序的数据已基本有序
被排序的数据完全无序
被排序的数据中的最大值和最小值相差悬殊
(120) 对有n个记录的表作快速排序,在最坏情况下,算法的时间复杂度是( )。
O(n)
O(n2)
O(nlog2n)
O(n3)
(121) 若一组记录的排序码为(46, 79, 56, 38, 40, 84),则利用快速排序的方法,以第一个记录为基准得到的一次划分结果为( )。
38, 40, 46, 56, 79, 84
40, 38, 46 , 79, 56, 84
40, 38,46, 56, 79, 84
40, 38, 46, 84, 56, 79
(122) 下列关键字序列中,( )是堆。
16, 72, 31, 23, 94, 53
94, 23, 31, 72, 16, 53
16, 53, 23, 94,31, 72
16, 23, 53, 31, 94, 72
(123) 堆是一种( )排序。
插入
选择
交换
归并
(124) 堆的形状是一棵( )。
二叉排序树
满二叉树
完全二叉树
平衡二叉树
(125) 若一组记录的排序码为(46, 79, 56, 38, 40, 84),则利用堆排序的方法建立的初始堆为( )。
79, 46, 56, 38, 40, 84
84, 79, 56, 38, 40, 46
84, 79, 56, 46, 40, 38
84, 56, 79, 40, 46, 38
(126) 下述几种排序方法中,要求内存最大的是( )。
插入排序
快速排序
归并排序
选择排序
(127) 有一组数据(15,9,7,8,20,-1,7,4),用堆排序的筛选方法建立的初始堆为( )。
-1,4,8,9,20,7,15,7
-1,7,15,7,4,8,20,9
A,B,C 均不对。
(128) 51.下列四个序列中,哪一个是堆( )。
75,65,30,15,25,45,20,10
75,65,45,10,30,25,20,15
75,45,65,30,15,25,20,10
75,45,65,10,25,30,20,15
(129) 以下序列不是堆的是( )。
(100,85,98,77,80,60,82,40,20,10,66)
(100,98,85,82,80,77,66,60,40,20,10)
(10,20,40,60,66,77,80,82,85,98,100)
(100,85,40,77,80,60,66,98,82,10,20)
(130) 快速排序方法在( )情况下最不利于发挥其长处。
要排序的数据量太大
要排序的数据中含有多个相同值
要排序的数据个数为奇数
要排序的数据已基本有序
(131) 对关键码序列28,16,32,12,60,2,5,72 快速排序,从小到大一次划分结果为( )。
(2,5,12,16)26(60,32,72)
(5,16,2,12)28(60,32,72)
(2,16,12,5)28(60,32,72)
(5,16,2,12)28(32,60,72)
(132) 对下列关键字序列用快速排序法进行排序时,速度最快的情形是( )。
{21,25,5,17,9,23,30}
{25,23,30,17,21,5,9}
{21,9,17,30,25,23,5}
{5,9,17,21,23,25,30}
题目解答
答案
B ) 问题求步骤的描述 D) 决问题的有限运算序列。 B) 逻辑结构 C) 线性结构、非线性结构 D )一个逻辑数据结构可以有多种存储结构,且各种存储结构影响数据处理的效率 A) 数据项 D ) a,e,d,f,c,b B) 拓扑[7]排序 B) 中根 B) O(n+e) A) V 1 ,V 3 ,V 4 ,V 6 ,V 2 ,V 5 ,V 7 从源点到汇点的最长路径 C) n(n-1) B) 5 A) 1/2 B) 1 B) 1 B) 28 C) 7 C) 56 B) 队列 A) 栈 C) 0 4 2 3 1 6 5 D) 建议: 0 1 3 4 2 5 6 D) 0 1 3 4 2 5 6 B) 0 1 3 6 4 2 5 (建议: 0 1 2 3 4 5 6 ) D) 0 1 2 3 A) 0 3 2 1 A) 先序遍历 D) 层次遍历[8] A) 只有一棵 (注,生成树[9]不唯一,但最小生成树[10]唯一,即边权之和或树权最小的情况唯一) D) Li B) 63.5 B) 其形态不一定相同,平均查找长度[11]也不一定相同 C) 平均查找长度 C) 二叉排序树 A) 顺序方式存储 , 且元素按关键字有序 D) (19,23,67,56,34,78,92,88) D) 快速排序[12] C) 40,38,46,56,79,84 B) O(n 2 ) D) 快速排序 C) 快速排序 C) 10 D) 插入排序[13] C) 堆排序[14] 插入排序 D) 选择排序[15] B) 从大到小排列好的 D) n(n-1)/2 C) 被排序的数据完全无序 B) O(n 2 ) 40, 38 , 46, 56, 79, 84 D) 16, 23, 53, 31, 94, 72 B) 选择 C) 完全二叉树[16] B) 84, 79, 56, 38, 40, 46 C) 归并排序